BuzutKeep updated2024-09-05T06:56:59.840Zhttps://buzut.net/BuzutHexoOrganiser la connaissancehttps://buzut.net/organisation-de-connaissance/2024-06-10T06:00:46.000Z2024-09-05T06:56:59.840ZÇa fait déjà trois ans que je n’ai pas publié ici… cela m’amène à réfléchir aux lacunes du blog pour l’organisation de la connaissance et aux apport des bases de connaissances.
Je pense qu’il est inutile de présenter Wikipedia, l’encyclopédie libre en ligne. Au delà de sa gratuité, quatre choses la caractérise :
elle est participative,
elle est simple de navigation,
elle traite de tous les sujets,
elle repose sur un logiciel open source.
Partant de ce principe, pourquoi n’y a-t-il pas une adoption plus importante du wiki au lieu du blog ?
Un peu de contexte
MTO, ma nouvelle activité, comporte une partie informatique puisqu’il s’agit d’un e-commerce mais aussi et surtout une énorme partie d’ingénierie électrique et mécanique puisque nous concevons des pièces (batteries, pièces plastiques, pièces d’usinage…).
Évidemment, je suis derrière la partie ingénierie et comme dans tout domaine, on se forme sans cesse. D’où cette réflexion : la nature chronologique et thématique du blog n’est-elle pas un frein à l’organisation pérenne de la connaissance ?
Comme l’équipe grandit chez MTO, j’avais un besoin d’organiser les process et données de la société. Il me fallait une documentation bien organisée que chacun puisse consulter, chaque équipe traitant de sujets très différents (documentation d’assemblage de nos pièces, référence des matériaux, process d’assemblage des batteries…)
Le blog ne me semblait pas du tout adapté, et en recherchant des solutions plus proches de mes besoins, qu’elles en adoptent le nom ou pas (knowledge base), toutes semblaient être des sortes de Wiki.
Limite du blog
Premièrement, un blog est thématique, celui-ci, dédié à l’informatique, serait dénaturé si je commençais à y poster des articles sur l’électronique ou la science des matériaux.
Deuxièmement, un blog est chronologique, mis à part la barre de recherche ou les moteurs de recherche, le contenu ancien est difficile d’accès via la navigation du site.
Ceci s’explique par la nature du blog. Comme son nom l’indique, le blog, diminutif de web log, est destiné à publier des informations de manière chronologique sur un sujet donné, c’est un journal.
Un journal, qu’il soit de bord, de voyage ou de politique, traite d’un sujet thématique et n’a pas une vocation prioritaire à être actualisé une fois l’article publié.
La connaissance, elle, est évolutive, doit être maintenue à jour (évolution de l’état de l’art, de la technologie…) et on doit pouvoir facilement et rapidement s’y frayer un chemin.
Ces problèmes ne sont pas des défauts de l’outil “blog”, ce sont des signes que l’outil est inadapté à une tâche. Le log a été précurseur dans la démocratisation de la publication de contenu, cependant, comme chaque outil à la mode, il a été adopté de manière abusive.
On suit de très nombreux blogs dans des domaines variés, néanmoins, lorsque l’on recherche une source de référence, qu’il s’agisse de Wikipedia, du MDN ou d’une documentation officielle, cela prend presque toujours la forme d’une base de connaissance ou d’un wiki (c’est un peu la même chose).
La knowledge base
Le propre du Wiki est q’il est collaboratif, je fais donc un abus de langage en utilisant ce terme, car le but recherché ici n’est pas forcément la collaboration, mais la gestion de la connaissance.
Cependant, un Wiki est juste un type particulier de base de connaissance. On peut utiliser ou non la partie collaborative et tous les outils commerciaux (Atlassian, Zendesk…) proposent la collaboration.
La connaissance est néenmoins tellement précieuse qu’il vaut mieux s’attacher à la garder ouverte et portable. Je n’ai rien contre les outils commerciaux, mais si la source est fermée et que vos besoins évoluent, mieux vaut un logiciel vous permettant de facilement tout exporter et transférer ailleurs.
D’ailleurs, le bon compromis si vous ne voulez pas vous encombrer d’héberger et de gérer votre knowledge base, c’est d’opter pour la version hébergée d’une solution open source !
Les solutions open source
Je ne vais pas ici vous faire une liste exhaustive de tous les projets, il y en a de nombreux. Premièrement, si vous hébergez vous-même l’outil, c’est un plus d’en choisir un dans une technologie que vous maitrisez.
Dans mon cas, j’ai donc limité mes recherches aux langages PHP et Node.js, mais sachez qu’il en existe dans la plupart des langages web. En ce limitant à ces deux langages, on a déjà pas mal d’options.
Il ne nous reste plus qu’à faire notre choix en fonction des fonctions offertes par les différentes solutions ainsi qu’en fonction du look & feel. Autant que possible, on doit avoir du plaisir à écrire et à lire la documentation !
Solutions PHP
L’avantage du PHP c’est qu’on que c’est supporté absolument partout dans la mesure où le projet ne requiert pas des lib exotiques. Un plan mutualisé à 3€ peut faire l’affaire.
MediaWiki le logiciel derrière Wikipedia. Il a été développé en 2002 par des scientifiques et est surement à ce jour le logiciel le plus utilisé au monde pour les sites de gestion de connaissance. Il utilise MySQL, a un riche écocystème de plugins, dispose d’une documentation complète, adopte la syntaxe de Wikipedia (ou plutôt le contraire) et est disponible dans presque toutes les langues.
DokuWiki est ultra léger, ne nécessite pas de base de données, offre une recherche fulltext, dispose de nombreux thèmes, supporte plus de 50 langues, offre un système de contrôle d’accès ACL, possède un riche système d’extensions et adopte une syntaxe simple dérivée de Wikipedia.
BookStack offre une interface épurée, propose un thème classique et un sombre au choix de l’utilisateur, supporte de nombreuses langues, permet la rédaction Markdown ou WYSIWYG, supporte les diagrams.net et offre un système de commentaires. Il est basé sur MySQL, offre la recherche et intègre diverses méthodes d’authentification (GitHub, Google, LDAP…). C’est mon choix pour ma documentation personnelle car BookStack adopte une catégorisation originale : le contenu est organisé en rayons, livres, chapitres et pages.
Solutions NodeJS
Les solutions NodeJS sont légèrement plus complexes à héberger. En contreprtie, elles sont puissantes et plutôt orientées entreprise (ou pour un particulier avec des besoins avancés).
Wiki.js est une solution Wiki puissante à l’interface épurée qui permet la rédaction Markdown ou WYSIWYG. Conçue pour les entreprises (mais pas que), elle supporte PostgreSQL, MySQL, MS SQL et SQLite. Le logiciel supporte un grand nombre de méthodes d’authentification, offre un système avancé de gestion des droits, permet en option de confier la recherche à des moteurs spécialisés (Elastic, Algolia…) et offre un système de commentaires. C’est mon choix pour la documentation de MTO.
Outline s’adresse aussi aux équipes avec une interface très léchée et dispose d’une offre hébergée cloud. Pour l’installation auto-hébergée, il faut Postgres et Redis. La rédaction se fait en Markdown et on note la possibilité de rédiger en direct de manière collaborative. Outline offre aussi une totale intégration avec Slack, le multilangue, un système de commentaires et propose des applications natives (iOS, Android, Windows & macOS).
De nouveau, comme dit en introduction, ce n’est pas une liste exhaustive. Il s’agit plutôt d’un compte rendu des solutions notables que j’ai considéré pour mes propres besoins. Cela étant dit, à moins que vous cherchiez une solution dans un language de programmation spécifique, vous devriez avoir ici l’ensemble des outils pouvant répondre à vos besoins.
Le blog est-il donc terminé ? Évidemment non ! Le blog et le Wiki coexistent, le blog est le meilleur des outils pour véhiculer des opinions ou des retours d’expérience par exemple. Je continuerai donc à me servir de ce blog pour partager mes opinions, mes expériences et partis-pris sur des sujets de dev.
]]>
Alors que le blog est souvent choisi pour publier et organiser ses connaissance, découvrons la force du Wiki.
Les CHMOD pour l'hébergement internethttps://buzut.net/les-chmod-pour-lhebergement-internet/2021-05-24T06:28:59.000Z2024-09-05T06:56:59.836ZLes CHMOD, ça parait simple et complexe à la fois. D’ailleurs, la plupart du temps, les développeurs s’en préoccupent peu, ou pas du tout. Pourtant, une mauvaise configuration peut faire survenir des bugs dans de nombreuses applications. Plus grave, cette mauvaise configuration ne garantie pas une sécurité optimale et peut faciliter le hack de votre site et l’intrusion dans vos serveurs. Faisons donc un petit tour des bonnes pratiques.
Petit rappel sur les chmod
Révisons rapidement les chmod pour bien commencer, on a trois types de permissions, lesquelles peuvent être notées de manières symboliques par x (execute), w (write) ou r (read), ou de manière octale, respectivement 1, 2 et 4. Ces droits sont applicables aux fichiers comme aux répertoires :
le droit d’exécution, noté x ou 1 ; appliqué à un fichier, il permet de l’exécuter (exécutable unix par exemple), pour les répertoires, ce droit permet d’entrer dans le répertoire, et par conséquent, s’il n’est pas accordé, empêche de lister son contenu ;
le droit d’écriture, noté w ou 2 ; il permet de modifier le fichier, ou pour un répertoire, d’en modifier le contenu (ajout/suppression de fichiers) ;
le droit de lecture, noté r ou 4 ; il permet de lire le contenu d’un fichier, ou appliqué à un répertoire, d’en lister le contenu.
De plus, il faut savoir que ces droits s’appliquent à trois types d’utilisateurs :
le propriétaire du fichier (nommé user, noté u) ;
le groupe, concerne tous les autres membres du groupe (un groupe peut rassembler plusieurs utilisateurs, il est nommé group, noté g) ;
tous, concerne tous les utilisateurs (nommé others, noté o).
Voici un petit tableau récapitulatif :
Droits
Chiffre
Calcul
—
0
0 + 0 + 0
r–
4
4 + 0 + 0
-w-
2
0 + 2 + 0
–x
1
0 + 0 + 1
rw-
6
4 + 2 + 0
-wx
3
0 + 2 + 1
r-x
5
4 + 0 + 1
rwx
7
4 + 2 + 1
Les bons réglages pour l’hébergement
On doit maintenant se poser la question des chmod à attribuer à nos fichiers pour être dans des conditions de sécurité acceptables. Le mieux, c’est de tout mettre à 777…
Vous l’aurez donc compris, le conseil du chmod 777, c’était une boutade.
Par défaut, les répertoires sont en général à 755 – ce qui autorise tout pour le propriétaire du fichier (premier chiffre), donne le droit à la lecture et à l’exécution (listage dans le cas des répertoires) pour les autres (4+1 pour le groupe [second chiffre] et les autres [troisième chiffre]) – et les fichiers à 644 – autorise la lecture et l’écriture pour le propriétaire (4+2) et la lecture uniquement pour les autres.
Le white listing
La meilleur politique consiste, comme toujours en sécurité informatique, à ne rien autoriser mis à part ce qui est nécessaire. Vous pouvez donc limiter les autorisations à 555 (lecture et listage) pour les répertoires n’ayant pas de contenu ayant vocation à changer. Typiquement un répertoire contenant des images ou des fichiers HTML et/ou PHP. En ce qui concerne les fichiers, 444 (lecture seule) suffira pour leur majorité, tels que les images, les fichiers HTML, CSS, JavaScript, PHP…
Moteur PHP
Au cas où vous vous posiez la question : non, les fichiers PHP n’ont pas besoin d’être exécutable. C’est en effet le moteur PHP qui lit leur contenu et les exécute, mais ils ne sont pas eux-même des exécutables (la plupart du temps).
Vous modifierez au cas par cas les droits des fichiers et des répertoires s’ils ont besoin de droits supplémentaires. Par exemple dans le cas d’un exécutable, il faudra au moins lui donner le droit d’exécution en plus de celui de lecture, donc 555 (ou 550 celon l’utilisateur qui lance l’exécutable).
De même, en ce qui concerne les fichiers de logs, n’oubliez pas de leur accorder le droit en écriture, sans quoi il ne loggeront pas grand chose… Concernant les répertoires, il faudra donner le droit d’écriture au propriétaire si le répertoire reçoit des uploads ou si PHP créé de nouveaux fichiers à l’intérieur par exemple, donc droits à 755.
Propriétaire, groupe et autres…
On parle depuis tout à l’heure de permissions accordées à trois niveaux d’utilisateurs. Cela implique, vous l’avez compris, qu’il est d’une part important de bien configurer les droits, mais d’autre part, qu’il faut aussi veiller à ne pas mettre n’importe quel utilisateur en tant que propriétaire !
En effet, la plupart du temps, le propriétaire a 7 (tous les droits), donc si votre propriétaire est le serveur, Apache par exemple (en général c’est l’utilisateur www-data sur les Debian et dérivés), il pourra facilement modifier vos fichiers et cela facilitera grandement le travail d’un attaquant ayant trouvé une faille sur votre serveur.
Plusieurs politiques peuvent donc être mises en place. La plupart du temps, le propriétaire des répertoires et fichiers est un utilisateur distinct des processus Apache (ou autre serveur) et appartenant aussi à un autre groupe (www-data est aussi le groupe correspondant au processus Apache). Par exemple l’utilisateur Linux sous lequel est loggué le développeur.
On peut déclarer root comme propriétaire, seul root aura donc les droits de propriétaire (root a de toute façon déjà tous les droits sur l’ensemble des répertoires du serveur). Il faudra alors être root pour faire ce que les autres et/ou le groupe n’ont pas le droit de faire.
On peut aussi n’accorder que des droits succins au propriétaire – les mêmes que ceux des “autres” – dans ce cas, il faudra passer en root pour éditer, supprimer etc, le fichier/répertoire.
J’ai parlé ici des utilisateurs, mais la même logique s’applique bien entendu aux groupes, bien qu’ils ne soient souvent pas pris en compte dans l’hébergement, ne laissez pas à un groupe (www-data au hasard) la possibilité de faire n’importe quoi !
Pour toutes les commandes relatives à l’administration des droits, des utilisateurs et des groupes, je vous recommande mon article sur l’administration des systèmes Linux.
J’espère que ce petit article aura su vous éclairer sur la gestion des droits pour votre hébergement ! N’hésitez pas à me signaler toute erreur ou omission.
]]>
Les CHMOD définissent les droits des dossiers et fichiers sur les systèmes Linux. Leur mauvaise configuration facilite grandement la prise de contrôle d'un site par un pirate. Il est donc essentiel de bien les configurer.
Gérer les encodages de texte en JavaScripthttps://buzut.net/gerer-les-encodages-de-texte-en-javascript/2021-02-12T09:00:00.000Z2024-09-05T06:56:59.836ZL’encodage du texte a toujours été plus complexe qu’il ne parait. ASCII, Latin 1, Mac OS Roman, ISO 8850-n, UTF-8… On a tendance à s’y perdre. J’y dédis un article de mon livre Computer Science.
Cette complexité est sans compter le fait que différents langages de programmation gèrent ces encodages différemment. Vous êtes un développeur moderne, vous vous dites peut-être que de nos jours, tout se passe en UTF-8 et qu’il est inutile de s’appesantir sur le sujet ? Grossière erreur !
Vous connaissez le JavaScript. On utilise la méthode length pour récupérer la longueur d’une chaine de caractère. Essayez donc '🤔'.length. Si vous pensiez à 1, vous êtes dans l’erreur.
Par ailleurs, saviez-vous que 'A' !== 'А' ? Oui Monsieur, parfaitement ! Le premier est le “a” majuscule latin tandis que le second est en cyrillique. Une vérification sans considération des noms d’utilisateurs d’un site par exemple, peut vite poser problème…
Et vous n’avez encore rien vu ! Convaincu de l’utilité de faire le tour de la question ? Allez, on se lance !
C’est certain, lorsque l’on fait du web, en ne s’encombre que très rarement de ces considérations. Tout est édité en UTF-8, tout est sauvegardé en UTF-8 et tout est rendu sur les pages en UTF-8. Pas problème.
Cet article plonge dans le détail de la gestion des encodages en JavaScript. Aussi, si les plans Unicode, la BMP ou les différents UTF-n sont des notions obscures pour vous, vous devriez lire rapidement le chapitre dédié à ce sujet de mon livre Computer Science.
Compter les caractères
On a vu en exemple que length ne tombe pas juste avec les Emojis. Il n’y a pas qu’eux. Cela vient du fait que length ne compte pas comme nous. Pour nous, '🤔'.length devrait faire 1 car “🤔” constitue un glyphe unique.
En JavaScript, les chaînes de caractères sont encodées en UTF-16, donc sur deux octets. Ainsi, pour length, tout ce qui fait deux octets ou moins est considéré comme de longueur 1, car cela constitue un mot UTF-16. Cependant, pour les caractères moins courants, ceux qui ne sont pas dans la table BMP, il faudra plusieurs octets pour les encoder, et c’est précisément le nombre de mots UTF-16 que nous retourne length.
De manière assez simple, si l’on veut que JavaScript compte “correctement” le nombre de glyphes, il faut utiliser l’itérateur de String.
Array.from('🤔').length // 1
Voilà qui résout nos problèmes ! En résumé length compte le nombre de mots UTF-16 tandis que l’itérateur compte le nombre de points de code.
L’habit ne fait pas le moine
Comme le dit le proverbe, on ne peut se fier aux apparences ! Deux caractères visuellement identiques peuvent être différents, par exemple ê !== ê. Nous sommes cette fois-ci en présence du caractère Latin Small Letter E with Circumflex pour le premier mais d’un ensemble de deux caractères pour le second :
Latin Small Letter E –> e
Combining Circumflex Accent –> ̂
Malheureusement, cette fois, le String iterator ne viendra pas à notre secours.
Array.from('ê').length // 2
😭 ! C’est le cas de le dire 😝
Que pouvons-nous faire ? Si vous avez lu mon article sur Unicode, vous n’êtes pas sans savoir que le standard Unicode propose une notion d’équivalence afin de savoir si, quand bien même deux caractères sont différents, on peut les considérer comme équivalents.
C’est en effet le cas de l’exemple précédent. On pourrait pratiquement être tenté de penser qu’une comparaison sans vérification de type fonctionne :
* ê !== ê // false* ê != ê // true
Ça n’est pas le cas, mais c’est un peu l’idée. Unicode fournit deux notions d’équivalence.
L’équivalence canonique signifie que deux caractères sont équivalents visuellement et sémantiquement parfaitement identiques. C’est le cas de notre exemple. Ainsi, tout caractère pré-composé est canoniquement équivalent à sa forme composée.
L’équivalence de compatibilité est moins stricte mais permet d’effectuer des comparaisons, notamment en permettant l’usage de jeux de caractères plus restreints. Cela permettra par exemple de comparer les ligatures à leur équivalent non-lié (“…” à “…”), ou encore les chiffres en indice ou exposant à la version normale…
L’équivalence canonique est un sous-ensemble plus strict de l’équivalence de compatibilité. Par conséquent, toute séquence canonique est aussi compatible.
Pour comparaison, Unicode définit quatre formes normales, deux sont des formes canoniques (NFx) et deux sont des formes de compatibilité (NFKxx), chacune d’elle offrant la forme composée et la pré-composée.
NFD
Normalization Form Canonical Decomposition. Les caractères sont convertis dans leur équivalent composé.
NFC
Normalization Form Canonical Composition. C'est l'inverse de la précédente, les caractères sont convertis dans leur équivalent pré-composé.
NFKD
Normalization Form Compatibility Decomposition. Les caractères sont décomposés par équivalence canonique et de compatibilité, et sont réordonnés.
NFKC
Normalization Form Compatibility Composition. Les caractères sont décomposés par équivalence canonique et de compatibilité, sont réordonnés et sont composés par équivalence canonique.
La normalisation nous permet de trier, rechercher et comparer. Elle offre donc de grands services.
Quand y’a problème
La normalisation nous rend de bons services… mais elle ne résout pas tout non plus. Quelle que soit la normalisation utilisée, certains caractères proches, visuellement ou sémantiquement, ne sont pas compatibles.
En exemple, nous pouvons citer des lettres similaires d’alphabets différents, A !== А ; certaines ligatures œ !== oe mais encore des signes enregistrés comme points de code différents pour des raisons variées α !== ⍺.
Dans ce dernier exemple, nous sommes en présence de la lettre grecque alpha (U+03B1) pour le premier, et du signe mathématiques alpha (U+237A) pour le second.
C’est un peu la jungle car bien que le signe Micro “μ” (U+03B5) ne soit pas égal à la lettre grecque Mu “µ” (U+03BC), elle est équivalente, mais ceci n’est pas vrai pour les deux alpha.
Cette règle est dûe au fait que le signe Micro était déjà présent dans la table Latin-1, tandis que dans ce jeux de caractère, alpha n’était pas une option, version grecque ou scientifique.
Pour palier à ces problèmes, le groupe Unicode publie une table des signes qui peuvent être confondus. C’est assez fastidieu à gérer manuellement, nous en conviendrons.
Il existe donc un module JavaScript qui reprend la table en question et nous offre une fonction de comparaison. Tous les signes sont listés dans le fichier chars du code source. À titre d’exemple, voici la ligne 67, des “a”, .
aɑαа⍺a𝐚𝑎𝒂𝒶𝓪𝔞𝕒𝖆𝖺𝗮𝘢𝙖𝚊𝛂𝛼𝜶𝝰𝞪
Rien d’extrêmement complexe en soit, mais nous sommes fort reconnaissants à ce module de nous dispenser de cette fastidieuse tâche. Il n’est pas conçu pour directement comparer deux lettres, mais pour vérifier sur une chaîne n’est pas semblable à ensemble d’autres chaînes de caractères.
Quoi qu’il en soit, gardez à l’esprit que vous ne pourrez jamais être sur à 100% de votre comptage et de vos comparaisons. D’autant plus avec le système combinatoire de l’Unicode.
Il est quasi certain que ces deux glyphes s’affichent de manière identique sur votre système. Ils sont pourtant composés de manière différente. Autant donc se résigner et accepter que tout n’est pas sous votre contrôle.
Représenter un caractère en JavaScript
Vous le savez peut-être, mais nous avons plusieurs moyens de représenter un caractère en JavaScript. La manière de faire la plus courante est de simplement utiliser la séquence d’octets du caractère. Cette manière est totalement transparente pour nous car il suffit d’entrer le caractère souhaité.
L’autre façon est d’utiliser une séquence d’échappement. Le JavaScript en compte quatre :
séquence octale,
séquence hexadécimale,
séquence Unicode,
séquence points de code Unicode.
Quelles différences ? Les deux premières permettent de représenter les 256 caractères de la table ASCII, mais l’octale est dépréciée en faveur de l’hexadécimale. Prenons “@” comme exemple. Un rapide coup d’œil à la table ASCII nous apprends que “@” porte le point de code 64. Soit 100 en octal et 40 en hexadécimal.
// Les séquences octales comportent de 2 à 4 caractères// Il est possible de forcer 4 caractères par des zéro à gauche// Cela permet d'éviter des confusion si plusieurs séquences se suiventconsole.log('\100'); // @// Les séquences hexadécimales sont toujours de quatre caractères// Elle commence toujours par "x" pour hexaconsole.log('\x64'); // @
Ces deux premières séquences sont assez peu utilisées car assez limitantes. Les deux autres options offrent bien plus de possibilités. La séquence Unicode reprend l’encodage UTF-16. Il est donc possible de représenter tous les caractères de la BMP avec une séquence, et les autres caractères en combinant deux séquences avec le mécanisme de surrogate pairs de l’UTF-16.
Les séquences de points de code Unicode permettent, quant à elles, de représenter tout caractère de la table directement grâce à son numéro Unicode.
Voyons maintenant d’autres exemples avec un caractère plus cool : 😎
// Utilise directement la séquence d'octetsconsole.log('😎'); // 😎// Séquence Unicode UTF-16,// on utilise ici le mécanisme de surrogate pour les caractères nécessitant plus de deux octetsconsole.log('\uD83D\uDE0E'); // 😎// On précise ici le numéro unicode directement entre \u{UNICODE_NUMBER}console.log('\u{1F60E}'); // 😎
Dans ces deux derniers encodages, vous avez certainement noté que nous avons le “u” signifiant unicode. Dans les cas où le caractère représenté est dans la BMP, les deux séquences seront très similaires car le numéro Unicode est égal à son encodage UTF-16. Reprenons notre exemple précédent.
// Séquence hexadécimaleconsole.log('\x40'); // @// Séquence Unicode hexa/UTF-16, longueur fixe de 6 caractèresconsole.log('\u0040'); // @// Séquence numéro de code Unicode// La taille est ici variable, les zéro non-significatifs sont facultatifsconsole.log('\u{40}'); // @
Créer un caractère à partir de points de code
Pour créer un ou des caractères à partir d’un ou plusieurs points de code, nous avons deux méthodes à notre disposition :
String.fromCharCode permet de créer un ou plusieurs caractères à partir d’un point ou suite de points UTF-16
String.fromCodePoint permet de créer un ou plusieurs caractères à partir d’un point ou suite de point Unicode.
La seconde méthode est un apport de l’ES6. La majeure différence entre les deux est que fromCodePoint permet de créer des caractères n’appartenant pas à la BMP directement à partir de leur point de code Unicode. fromCodePoint devra obligatoirement recourir aux surrogate pairs pour représenter des caractères hors de la BMP.
Il s’agit là de l’opération inverse de la précédente. Nous avons également deux méthodes nous permettant d’effectuer cette action :
charCodeAt retourne un entier (décimal) compris entre 0 et 65535 qui correspond au code UTF-16 d’un caractère de la chaîne situé à une position donnée.
codePointAt retourne un entier (décimal) qui correspond au code Unicode du caractère de la chaîne à la position donnée.
De même que fromCodePoint, codePointAt est un ajout de l’ES6. Il prend donc en charge l’Unicode tandis que charCodeAt ne retournera que le point de code correspondant à une des surrogates s’il s’agit d’un caractère n’appartenant pas à la BMP.
Vous notez par ailleurs que ces deux méthodes retournent les points de code en décimal. On travaille le plus couramment en hexa, on utilisera donc toString pour immédiatement récupérer les valeurs en hexa.
// Le résultat retourné est le même avec des caractères de la BMPconsole.log('😎'.charCodeAt('@').toString(16)); // 40console.log('😎'.codePointAt('@').toString(16)); // 40// On récupère ici le premier surrogateconsole.log('😎'.charCodeAt('0').toString(16)); // d83d// Et le second à l'index 1, le caractère encodé en UTF-16 est bien D83D DE0Econsole.log('😎'.charCodeAt('0').toString(16)); // de0e// Ici on obtient directement le point de code Unicode du caractèreconsole.log('😎'.codePointAt('0').toString(16)); // 1f60e
Naviguer entre les encodages
Il y a quelques temps, j’ai travaillé sur une API de SMS marketing. Vous l’ignorez peut-être, mais lorsque le SMS a été inventé, l’UTF-8 n’était pas encore trop à la mode, et il ne l’est toujours pas dans le monde du SMS. En front, vous travaillez donc en UTF-8, vous devez quand-même gérer le comptage des caractères et encoder le tout en back…
Sans oublier que vous recevez aussi des SMS. Vous devez interpréter l’encodage, le convertir en UTF-8 avant de le stocker et de l’afficher. C’est là qu’on réalise tout l’intérêt de maîtriser un minimum le sujet.
Encodage des SMS
Dans le monde du SMS, aujourd'hui encore, la table d'encodage la table GSM-7.
Dans cette table, tout est encodé sur 7 bits, comme au tout début de l’ASCII. Nous sommes d’accord, cela ne fait pas beaucoup de caractères. C’est pourquoi il est possible pour les téléphones modernes d’utiliser l’UCS-2. Ce dernier est un encodage de longueur fixe sur deux octets.
Il est le premier à avoir été normalisé par le consortium Unicode. L’UCS-2 est aujourd’hui déprécié et n’est plus en usage en dehors de la téléphonie. L’inconvénient de UCS-2 est que chaque caractère est encodé sur deux octets, donc cela prend nettement plus d’espace. Par ailleurs, il ne permet de représenter que les 65k caractères de la BMP, ce qui est aujourd’hui restrictif.
Malgré cela, vous réalisez que vous et moi, envoyons et recevons constamment des messages avec des caractères en dehors de la BMP : nos fameux Emojis qui font bien plus de deux octets ! L’UCS-2 est un sous-ensemble de l’UTF-16BE.
En pratique, l’UCS-2 est très peu supporté. Ainsi, côté logiciel, tous les smartphones décodent les SMS UCS-2 avec l’algorithme UTF-16. De ce fait, tout UCS-2 valide est décodé correctement, mais c’est aussi le cas de messages encodés en UTF-16, bien que techniquement, ils ne respectent pas le standard.
Le problème est posé. On doit compter correctement le nombre de caractères, jongler entre plusieurs encodages, envoyer dans un encodage mais stocker dans un autre. À tout cela s’ajoute une doc lacunaire quand elle n’est pas tout bonnement fausse !
Premier contact
Je n’y connais alors rien au standard SMS et je lis machinalement la doc de la société qui fait transiter nos SMS. La doc mentionne le fait que la table est retreinte, mais explique qu’il est possible “d’encoder en Unicode”.
L’élément <binary> est utilisé pour le contenu du message à la place de l’élément <text> dans le cas où le message doit être envoyé en unicode.
<binary> peut avoir un attribut unicode unicode="1" qui précise que les octets dans le champ binary sont codés sous le forme hh : Le caractère Q est par exemple codé 0051 (en Unicode un caractère est codé sur 2 octets) unicode="2" qui précise que les octets dans le champ binary sont codés sous le forme %hh : Le caractère Q est par exemple codé %00%51 (en Unicode un caractère est codé sur 2 octets)
Tout va bien, Unicode est un encodage qui fonctionne sur deux octets. Les mecs connaissent leur sujet 🤣
Fort heureusement, un petit tour sur la Unicode table nous apprend que “Q” vaut 0051 quand il est encodé en UTF-16BE. Ça tombe bien, ça matche avec l’UCS-2.
On a plus loin un autre exemple :
Que je m’aime ! 😂 Encodé en Unicode binary 0051007500650020006a00650020006d002700610069006d0065002000210020d83dde02
Oui, vous remarquez qu’on a une chaîne de caractère “binaire” qui contient en fait de l’hexa. Le binaire ne contient que des 0 et des 1, comme chacun sait. Donc la chaîne en question encodée en UTF-16BE et représentée en binaire, ça donne plutôt ça.
Le décor est planté : on est face à un sujet pas évident et rien d’autre pour nous épauler qu’une doc d’amateur écrite par une personne pas très au fait des standards.
Grâce aux deux exemples, on sait néanmoins que si on sort de la table GSM, on peut compter sur l’UTF-16 – et pas l’UCS-2 – car il nous est possible d’utiliser des Emojis. L’UCS-2 nous limiterait à la BMP, et nous priverait de nos chers Emojis. On sait dès lors que l’on peut encoder tous les caractères Unicode.
Cela mène cependant à un nouveau détail. La doc nous affirme que “en Unicode un caractère est codé sur 2 octets”. De nouveau, on flaire l’ignorance du rédacteur de la documentation. En effet, si “Q” est bien encodé sur deux octets (00 51), “🤣” en requiert déjà quatre (D8 3D DE 02), soit deux mots UTF-16. Ce que nous confirme notre length favori.
'🤣'.length // 2
Deux points de code de deux octets chacun : 2 x 2 = 4. Tout caractère n’est donc pas en “Unicode” encodé sur deux octets. Ou alors, il faut redéfinir le terme octet !
On sait donc qu’à défaut de pouvoir faire confiance à la doc, on peut compter sur length pour évaluer le nombre de “caractères” que contient un SMS. Profitons-en d’ailleurs pour un nouvel exercice de comptage.
'👨👩👧👦'.length // 11
Avec une confusion entre point de code et caractère, on comprend rapidement que la factuaration risque d’être sport, mais c’est un autre débat…
Ce que l’on sait de manière certaine, c’est que cette chimère encodée sur deux octets est de l’UTF-16BE. De ce fait, le comptage des caractères peut s’effectuer directement en front, c’est assez simple.
On se constitue un array avec tous les caractères valides dans la table GSM.
On normalise le texte entré en NFD. Ainsi tous les caractères sont dans leur forme composée, moins de caractères à envoyer et plus de chance de matcher la table GSM.
Si tout matche, chaque caractère compte pour 1 et le SMS peut contenir 160 caractères. Sinon, on encode en UCS-2/UTF-16 et le SMS ne peut plus contenir que 70 caractères (ils sont encodés sur 16 bits et non plus 7).
Si le SMS dépasse le nombre de caractères que peut contenir un seul message, on utilise un User Data Header spécifiant que le message est composé de plusieurs segments. Ce header prend de la place, ainsi, il ne nous reste plus que 153 caractères par message en encodage GSM et 67 en UCS.
const maxGSMChars = 160;const maxUCSChars = 70;const multiSegmentGSMChars = 153const multiSegmentUCSChars = 67// On normalise l'inputconst normalisedMsg = inputMsg.normalize('NFD');// Notre fonction vérifie si tous les caractères contenus dans normalisedMsg appartiennent à la table GSM// elle retourne un boolconst encodingType = checkGSMCompatibility(normalisedMsg) ? 'GSM' : 'UCS';// Dans les deux cas, String.length correspond maintenant à notre définition de longueur de caractèrelet numberOfSegments;if ( (encodingType === 'GSM' && normalisedMsg.length <= maxCharsPerMsg) || (encodingType === 'GSM' && normalisedMsg.length <= maxCharsPerMsg) ) { numberOfSegments = 1;}else { const charsPerSegment = encodingType === 'GSM' ? multiSegmentGSMChars : multiSegmentUCSChars; numberOfSegments = normalisedMsg.length / charsPerSegment;}
Transcoding
Le front a fait son boulot et il n’est pas démesurément complexe. Côté back, nous avons un peu de pain sur la planche.
Premièrement, on peut réutiliser l’algo précédent pour vérifier si oui ou non, le texte du SMS peut être envoyé en mode texte directement avec la table GSM. Si oui, nous communiquons le texte à l’API de l’opérateur sans autre forme de procès.
Bien qu’il en soit proche, le texte ainsi envoyé n’est pas dans l’encodage de la table GSM à proprement parler, il est en UTF-8 (car c’est dans cet encodage que nous avons receuillis les données sur notre page web).
Vous le savez peut-être (si vous avez vu mon le chapitre sur Unicode de mon livre ), l’UTF-8 est rétro-compatible avec l’ASCII. Donc tout texte ASCII est un texte UTF-8 valide.
Bien que très proche de l’ASCII, la table GSM n’est pas exactement la même. Ce n’est pas à nous de nous occuper de cette conversion, mais si cela avait été le cas, il aurait simplement fallu réencoder quelques caractères. Le “@” a par exemple comme valeur 40 en ASCII et 00 en GSM 03.38.
Encoder en UTF-16
Le plus gros du travail consistera à encoder les messages qui doivent être envoyés en UTF-16. Notre texte est en interne stocké en UTF-16 par JavaScript, mais nous travaillons avec des séquences d’octets de manière totalement transparente. Il va falloir forcer la conversion en UTF-16 et récupérer une représentation en hexa.
Les différentes méthodes que nous avons précédemment vu nous permettent d’effectuer cette conversion sans aucune difficulté.
function encodeToUTF16(message) { // On procède octet par octet return message.split('').map((char) => { // Pour chaque octet, on récupère sont point de code const word = char.codePointAt(0).toString(16); // Si le point de code ne fait qu'un seul octet, on ajoute des 0 // Ceci permet d'obtenir la longueur fixe de l'UTF-16 if (word.length === 2) return `00${word}`; return word; }) .join('');}
On utilise ici codePointAt mais on pourrait tout aussi bien utiliser charCodeAt étant donné que l’on itère octet par octet et non par point de code Unicode.
Décoder du Latin-1 URL encoded
Là vous vous dites très certainement quelque-chose dans le genre de WTF. Celui-ci est pour le lulz.
En effet, lorsqu’un SMS envoyé reçoit une réponse, celle-ci nous est retournée sur un endpoint de notre choix, via une requête GET. POST aurait été plus indiqué, mais pour une raison que j’ignore c’est du GET et tout est passé en paramètre de l’URL.
// On a donc un endoint appelé de la sorte/sms/response/?FROM=tel&MESSAGE=msg&RET_ID=campaignId
Rien de bien sorcier pensez-vous. Cependant, msg peut contenir toute sorte de caractères. C’est un SMS, il est donc en théorie soit au format GSM, soit en UCS-2… Néanmoins, comme les données ne sont pas envoyés en POST mais passées directement en paramètres, il n’est pas possible de spécifier l’encodage utilisé.
La RFC3986 précise que pour les URL, tout caractère réservé ou qui sort de la table ASCII doit être encodé en UTF-8 puis mis au format URL.
When a new URI scheme defines a component that represents textual data consisting of characters from the Universal Character Set [UCS], the data should first be encoded as octets according to the UTF-8 character encoding [STD63]; then only those octets that do not correspond to characters in the unreserved set should be percent- encoded. For example, the character A would be represented as “A”, the character LATIN CAPITAL LETTER A WITH GRAVE would be represented as “%C3%80”, and the character KATAKANA LETTER A would be represented as “%E3%82%A2”.
L’URL encoding est assez simple, tout caractère réservé ou qui n’est pas ASCII, est représenté par la valeur de l’octet en hexadécimal. Bien entendu, cette valeur varie selon l’encodage utilisé. C’est pourquoi, comme il n’y a pas moyen de savoir quel encodage est utilisé, le standard dit de toujours les considérer comme étant de l’UTF-8.
La valeur de “😎” est bien F0 9F 98 8E en UTF-8. En UTF-16BE, ce serait D8 3D DE 0E. D’où l’importance de bien respecter le standard, sans quoi, on doit jouer aux devinettes.
Notre opérateur farceur, dans sa grande créativité, a décidé que ce serait plus drôle d’encoder en Latin-1 avant d’effectuer l’URL encoding. Évidemment, la doc reste muette à ce sujet – sinon ce ne serait pas drôle – ce qui évidemment faisait planter l’API lorsque des caractères non-ASCII devaient être décodés.
En effet, decodeURIComponent retourne une erreur si l’encodage est invalide. Je me retrouve donc obligé de parser et décoder manuellement les paramètres GET retournés par notre cher opérateur.
Par chance, les octets du Latin-1 matchent avec les code points Unicode, la conversion est donc assez aisée.
Par exemple, l’apostrophe droit, dont le code unicode est U+0027, vaut 27 en hexa du Latin-1, et sera donc encodée %27 avec l’URL encoding. Vous pouvez consulter la table Latin-1 sur le site de Standford.
Pour récupérer automatiquement le bon caractère en JavaScript, on utilise une simple REGEX pour obtenir la valeur après le “%”, puis on fait la correspondance directement avec la fonction fromCharCode.
Cette fonction retourne le caractère correspondant à un point de code Unicode. Cependant, elle retourne un codepoint en décimal et non en hexadécimal. Il suffit pour cela d’utiliser parseInt et le tour est joué. Voici donc le code correspondant :
Vous l’avez peut-être remarqué, on remplace les “+” par des espaces avant la conversion. En effet, le “+” est un caractère réservé qui compte pour un espace dans la norme URL encoding. On le remplace donc avant la conversion, car après, on ne serait plus en mesure de savoir s’il s’agit d’un plus “espace” ou réellement du signe “+”.
Encoder en UTF-8
L’UTF-8 est un encodage de taille variable. Il y a plusieurs moyens d’y parvenir en JavaScript. Si l’on est dans un environnement dans lequel le JavaScript moderne est supporté, aucun problème.
Et voilà, le tour est joué. Il est possible que vous souhaitiez travailler en hexa, on va se faire une petite fonction pour ça.
function encodeToUnicodeUtf8(str) { const encoder = new TextEncoder(); const utf8Arr = encoder.encode(str); return utf8Arr.reduce((acc, curr) => { acc.push(curr.toString(16)); return acc; }, []);}console.log(encodeToUnicodeUtf8('😎')); // F0 9F 98 8E
Voilà qui est mieux. Maintenant, admettons que vous désiriez une solution qui ne s’appuie pas sur les toutes dernières API ? Il y a la méthode de Google. Elle consiste à comparer chaque point de code au plan Unicode auquel il appartient et de l’encoder en fonction de sa place.
Il y a une intéressante discussion sur StackOverflow avec plusieurs implémentations à ce sujet.
Cependant, il y a une troisième voie. Peut-être que la partie précédente sur l’URL encoding vous a inspiré. On va pouvoir tricher un peu en s’épaulant de l’URL encoding. Nous avons encodeURIComponent dont nous avons précédemment parlé, mais aussi encodeURI.
Contrairement au premier, encodeURI n’encode pas les caractères réservés. Il encode donc les espaces et les caractères n’appartenant pas à l’ASCII. Voici donc mon implémentation rapide d’un encodeur UTF-8 basé sur encodeURI.
function encodeToUnicodeUtf8(str) { if (!str.length) return []; const url = encodeURI(str); const safeString = url.replace(/%20/g, ' '); // On remet l'espace comme un espace const utf8Arr = []; let multiByte = false; let multiByteChar = ''; Array.from(safeString).forEach((str) => { // S'il y a un % c'est qu'on part sur du multibyte encodé par encodeURI if (str === '%') multiByte = true; // Premier caractère de l'octet else if (multiByte && !multiByteChar) multiByteChar = str; // Second caractère de l'octet encodé else if (multiByte) { utf8Arr.push(multiByteChar + str); multiByteChar = ''; multiByte = false; } // Le caractère n'a pas été encodé, on récupère son codepoint else utf8Arr.push(str.charCodeAt().toString(16)); }); return utf8Arr;}
Conclusion
J’espère que cet article vous a permis de comprendre l’importance de l’encodage dans la gestion du texte et des communications inter-programmes. Si vous souhaitez encore approfondir la question, je vous recommande la lecture de deux articles : It’s Not Wrong that “🤦🏼♂️”.length == 7 et JavaScript has a Unicode problem.
On a vite tendance à oublier les subtilités de la gestion des différents encodages dès que l’on n’a plus à le gérer explicitement. Aussi, n’hésitez pas à le mettre en favoris pour vite y revenir quand le besoin se présentera 😉
]]>
Lorsqu'on a besoin de gérer gérer l'encodage de texte, on est un peu perdu car c'est transparent 99% du temps Découvrons sa gestion en JavaScript !
Sites statiques et Jamstack : la révolution frontendhttps://buzut.net/sites-statiques-et-jamstack-la-revolution-frontend/2020-10-18T22:00:00.000Z2024-09-05T06:56:59.840ZLes générateurs de sites statiques (GSS ou communément nommés SSG), sont devenus en quelques années, grâce aux apports de la Jamstack, des outils de premier plan. D’une solution pour blog de développeur, ces technologies propulsent aujourd’hui des sites à fort trafic et à forte valeur ajoutée.
Spotify, Mastercard, Nike, Google, Facebook, Airbnb… Ce ne sont que quelques-uns des utilisateurs de ces solutions. Quels en sont donc les avantages, qu’est-il possible de faire avec cette nouvelle stack et comment ? Autant de questions auxquelles nous allons répondre dans cet article.
Un peu d’histoire
Lorsque Tim Berners-Lee créé le web en 1989, il n’existe rien d’autre que des sites statiques : pour créer un site, il faut manuellement écrire chacune des pages en HTML.
Comment faire afin de n’écrire qu’une seule fois des éléments qui se répètent sur toutes les pages ?
Est-il possible de dynamiquement générer du HTML ?
C’est en 1993 qu’ils créent un serveur web, NCSA HTTPd, avec deux technologies majeures :
les Server Side Includes permettent de construire un document HTML à partir de plusieurs fichiers en permettant d’inclure le HTML d’un fichier dans un autre. Ainsi, le code du header et du footer (et tout autre élément redondant) n’est plus à répéter sur toutes les pages.
la Common Gateway Interface (ou CGI) permet la communication du serveur web avec des programmes externes qui peuvent lire les requêtes reçues par le serveur et générer du HTML à envoyer au client.
Le web dynamique était né. Ce n’est qu’un an plus tard, en 1994, que Rasmus Lerdorf créé un langage spécifiquement dédié à la génération dynamique de pages HTML, le PHP. Les premiers générateurs de sites statiques grand public ne se font pas attendre très longtemps, FrontPage et Dreamweaver arrivent respectivement en 1995 et 1997.
Viennent ensuite les CMS, TYPO3 débarque en 1998, rapidement suivi par de nombreux autres : SPIP, Dotclear, Drupal, WordPress, Joomla… Les CMS vont dominer le paysage du développement web pendant près de 15 ans. Qu’il s’agisse d’un site vitrine ou d’un site e-commerce, le CMS est l’outil de choix dans près de 99% des cas.
La LAMP Stack
Je me souviens de mes débuts sur le web. J’étudiais le HTML sur le Site du Zéro et le cours terminait pas un chapitre sur les formulaires. Après avoir appris les différents champs existants, les méthodes POST et GET et l’utilité de target, le cours concluait donc :
Vous savez envoyer des données via un formulaire. Il faut maintenant apprendre un langage backend comme PHP pour les récupérer et les traiter, sinon ça ne sert à rien.
Gros éléctrochoc. C’était l’époque du “Web 2.0” et je réalisais que le seul moyen pour moi de ne pas rester bloqué au stade 1.0 était de maîtriser un langage backend… j’étais parti dans l’apprentissage de PHP, puis de MySQL.
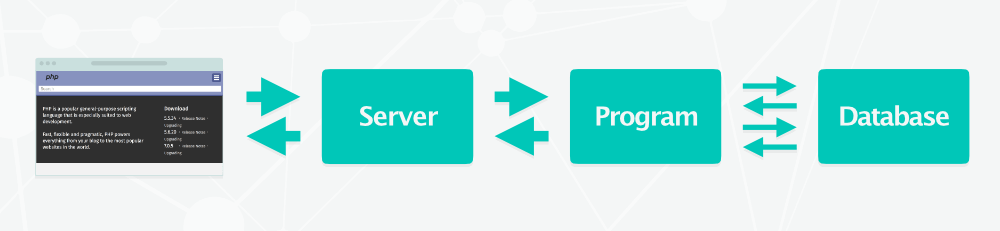
La stack classique avec rendu dynamique côté serveur
C’était il y a plus d’une décennie. À l’époque, la stack LAMP (Linux, Apache, MySQL, PHP) était reine. D’autres stack existent, mais toutes présentent le même schéma de fonctionnement :
le navigateur du client demande une page au serveur web,
le serveur demande à son tour la page au moteur de rendu dynamique (PHP, Java…),
le moteur interroge la base de données,
le moteur génère le HTML à partir des données récupérées,
le moteur transmet les données au serveur web,
le serveur web envoie les données au client.
Tous les CMS fonctionnent de cette manière, il s’agit du one best way en matière de programmation et d’hébergement. C’est le seul moyen de bénéficier des fonctions modernes du web.
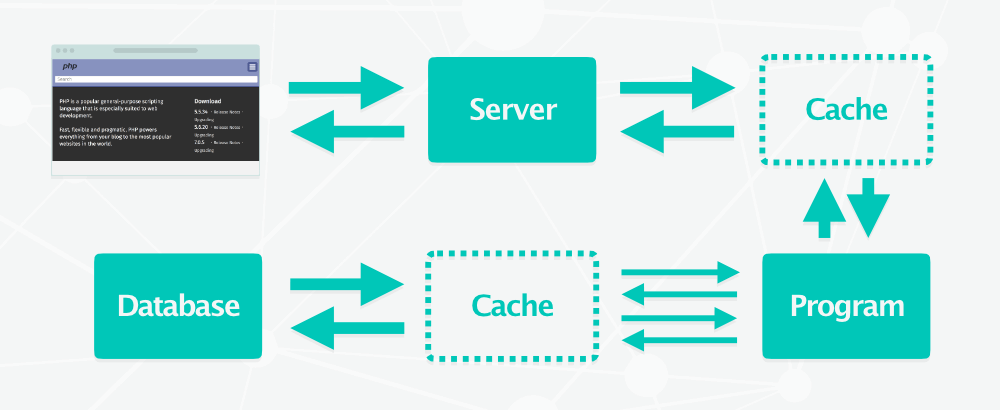
Évidemment, générer les pages à chaque fois qu’un utilisateur la demande consomme beaucoup de ressources et n’est donc pas scalable. Si vous avez déjà utilisé WordPress par exemple, chacun sait qu’il y a de nombreux plugins de cache.
La première fois qu’une page est consultée, elle est dynamiquement générée, puis le HTML généré est stocké et sera directement servi au prochain visiteur, sans re-passer par la case génération dynamique.
LAMP stack avec système de cache
Cela fonctionne pour les pages dont le contenu est majoritairement statique, mais ce n’est pas valable pour les site proposant un compte utilisateur dont le contenu est unique à chaque visiteur. Dans ce cas là, on utilise un cache partiel et on ajoute un cache à la base de données pour ne pas requêter les mêmes informations encore et encore.
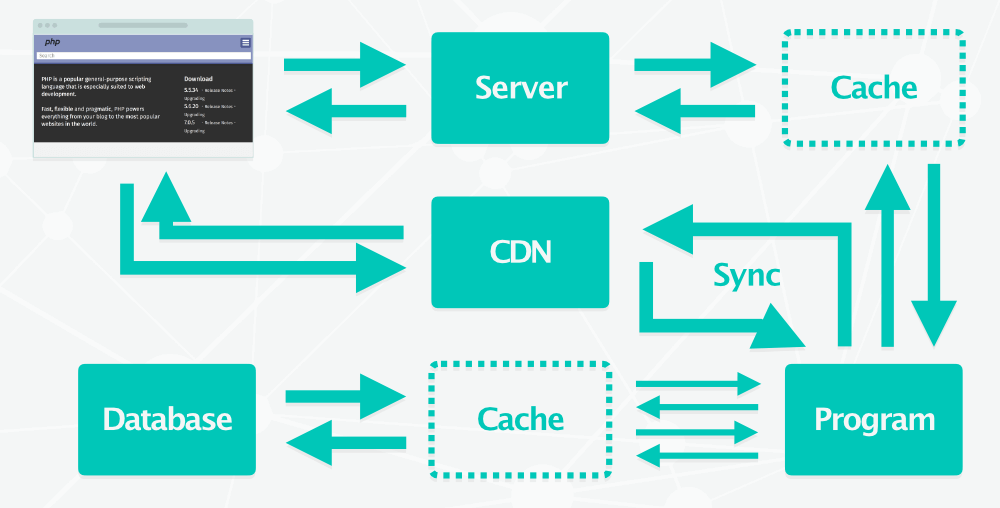
Évidemment, pour améliorer les performances, on stocke les fichiers statiques (CSS, JavaScript, images) sur un CDN. On peut aussi y placer les fichiers pseudo-statiques : les pages HTML qui ne sont pas générées à la volée (celles qui ne changent que quelques fois par jour ou moins).
Mise en place d'un CDN et deux niveaux de cache
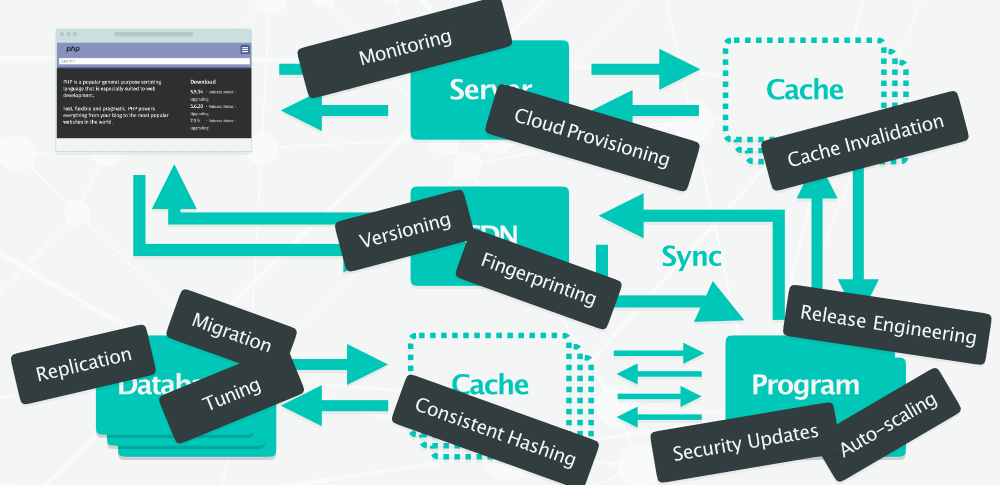
Toute cette infrastructure est complexe. Il faut s’assurer que la bonne version des fichiers est servie depuis le cache, effectuer les mises à jour de sécurité, veiller à ce que toutes les briques de la pile soient fonctionnelles, ajouter des serveurs pour encaisser l’augmentation du trafic etc.
Cette stack complexe nécessite des compétences dans de nombreux domaines
On arrive à un stade où il faut être ingénieur fullstack pour le moindre projet d’envergure. Même pour un simple blog sous WordPress, il faut continuellement se soucier des mises à jour, de la compatibilité des différents plugins, du thème etc.
Autant dire qu’une certaine stack fatigue finit par se faire sentir. Les développeurs veulent développer et non passer leur temps à faire de l’ops et de l’adminSys.
Le retour des SSG
Les générateurs de sites statiques (SSG ou GSS en français) ne sont pas nouveaux. En plus des générateurs grand public déjà mentionnés, ils sont largement utilisé par les développeurs afin de générer la documentation logicielle.
Les générateurs de documentation produisent le HTML à partir du code source. Le plus ancien SSG destiné à la documentation est JavaDoc, sorti en 1995. Doxygen arrive quelques années plus tard et supporte de nombreux langages. Enfin, bien bien d’autres sont spécifiques à leur propre langage.
C’est cependant en 2008 que l’usage des SSG explose avec les GitHub pages. Cette feature de GitHub permet de publier des sites directement depuis le dépôt Git. Il suffit pour cela de glisser/déposer un site pré-construit (fichiers statiques) ou d’utiliser Jekyll, le SSG créé par le co-fondateur de GitHub.
Il était possible d’utiliser un SSG avant les GitHub Pages et de simplement déployer sur le cloud, sans avoir à se soucier de maintenance et de sécurité. Néanmoins, avec les GH Pages, les développeurs accèdent à une approche résolument moderne : terminé les déploiements via FTP ou rsync, on n’utilise désormais plus que Git et tout est automatisé avec la CI/CD.
S’en suit alors une explosion des générateurs de site statique. Les blogs de développeurs migrent par milliers des CMS aux SSG. Le site statique devient une mode et il se créé des SSG toutes les semaines, même WordPress possède sont SSG.
Aujourd’hui, l’environnement est mature, chaque langage présente un choix d’outils confortable. Développeur Python, Ruby, Java, Go ou JavaScript ? Aucun problème. Barbu ne jurant que par le C ou le Rust ? T’inquiète. Sysadmin amoureux du Bash ? On a ce qu’il te faut !
Bien qu’il ne soit absolument pas nécessaire de connaître le langage dans lequel un SSG est programmé pour l’utiliser, de nombreux développeurs apprécient de pouvoir l’étendre ou le modifier au besoin (même s’il ne le font jamais…).
Pour trouver le SSG qui saura combler vos besoins, direction le site Jamstack.org, où l’ensemble des SSG disponibles sont référencés et triables par langage et moteur de template.
La puissance des navigateurs
Dans les années 90 et dans le début des années 2000, les navigateurs étaient de simples lecteurs de documents. Toute l’interactivité devait donc se passer côté serveur.
Cependant, avec l’émergence de l’Ajax dans les années 2000 apparaissent les SPA et les WebApps, lesquelles sont des sites web qui ne nécessitent pas de rechargement de page et offrent une expérience identique à un logiciel natif.
De Gmail à Docs, les webapps Google représentent bien les possibilités offertes par les navigateurs
On pense immédiatement aux applications web de Google (Gmail, Google Docs…), mais les exemples d’applications web ne manquent pas. Sans aucune exécution côté serveur, vous pouvez par exemple compresser vos images, vos SVG ou gérer vos listes de tâches.
Les fonctions jusque là réservées aux applications natives, plein écran, hors connexion, notifications, fonctionnement en arrière plan, accès au GPS, au Bluetooth etc, sont aujourd’hui regroupées sous le terme PWA.
Jamstack, le stéroïde du SSG
Le titre parle de “révolution frontend”, mais jusque là, rien de bien nouveau me direz-vous : les développeurs frontend peuvent faire des sites statiques… c’est ce qu’ils ont toujours fait.
Site statique ou non, on a tout de même certains besoins – immédiatement identifiés ou qui arrivent au fil de l’eau – les commentaires, la recherche, éditer sans passer par un éditeur de code etc.
La Jamstack arrive à une période où l’on migre un peu tout vers le cloud et c’est en réalité bien de cela qu’il s’agit. L’idée de la Jamstack est que l’on veut se concentrer sur le front (d’où le lien avec le site statique) et que l’on confie le reste à des services cloud (recherche, paiement, base de données, authentification…).
Définition de la Jamstack
Le terme a été créé par Mathias Biilmann, le fondateur de Netlify, un hébergeur cloud dédié aux sites statiques et à la Jamstack. La plupart des images précédentes sont d’ailleurs tirées des slides d’une de ses conférences.
JAM signifie JavaScript, APIs et Markup. La Jamstack désigne tous les sites/webapps dont le contenu est pré-généré (processus de build ou pages statiques) à partir de Markup (Markdown, JSON, HTML) et dont l’interactivité repose exclusivement sur le JavaScript côté client et l’usage d’APIs.
Tout site de la Jamstack a comme point commun de ne pas dépendre d’un langage côté serveur et d’être pré-compilé. Un site dédié est créé pour évangéliser la communauté et expliquer les mérites de cette nouvelle stack.
Bien entendu, une stack LAMP classique reposait aussi souvent sur des services externes. Par exemple, un WordPress/WooCommerce utilisera un service de paiement externe (que l’on appelle cela cloud ou pas, il ne sera donc pas complètement autonome).
La différence est qu’en mode Jamstack, on pousse l’externalisation à l’extrême : il n’y a plus de serveur du tout et plus vraiment de backend. On utilisera peut-être une base de données (cloud) pour stocker les produits et leurs prix (certains stockent tout directement via l’API Stripe), les comptes clients pourront être gérés via des fonctions serverless, les emails seront envoyés via Sendinblue ou Mailchimp etc.
Évidemment, l’avantage est que comparé à une stack classique, on ne se soucie absolument pas de l’infrastructure, des mises à jour, de la sécurité etc. En somme, Jamstack = Cloud.
Le terme Jamstack regroupe donc des choses bien différentes :
un SSG qui prend du Markdown en entrée (ou texte brut ou HTML) et recrache un site en HTML (par exemple ce site),
une application full JS avec un framework tel que React qui appelle de nombreux services externes.
Si je résume de manière assez prosaïque, la Jamstack, c’est du site statique qu’on saupoudre de Serverless au besoin. Frank de Jamstatic.fr, nous offre une synthèse en français du site Jamstack.wtf.
Maintenant que vous savez vraiment en quoi consiste ces différentes technologies, voyons comment se frayer un chemin dans cette jungle technologique.
Choisir son SSG
Nous l’avons dit, il existe de très nombreux SSG. Le site Jamstack les regroupe presque tous, c’est donc un bon point de départ si vous n’avez pas déjà un SSG préféré.
De manière générale, il y a trois grandes méthodes pour générer le contenu. Cela dépend beaucoup du type de projet :
Le volume de contenu est limité et il change peu (site vitrine…) :
vous codez le HTML à la main,
vous utilisez un SSG minimaliste intégrant un moteur de template afin de placer les portions répétitives (header, footer, menu…) dans des templates séparés et de bénéficier de l’interpolation de variables (pour centraliser des données dans un fichier de config par exemple).
Le volume de contenu est plus conséquent (blog, magazine, site d’entreprise, e-commerce…) et/ou il aura tendance à souvent évoluer (éditions, ajouts…), vous vous dirigez dans ce cas vers un SSG qui génère le HTML à partir de markup (Markdown en général, mais d’autres existent).
Lorsque l’architecture du contenu est très complexe ou de grande ampleur, il est possible d’utiliser des CMS Headless, lesquels délivrent le contenu via des API. On se dirigera alors vers un SSG capable de récupérer le contenu depuis une API ou vers un framework web tel que React, Angular ou Vue.js.
Dans le premier cas, j’utilise Dopamine. Il s’agit d’un SSG que j’ai créé, basé sur npm et EJS, un langage de template dont la syntaxe est celle de JavaScript. Il n’y a donc rien à réapprendre et on s’évite juste de faire des copier-coller dans tous les sens, parfaitement adapté pour les sites marketing.
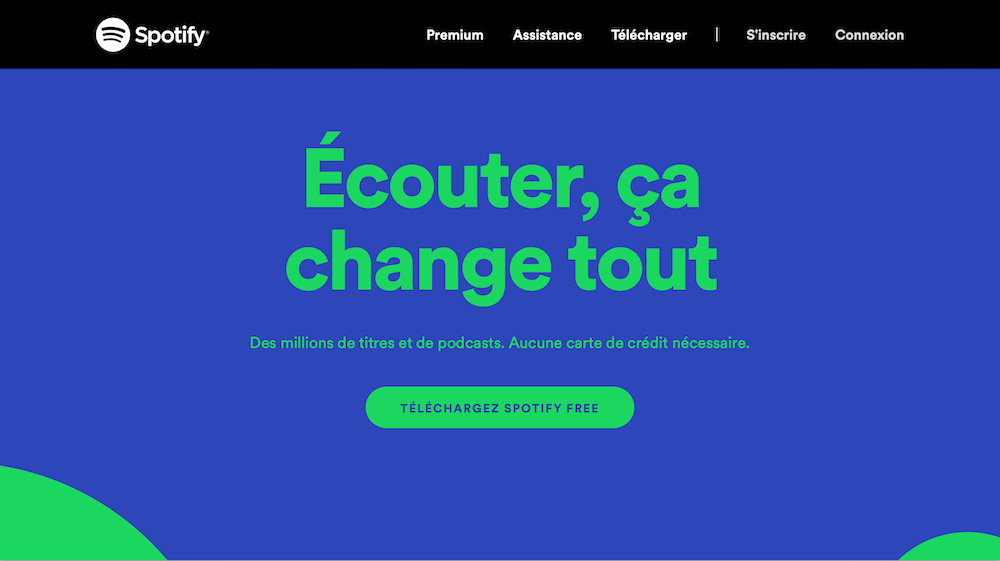
Page d'accueil de Spotify, focus sur le design
Dans un cas de figure comme celui-ci, on pourrait presque se contenter de coder le tout à la main sans SSG. Un générateur simple comme Dopamine offre un peu plus de confort avec du templating, l’inclusion d’un pré-processeurs CSS et la compilation du JavaScript.
Dans le second cas, en tant que développeur JavaScript, j’utilise Hexo (ce site l’utilise). C’est mon SSG de choix car il est développé en JavaScript, qu’il est rapide, très bien documenté et qu’il dispose d’un nombre de plugins et de thèmes impressionnants.
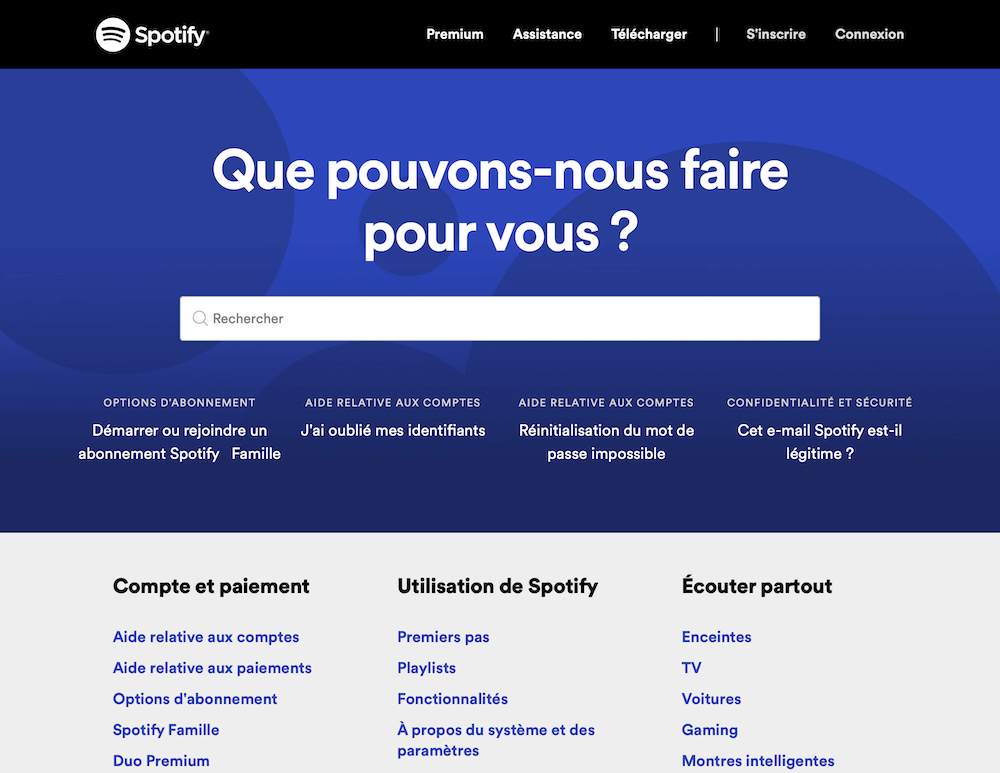
Page d'aide de Spotify, le contenu est plus conséquent
On peut ici légitimement penser que le contenu n’est pas géré par les développeurs. Un SSG comme Hexo répondrait bien à cette problématique : tout est mis en place par les développeurs mais le contenu est totalement gérable sans toucher au code. Le contenu sera réparti entre des fichiers Markdown et Yaml qui pourront être édités sans connaissances particulières. Chaque fichier Markdown dispose d’ailleurs d’un en-tête Yaml afin de définir des métadonnées : de la meta description au nom de l’auteur, vous y mettez ce que vous voulez, le SSG pourra récupérer ces éléments pour les utiliser dans les templates.
La communauté d’Hexo est très développée en Asie (son principal développeur est Taïwanais). De ce fait, on verra plus souvent des articles sur Eleventy (s’écrit aussi 11ty) sur les sites et blogs francophones et anglophones. Néanmoins, toutes la documentation et l’aide dont on peut avoir besoin se trouve en anglais et l’offre de plugins est incomparablement plus riche du côté d’Hexo.
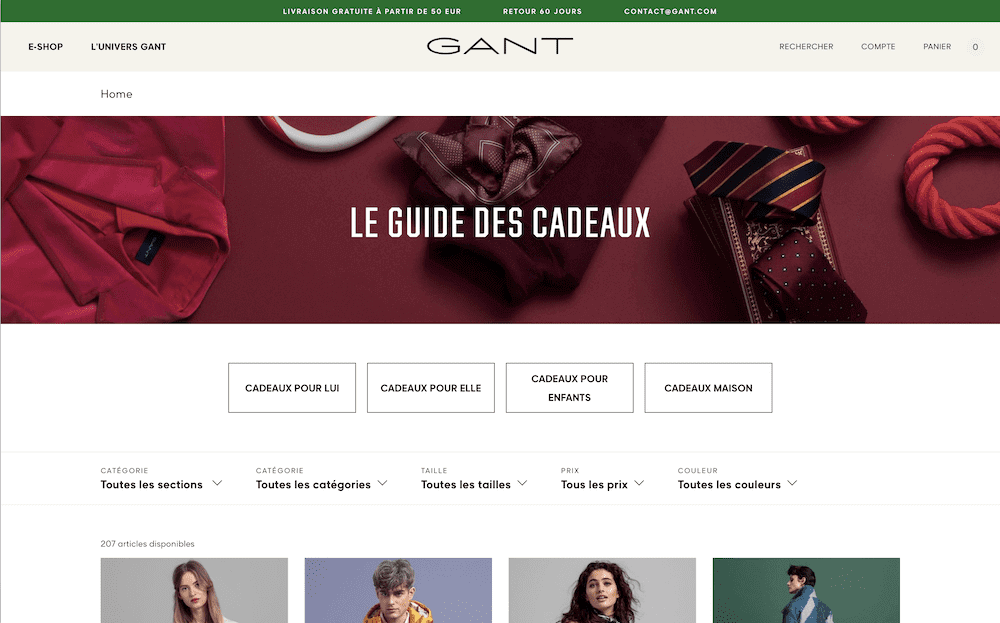
Page du e-shop de Gant, on imagine des produits, la gestion des réductions, informations de livraisons, lookbook…
Si le contenu n’est accessible qu’au travers d’API, on veillera à utiliser un SSG compatible avec cette méthode de récupération. Parmi les SSG JavaScript, à la fois Hexo et 11ty en sont capables, mais on a également souvent recours à des SSG basés sur React et Vue.js : Next.js, Gatsby et Nuxt.js.
Ces derniers SSG permettent bien entendu également de consommer du Markdown. On les préférera la plupart du temps pour des sites complexes et lorsque les sources de données sont multiples.
Choisir son hébergeur
Dans sa forme la plus simple, le site statique n’est qu’un ensemble de fichiers statiques. Virtuellement tous les hébergeurs conviendront donc. J’ai hébergé des sites statiques sur des mutualisés, des VPS, etc.
Un simple mutu fait donc l’affaire, lorsque le site est build, on peut le déployer de la manière qui nous plaît. J’ai par exemple déjà utilisé les modules sftp et rsync pour déployer un site respectivement sur un hébergement mutualité et un serveur virtuel.
Il existe cependant des hébergeurs spécialisés. Ces derniers permettront de se connecter directement au repo Git et s’occuperont automatiquement de build et deploy dès que des modifications seront effectuées sur une branche donnée. Ainsi, vous ne vous occupez plus que de pusher, le reste est automatique !
En outre, ces hébergeurs apportent un peu de dynamique aux sites statiques : gestion des formulaires, identification des utilisateurs (pour un espace membre par exemple), exécution de fonctions cloud…
Les deux principaux sont Vercel et Netlify. Leurs fonctionnalité sont assez similaires, chacun ayant toutefois ses domaines de prédilections. Netlify permet de facilement ajouter des fonctions aux sites statiques grâce à son catalogue de plugins. Vercel se distingue dans une fine gestion des fonctions cloud et permet le pre-rendering ; Vercel est développé par les auteurs de Next.js.
J’utilise pour ma part Netlify mais Vercel pourrait tout aussi bien convenir pour mes besoins. Pour plus d’informations à ce sujet, le mieux est de lire les retours de personnes ayant utilisé les deux : Vercel vs Netlify et retour d’expérience entre Vercel, Netlify et Azure Static WebApp.
Nous avons parlé de Git sans jamais mentionner les endroits où la plupart de nos dépôts sont stockés. GitHub et GitLab permettent tous les deux d’héberger des sites statiques : GitHub Pages et GitLab Pages. Comme ces deux platformes offrent des minutes de build dans tous leurs plans, il est possible de déclencher un build dès lors que de nouvelles modifications sont pushées.
GitLab exécutant un processus de build
Les deux services offrent des fonctions spécifiques afin de pouvoir gérer les 404 et des redirections basiques. Pour plus de contrôle et de performances, il est même possible de servir ces Git Pages depuis Cloudflare.
Positionner Cloudflare en front permet un contrôle assez fin de la réécriture et redirections, options qui font notamment défaut à Netlify. Il n’est par exemple actuellement pas possible de forcer la redirection de tout monsite.com/page/index.html vers monsite.com/page/ ni monsite.com/test.html vers monsite.com/test, ce que je trouve assez dommageable.
D’ailleurs, puisque l’on parle de Cloudflare, ce dernier aussi est monté dans le train du Serverless et de la Jamstack. Il propose des Function as a Service (FaaS), ainsi qu’un hébergement spécifique pour les sites statiques. De quoi concurrencer Vercel et Netlify. Il s’adresse toutefois aux développeurs avec un plus grand besoin de contrôle (au détriment d’une complexité supérieure).
Performances
En terme d’hébergement, il est important de mentionner les performances. Je peux facilement comparer car le présent site était il y a un an encore sur WordPress.
Mon site WordPress était ultra-optimisé avec un thème codé à 100% par mes soins, de la même manière que le thème actuellement utilisé avec Hexo. De ce fait, les performances ne bénéficient pas d’un boost notable.
En revanche, j’ai essayé différents hébergements pour le site statique. Actuellement, ce site utilise Netlify. Cependant, la recherche est effectuée directement en front et les commentaires sont gérés par Jamments une API de commentaire open source dont je suis l’auteur. De ce fait, n’importe quel hébergeur ferait l’affaire.
Performance avec un hébergement VPS OVH
J’ai tout d’abord utilisé un server virtuel sur lequel j’avais d’autres sites webs, dont des WordPress. Les fichiers étaient simplement servis par Apache, configuré aux petits oignons. On voit qu’on obtient de très bonnes performances avec cette configuration toute simple, mais efficace.
Performance avec le site hébergé sur GitLab avec Cloudflare
Ensuite, j’ai voulu simplifier le workflow et ne plus du tout avoir à gérer de serveur : un VPS, comme un serveur dédié, nécessite une configuration et une maintenance manuelle, peut poser problème en cas de très fort trafic etc. J’ai donc naturellement utilisé GitLab pages (puisque c’est là que j’héberge le code du blog) et placé Cloudflare par dessus.
Notez qu’on obtient des performances raisonnables même sans Cloudflare, mais on bénéficie d’un peu moins d’options de configuration.
Performance avec le site hébergé sur Netlify
En dernier lieu, le même site hébergé chez Netlify obtient, malgré tout le discours marketing, de moins bonnes performances. On obtient en échange une facilité de deploy inégalable et de nombreux plugins pour ajouter du dynamique à son site statique. De plus, Netlify permet de se connecter à de très nombreux outils pour gérer le back-office, c’est un gros plus.
Choisir son back-office
Lorsque l’on parle de site statique et de SSG, de manière classique, le contenu est géré au même niveau que le code : les fichiers sont côte à côte, tout s’édite via l’éditeur de code/texte et l’ensemble est versionné (en général dans Git).
Cette expérience peut convenir aux développeurs, mais s’il y a ou doit avoir dans l’équipe des rédacteurs non développeurs, cela peut vite devenir compliqué. Par ailleurs, force est de reconnaître que l’expérience que l’on a avec les CMS traditionnels me paraît plus plaisante de ce côté là.
Personnellement, lorsque je veux modifier une typo, je n’ai pas envie d’ouvrir mon éditeur de code, commiter ma modification, puis la pusher (ou build & deploy selon la config du projet).
C’est là qu’entrent en jeux les CMS dit headless. Ce sont des interfaces d’éditions totalement découplées du front. Leur objectif est de gérer le contenu, rien d’autre. Contrairement aux CMS classiques, ils ne s’occupent pas de gérer le contenu.
Il y a principalement deux types de CMS headless :
les CMS basés sur Git, on les utilise pour gérer des sites dont les sources sont principalement des fichiers texte (Markdown, Yaml, JSON),
les CMS API driven, permettent de gérer des sites de plus grande ampleur ou plus complexes.
L’approche Git-based est tout à fait viable pour les sites d’envergures. À titre d’exemple, Smashing Magazine utilise Git et Netlify.
En revanche, un gros site e-commerce avec des milliers de références aura plutôt tendance à utiliser un CMS de la seconde catégorie. Ce choix est fortement corrélé au type de SSG précédemment abordé. Par ailleurs, le contenu issu d’un CMS API-based sera plus facilement consommé par différents terminaux (site, application mobile, montre connectée, assistant vocal, panneau d’affichage…).
Je ne vais pas m’éterniser sur les comparaisons entre les deux. Pour plus de détails, vous pouvez lire l’article de Jamstatic à ce sujet.
Git-based
En ce qui me concerne, ce que je n’apprécie pas tellement avec l’approche Git-based, c’est d’avoir tous mes fichiers au même endroit (code et contenu). C’est un avantage pour certains, moi, ça m’ennuie un peu pour les projets dans lesquels il y a beaucoup de contenu et qu’il est modifié la plupart du temps indépendamment du code.
J’ai en effet pour habitude d’avoir des commits atomiques proprement nommés. Lorsque l’on modifie principalement du contenu, cette règle devient plus compliquée à respecter. Ce n’est pas du tout le cas lorsqu’il s’agit d’un site marketing/vitrine où il y a moins de contenu et où celui-ci est intimement lié au design et donc au code.
Il est tout à fait possible de créer un repo pour le code et un repo pour le contenu
Pour remédier à cette situation, je divise souvent le projet en deux repos : un pour le code à proprement parler et l’autre pour le contenu. Mis à part cela, c’est la configuration la plus simple et la plus portable. Votre contenu est dans un format standard flat file (Markdown, Yaml, JSON) et vous pouvez donc changer de CMS comme de SSG en un rien de temps.
Une grande partie des CMS Git-based se destinent à un SSG particulier. Il y en a cependant aussi des généralistes. Vous trouverez une liste assez complète sur le site Jamstack.org. Nous allons nous concentrer sur les deux plus populaires parmi ceux prenant en charge tous les SSG.
Netlify CMS
Netlify CMS est un outil open source (vous pouvez l’utiliser indépendamment de Netlify) qui offre des fonctions de CMS pour les projets hébergés sur GitHub, GitLab et Bitbucket).
Il est possible de placer le code du CMS directement dans la codebase du projet. Ce CMS offre une interface simple et permet de gérer des projets relativement simple. Il permet toutefois de gérer un workflow de publication permettant une validation par un éditeur avant publication des contenus et permet également l’open authoring.
Néanmoins, Il ne convenait pas pour le présent site car il était impossible d’avoir plusieurs niveaux de répertoires : j’utilise un répertoire regroupant toutes formations/ pour les formations, et chacune possède plusieurs chapitres regroupés dans un répertoire par formation. Cela me permet d’avoir des urls du genre /formations/formation_y/chapitre_z/ et ça n’était pas possible dans Netlify CMS.
Si vous désirez en savoir plus sur la manière de le configurer, je vous invite à regarder cette vidéo assez complète.
Forestry
C’est vraiment la solution qui a retenu mon attention. Il s’agit d’un SaaS et non d’une solution open source. Vous ne vous souciez donc pas de l’hébergement, et vous devrez prendre un abonnement pour accéder à certaines fonctionalié.
Le tiers gratuit est cependant assez généreux et permet de bien tester la solution. Comme le CMS de Netlify, il permet de se connecter à GitHub, GitLab et Bitbucket et y ajoute aussi Azure DevOps. Les fonctionalités sont plus étendues que son cousin.
On aura notamment accès à l’édition avancée de répertoires contenant des sous-répertoires, des étideurs spéciaux pour des data files – ces fichiers JSON ou Yaml qui contiennent des données structurées consommées par le SSG (structure de menu, informations de contact, configuration de layout…).
Par ailleurs, on pourra procéder à la configuration directement depuis l’interface web sans avoir à s’égarer dans le fichier de config JSON.
API-based
Contrairement aux CMS Git-based, ceux-ci sont destinés à un très large panel de solutions. Nous l’avons dit, le contenu accessible via une API peut tout aussi bien être consommé par un SSG que par une webapp, une application mobile ou desktop, un assitant vocal etc.
C’est l’un des principaux avantages de ce type de CMS. Par ailleurs, il est possible de requêter les données de manière dynamique depuis le site ou l’application et cela offre de nombreux avantages :
génération de page selon la requête de l’utilisateur ou ses préférences (filtres…),
possibilité de faire de la recherche sur un volume de données important,
permet de ne pas avoir à relancer un build dès qu’un contenu est modifié (primordial dans les cas où le contenu change constamment).
Le choix est immense ! Contrairement aux CMS Git-based, le choix de CMS API-driven est énorme. Même des CMS classiques comme Ghost, WordPress ou Drupal disposent d’API permettant d’en récupérer le contenu. Dans ce cas, le CMS ne gère que le contenu, il ne s’occupe pas de rendre et d’afficher les pages web et peut être considéré comme headless.
Par ailleurs, de nombreux services n’étant absolument pas destinés à être des CMS peuvent le devenir. C’est par exemple le cas de Trello et Google Sheets.
Si un service propose une interface pour entrer des données et une API pour les récupérer, cela peut potentiellement devenir un CMS headless. Bien entendu, en plus des hacks précédemments mentionnés, il existe de nombreux services dédiés à cet usage.
Quoi qu’il en soit, avant d’adopter une solution API-driven, il faut bien être conscient de ses inconvénients :
les possibilités offertes par l’API à votre disposition peuvent vous limiter (recherche fulltext, filtres avancés…),
les CMS et leurs API ont des limites d’usage : stockage, nombre de requêtes par min/heure/jour…
vendor lock-in : on retombe dans le même schéma qu’avec les CMS traditionnels, le contenu n’est pas facilement portable d’une solution à l’autre.
Parmi les solutions les plus populaires, il se trouve les services cloud et les solutions open source à héberger soi-même. De nouveau, les deux côtés ont leurs avantages et leurs inconvénients. Une chose est certaine, héberger soit-même son CMS headless, qu’il s’agisse d’un WordPress ou d’une solution plus “moderne”, cela revient tout de même à retrouver les inconvénients de la gestion et de la maintenance backend classique.
Certains CMS sont plus spécialisés dans certains domaines que d’autres, mais de manière générale, vous définissez un modèle de donnée et les relations que ces données possèdent entre elles (un modèle comments et un modèle articles, ce dernier modèle peut référencer des comments). Une fois cela fait vous pouvez ajouter des données et les requêter.
Il va m’être difficile de vous présenter l’ensemble des possibilités du côté de l’offre API-driven. Le plus connu est incontestablement Contentful, mais Sanity, DatoCMS, ButterCMS et Prismic sont aussi populaires. Tous proposent une API GraphQL, certains proposent aussi REST.
Du côté des open source, le plus connu est sans conteste Strapi, lequel offre du GraphQL ou REST au choix et supporte les principales bases SQL ainsi que SQLite et MongoDB. Keystone – qui gagne en popularité – ne propose quant à lui que le GraphQL et supporte MongoDB et PostgreSQL. Strapi et Keystone sont codés en JavaScript.
Du côté de PHP, Cockpit est assez populaire et semble offrir une interface élégante et efficace. Cockpit supporte SQLite et MongoDB et offre une API JSON REST.
Face à tant de choix, mieux vaut se diriger vers la section Headless CMS de Jamstack.org et de voir celui qui correspond le mieux aux critères du projet.
Conclusion
On réalise que les sites statiques ont de réels atouts et des usages bien définis. Les générateurs de sites permettent de s’affranchir des tâches manuelles et répétitives. De leur côté, les workflows modernes basés sur Git permettent de se concentrer sur le code et d’automatiser la génération et le déploiement des modifications.
Enfin, les APIs, lorsqu’elles sont appellées en front, permettent de suppléer aux déficits inhérents des sites statiques en leur adjoingant la puissance du cloud, quand bien même, techniquement parlant, il s’agit plus de cloud et de serverless que de site statique.
On notera également que les CMS traditionnels trouvent leur place dans cet environnement complexe : ils permettent d’une part de servir de headless CMS en récupérant le contenu de leur API, mais peuvent aussi être utilisés comme SSG.
WordPress possède plusieurs plugins à cet effet : Static HTML Output et WP2Static. Shifter est un hébergeur spécialisé dans le WordPress statique : vous utilisez du WordPress, mais Shifter ne sert que du HTML statique et vous permet de paramétrer les règles de build de votre site.
Vous l’aurez compris, les possibilités sont infinies, l’ancien fait son renouveau et chaque besoin trouve sa solution !
]]>
Jamstack et générateurs de site statique sont devenus incontournables. Découvrons la raison de ce succès et les meilleurs solutions pour vos projets.
10 règles d'UX design spécifiques au e-commercehttps://buzut.net/10-regles-d-ux-design-specifiques-au-e-commerce/2020-05-03T22:00:00.000Z2024-09-05T06:56:59.832ZL’UX design (design de l’expérience utilisateur) est depuis quelques années dans toutes les bouches, le terme est à la mode. En contrepartie, nombre de sites ont encore beaucoup de progrès à faire. Tout site tire profit d’une bonne UX, cependant il y a quelques règles qui sont spécifiques au e-commerce.
Quand on connait l’impact spectaculaire qu’elles peuvent engendrer sur le taux de conversion et donc le chiffre d’affaire, mieux vaut ne pas passer à côté ! Voyons donc les quelques règles à absolument avoir en tête lors du design et du développement d’un site e-commerce. Il s’agit de conseils concrets, cet article est donc aussi bien destiné aux designers qu’aux développeurs, let’s go!
Je suis un développeur et je n’ai pas de compétence particulière en design d’interface (UI design). Cependant, j’estime qu’il est important d’acquérir une compréhension du fonctionnement d’un design. En outre, co-construire avec le designer (ou l’équipe design) sur les projets que je réalise mène toujours à de meilleurs résultats.
En ce sens, lors de la refonte du site d’Alphapole, j’ai effectué de nombreuses recherches et analysé les différentes itérations des designs, afin d’identifier les points de friction potentiels au niveau de l’expérience utilisateur.
Ajout au panier
Le bouton d’ajout au panier est omniprésent sur un site e-commerce. C’est l’essence même d’un site e-commerce que de pouvoir ajouter les articles dans le panier.
Je ne vais donc pas parler ici de la forme et du positionnement de ce bouton, lequel est un CTA qui répond aux règles d’UX classiques du call to action. Je vais plutôt détailler le comportement attendu lors du clic sur ce bouton.
En effet, l’ajout au panier est une étape essentielle dans le processus d’achat, il ne faut donc ni perdre ni frustrer l’utilisateur. Qu’attend-il du site lorsqu’il clique sur ce bouton ?
Il veut évidemment que le bouton ajoute l’article au panier,
Il veut être certain que l’article ait bien été ajouté,
Il veut ensuite poursuivre ses achats ou procéder au règlement.
Notre e-shopper veut être certain que son action a bien été prise en compte. Il faut donc que l’interface reflète l’action effectuée [en], un feedback visuel. Sans cela, il risque de cliquer une seconde fois sur le bouton et se retrouver avec l’article en double ou triple dans son panier.
En général, un site e-commerce possède une icône “panier”. Il est donc conseillé d’avoir un badge qui indique le nombre de produits présents dans le panier et optionellement le total ou sous-total. Ainsi, un ajout au panier viendra immédiatement mettre à jour ces informations. Cependant, cette icône manque de visibilité et, même avec une subtile animation, il y a de fortes chances que l’utilisateur ne le remarque pas.
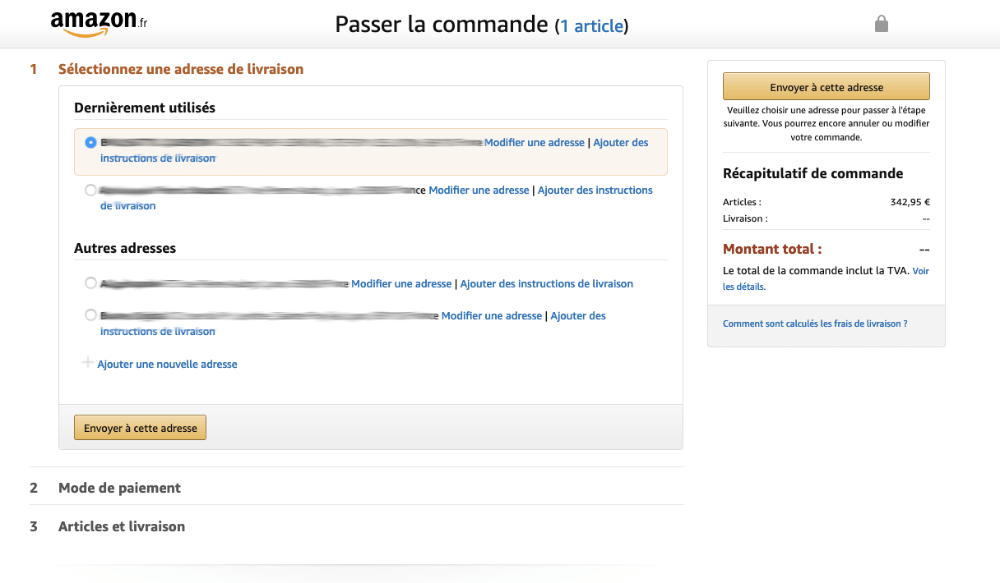
Pour plus de visibilité, deux options sont communément adoptées. La première est d’emmener l’utilisateur directement sur la page panier. Cette première option est à considérer très soigneusement. En effet, “ajouter au panier“ ne veut pas dire “aller au panier“. À moins que le site privilégie des paniers avec un seul article, cette option laisse moins de chance à l’utilisateur d’augmenter son panier moyen.
Dans un restaurant, lorsque vous avez fini votre plat, le serveur s’enquiert de savoir si vous voulez un dessert ou des cafés avant de vous apporter l’addition. La logique est ici la même. À moins qu’il s’agisse d’un site ne vendant qu’un seul type de produit ou des produits mutuellement exlusifs, cette solution est à éviter si vous voulez augmenter le panier moyen.
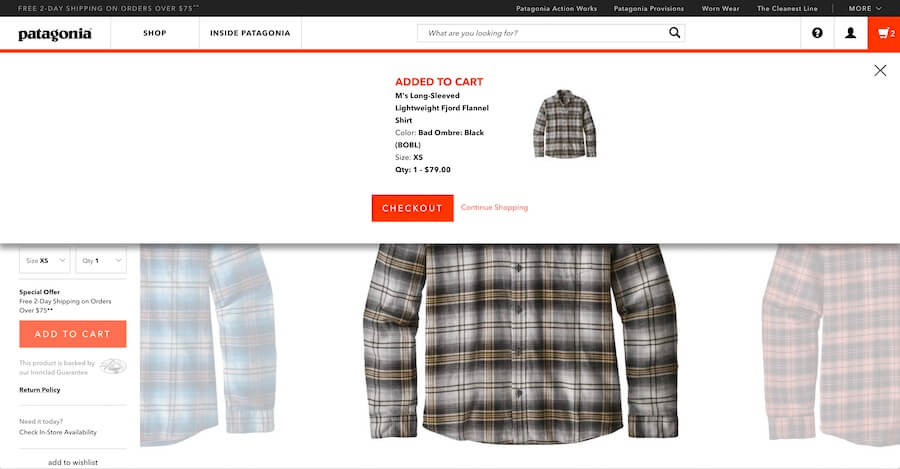
L’autre option existe sous différentes formes. Certains sites mènent à une page intermédiaire, d’autres utilisent une modale (ou popin). La logique est la même, on confirme à l’utilisateur que son article a bien été ajouté au panier. L’utilisateur veut également être certain que le bon article a été ajouté au panier. On affiche donc une image de l’article une image et le nom de l’article et la quantité ajoutée.
Chez Patagonia, on a une fenêtre qui descend, impossible pour l'utilisateur de ne pas le voir. Seul problème, elle disparaît d'elle même après quelques secondes. Mieux vaut laisser l'utilisateur maître de l'action
On peut également en profiter pour présenter à l’utilisateur un résumé de sa commande avec le nombre total d’articles dans le panier ainsi que le sous-total. De plus, on peut en profiter pour faire un cross-selling ou de l’upselling. Nous allons y revenir.
J’ai tendance à préférer l’utilisation de la modale à la page intermédiaire. Ainsi, le bouton fait vraiment ce qu’il indique : il se contente d’ajouter au panier et laisse l’utilisateur sur la même page. Vous avez dès lors l’opportunité de lui présenter ses options :
Une liste de produits qui pourraient l’intéresser en complément (cross-selling) ou remplacement (upselling),
Se rendre sur le panier si c’est ce qu’il souhaite,
Poursuivre ses achats (on ferme simplement la modale et l’utilisateur poursuit sa navigation comme il l’entend.
Upselling et cross-selling
Ces deux pratiquent signifient respectivement vendre des produits complémentaires et vendre un produit plus haut de gamme. Les deux peuvent s’utiliser en complément, tout dépend du besoin de la boutique en question.
L’important est de saisir les opportunités de x-selling et d’upselling. Certaines boutiques présentent ces options sur la page panier. La règle n’est ici pas absolue, mais une fois l’utilisateur sur la page panier, mieux vaut ne plus trop le distraire.
En revanche, les pages produits et la modale de confirmation d’ajout au panier sont des emplacements tout indiqués. Sur la page produit, le prospect exprime un besoin ou une envie par rapport au produit en question. Il a donc de grande chance d’être réceptif à des produits complémentaires de la même gamme et/ou des produits plus haut de gamme répondants au même besoin.
OVH propose toujours des produits complémentaires lors d'une commande
Lorsque notre utilisateur ajoute un produit au panier, il indique clairement si ce n’est une volonté d’acquérir ce produit, un très fort intérêt. C’est le moment idéal pour lui proposer des produits qui se marient bien avec celui qu’il est sur le point d’acquérir. Nouveau téléphone ou ordinateur ? Une housse ou coque de protection est une très bonne idée. Nom de domaine ? Voici une offre d’hébergement idéale pour votre prochain site…
Vous saisissez l’idée. L’utilisateur se sent accompagné dans sa démarche d’achat par un site “qui le comprend” et vous augmentez à coup sûr le panier moyen. C’est gagnant-gagnant.
Page panier
La page panier est un incontournable. La première erreur est de ne pas en avoir. Certains sites se limitent en effet à un “mini panier” qui s’affiche au survol de l’icône panier ou sur le côté. Ce choix a pour principal inconvénient de ne pas présenter une vue globale des éléments du panier ainsi qu’une interaction facile.
Les utilisateurs utilisent aussi le panier comme moyen de stockage. Ils y reviennent par la suite pour comparer différents produits entre lesquels ils hésitaient. Il faut donc leur faciliter la tâche en affichant les différentes informations utiles et un lien vers la fiche produit complète (en général le titre et la photo du produit). Cela permet de facilement retrouver tous les détails d’un produit avant la décision finale.
En outre, la panier doit permettre de supprimer des articles et d’ajuster la quantité facilement avec une mise a jour automatique. N’obligez pas l’utilisateur à cliquer sur un bouton pour calculer le nouveau sous-total et prendre en compte ses changements.
Ralph Lauren permet d'un clic de modifier, supprimer ou sauvegarder les articles du panier
Une fonction qui peut s’avérer appréciable : “envoyer ce panier par email”. De nombreux shoppers commencent sur mobile et terminent le processus d’achat sur leur ordinateur. Vous leur facilitez ainsi la tâche et vous gagnez une adresse email. Mieux vaut un tiens que deux tu l’auras ! De cette manière, vous serez en mesure de relancer le client s’il ne termine pas son achat, encore une fois, gagant-gagnant. On peut alternativement offrir la sauvegarde via un compte client.
Par ailleurs, c’est généralement sur cette page que se trouve le champ permettant d’entrer un code de réduction. Il est conseillé de ne pas rendre ce champ trop proéminent. L’utilisateur qui n’a pas de réduction risque d’être frustré de savoir qu’il est possible d’obtenir des réduction mais que lui n’en a pas.
En revanche, l’utilisateur qui possède un code de réduction cherchera l’endroit où rentrer son code. Au lieu de directement afficher le champ avec le bouton qui permet d’appliquer le code, vous pouvez simplement utiliser un lien “J’ai un code de réduction”. Ce n’est qu’au clic qu’apparaît le champ permettant à l’utilisateur d’entrer son code.
Mini panier
Il ne faut surtout pas penser que le mini panier est à bannir. Ce qui est contre-productif est de le concevoir en tant que substitut au panier normal. En revanche, grâce au mini panier, l’utilisateur peut d’un coup d’œil savoir ce que contient son panier et quel est le total de la commande.
Évidemment, le mini panier permet de naviguer vers la panier complet. En outre, l’utilisateur apprécie d’avoir l’option de passer directement au règlement de la commande. Comme toujours, l’utilisateur est maître et s’il le souhaite, il gagne un clic en évitant l’étape intermédiaire de la page panier.
En général, le mini panier apparaît au survol de l’icône du panier. Chez Alphapole, pour la version mobile, j’ai fait le choix de ne pas avoir de mini panier car son utilisabilité est bien moindre sur petit écran.
Le checkout
C’est là que tout se passe, l’étape finale jusqu’au paiement ! Cette étape est souvent appelée “tunnel de conversion”, car il regroupe les informations de livraison, facturation et paiement.
J’enfonce sûrement une porte ouverte mais il est bon de le rappeler : moins il y a de choses à rentrer pour l’utilisateur, meilleur sera le taux de conversion. Cela passe par de nombreuses choses :
Répartition des champs du formulaire en étapes ou one-page,
Mettre en avant les éléments de réassurance,
Enlever toutes les distractions pour que l’utilisateur se concentre sur sa mission.
La première chose à faire est de définir les étapes du processus de checkout. Il est tentant de tout mettre sur une seule page, cependant, s’il y a trop de champs, cela risque d’effrayer l’utilisateur.
Par ailleurs, si vous vendez des services numériques par exemple, vous pouvez peut-être vous contenter du nom, prénom et informations de paiement. Dans ce cas, le one-page checkout peut faire sens. Il n’y a là pas de règle unique, le mieux est de trouver des exemples qui peuvent s’appliquer à votre situation.
Voyez par exemple dans cet article pourquoi Banana Moon a fait le choix de migrer d’un checkout en une seule page vers un checkout en plusieurs étapes. Quel que soit votre choix, tentez de limitez au maximum les informations et de diminuez le travail de votre client.
Par exemple, si vous demandez les informations de facturation, il y a de grandes chances pour qu’elles soient les mêmes que celles de livraisons. Vous pouvez n’affichez ce formulaire que dans le cas où l’utilisateur clique sur “entrer une adresse de facturation différente”.
En outre, comme mentionné, il ne faut pas que l’utilisateur soit distrait. On peut enlever tous les éléments d’interaction tels que les menus et autres éléments cliquable. Amazon adopte par exemple cette approche. Vous ne laissez dans ce cas qu’un lien permettant à l’utilisateur de revenir au panier s’il le souhaite.
Sur Amazon, au stade de la confirmation de paiement, le menu et la plupart des liens disparaissent
De plus, faites en sorte que le résumé de la commande soit facilement localisable, même sur mobile, l’utilisateur voudra sûrement vérifier une dernière fois le total, les frais de port et le contenu de sa commande avant de la payer.
En dernier lieu, vous avez sûrement déjà vécu cette expérience où, prêt à réaliser votre achat, on vous demande de créer un compte. Mais vous souhaitez juste régler la commande, pas prendre une carte d’abonnement. C’est un peu comme si au supermarché, vous étiez obligé de prendre une carte de fidélité pour pouvoir acheter quoi que ce soit.
Obliger l’utilisateur a avoir un compte peut faire sens pour Amazon, cependant, c’est un frein énorme pour la majorité des sites, même de marques connues. Vous devez donc impérativement offrir un guest checkout qui ne nécessite pas de compte. Une fois la commande passée, comme vous avez déjà toutes les informations nécessaires, vous pouvez proposer à l’utilisateur de créer un compte (en lui expliquant les avantages, tel que le suivi de commande). Il n’a alors plus qu’à entrer un mot de passe et voilà le compte est créé !
Aspects techniques
Pour faciliter la saisie des informations, on veillera bien à préciser le type adéquat pour chaque champ de formulaire. Ainsi, le clavier du téléphone s’adapte lorsqu’il faut saisir un téléphone ou un email par exemple. C’est bien plus agréable !
En outre, si rentrer des informations est fastidieux, ce n’en est pas moins inévitable… ou presque ! Que l’on soit sur mobile ou desktop, la plupart des navigateurs connaissent déjà les informations de l’utilisateur et peuvent donc remplir automatiquement le formulaire. Safari sur iOS propose de pré-remplir le formulaire sur le checkout d’Alphapole, l’utilisateur n’a alors rien à saisir manuellement
Le pre-remplissage fonctionne pour toutes les coordonnées ainsi que pour les cartes de crédits. Il suffit de bien indiquer au navigateur quelles sont les données à placer dans chaque champ. Cela s’effectue via des attributs HTML.
Enfin, la dernière chose à faire est de penser à désactiver la correction automatique sur les champs qui risquent d’être problématique. Ainsi, personne n’a envie de se voir corriger l’orthographe de son nom de famille… De nouveau, la désactivation de la correction se fait via un simple attribut HTML sur les input et textarea :
Entrer ses numéros de carte n’est à nouveau pas le plus fun dans une transaction, d’autant plus que c’est souvent source d’erreur. Une fois de plus, les navigateurs tentent de faciliter la vie des internautes.
Si les informations de carte sont déjà disponibles dans le navigateur, elles pourront être remplies automatiquement à la demande de l’utilisateur. Si elles ne sont pas présentes, certains navigateurs/appareils offriront la possibilité de scanner les numéros de la carte via l’appareil photo.
Ces deux fonctionnalité ne sont disponibles que lorsque les attributs des champs de carte sont bien renseignés.
En terme de design, si vous en avez le contrôle, rendre le tout visuel améliore grandement l’expérience utilisateur.
Il est ici indéniable que la projection des informations sur un visuel de carte améliore l'UX
Programme fidélité
Pour certains, cela peut paraître anodin, mais les consommateurs adorent les programmes de fidélité. Vous seriez surpris de savoir combien de clients demandent si un tel programme existe.
Cela créé véritablement un lien entre un client et l’entreprise. Un programme fidélité, comme son nom l’indique, permet bien entendu de “récompenser” la fidélité des clients : ventes privées, offres spéciales, réductions en fonction du statut.
Le programme fidélité Alphapole à base de points
Le programme de fidélité est aussi l’occasion de créer une actualité avec les clients. Vous les contactez ainsi pour leur signifier qu’ils ont gagné des points, qu’ils ont débloqué une nouvelle réduction ou un statut de membre. Grâce à cela, ils pensent plus souvent à l’entreprise et saisiront peut être l’occasion pour réaliser un achat.
Le compte client
Un site e-commerce peut difficilement se passer de compte client. Ces derniers voudront pouvoir vérifier le statut d’une commande, télécharger leur facture, enregistrer leurs coordonnées et préférences (livraison, facturation, cartes bancaires…) pour faciliter les prochains achats etc.
De même que pour le checkout, l’espace client est parfois contraint par la solution technique utilisée (Prestashop, WooCommerce, Shopify…). Il ne sera donc pas toujours possible, ou techniquement compliqué, donc financièrement assez cher, de fournir une interface 100% personnalisée.
Bien qu’il soit presque toujours possible d’offrir une expérience unique aux visiteurs, dans ce domaine, on peut s’en tenir à un design simple et fonctionnel :
espace facilement accessible depuis le menu,
facilité d’accès aux informations et modifications aisée lorsqu’utile,
accès aux commandes en cours et passées (avec téléchargement des factures),
informations sur le programme fidélité si applicable,
récupération du mot de passe (social login et magic link connect sont un plus).
Parmi les sites desquels je suis client, deux m’ont particulièrement impressionnés par leur design fonctionnel :
Lacoste vous accueille immédiatement dans “son club” en mettant en avant son programme fidélité. Le compte client est simple et épuré, tout en étant design.
SEOPress (outil de référencement) guide les clients grâce à la mise en avant de guides et d’éléments essentiels au démarrage de l’outil. Les autres options sont toujours à portée de main.
2FA
Si ce terme ne vous parle pas, il s’agit d’un acronyme signifiant Two-factor authentication, soit en français, l’authentification à deux facteurs.
Cela peut concerner entre autre le compte client. Il s’agit en fait de confirmer l’identité de la personne par une seconde méthode (la première étant en général le mot de passe). Cette seconde méthode passe en général par un de ces trois moyens :
envoi d’un code ou d’un lien de validation sur l’email préalablement connu de l’utilisateur,
envoi d’un code par SMS ou appel automatisé sur le numéro de téléphone préalablement connu de l’utilisateur,
validation depuis une application préalablement installée sur l’appareil de l’utilisateur.
L’email comme le SMS sont éligibles à l’autofill. Par exemple, sur macOS et iOS, si vous recevez un SMS contenant un jeton de sécurité et que vous êtes sur la page vous demandant de rentrer ledit jeton, Safari vous pourra vous proposer de remplir le jeton automatiquement, sans même que vous ayez eu à consulter vos messages.
Pour cela, comme vous l’autofill des coordonnées et des informations de carte bancaire, il faut renseigner un attribut spécifique. Il n’y en a qu’un seul.
autocomplete="one-time-code"
Voilà, il me semble que nous avons fait le tour. N’hésitez pas à partager d’autres règles que j’aurais oublié. De plus, si vous avez des retours d’expérience sur le sujet, faites en part dans les commentaires, c’est toujours très intéressant.
]]>
En e-commerce, l'UX design est capital car il a un impact direct sur le taux de conversion de la boutique. Découvrons les règles d'UX indispensables.
Boucles JavaScript : maîtrisez les touteshttps://buzut.net/maitrisez-les-differents-types-de-boucles-javascript/2019-12-16T23:28:02.000Z2024-09-05T06:56:59.840ZLe JavaScript dispose d’une demi-dizaine d’instructions distinctes permettant d’effectuer une boucle sur une variable. Quelles sont les méthodes les plus adaptées aux différents types de valeurs ? Quelles sont les implications de telle ou telle méthode ? Dans quel contexte préférer une instruction plutôt qu’une autre ? Autant de questions auxquelles nous allons apporter une réponse.
Le JavaScript comporte de très nombreuses instructions permettant d’effectuer une boucle sur une valeur. Cependant, si nous considérons seulement celles dont c’est l’objet premier – en omettant celles dont la boucle est inhérente à leur fonctionnement (.map, .filter…) – nous en dénombrons exactement cinq :
for,
for of,
for in,
while,
do while.
À cela s’ajoute une méthode dont disposent de nombreux itérables : .forEach. Voyons donc quelles sont les différences fondamentales entre ces différentes instructions.
while, le basique
Le while est l’instructions de boucle la plus simple que l’on retrouve en JavaScript. Cette instruction ne prend qu’un seul argument : une condition. Tant que la condition retourne true, la boucle se poursuit.
Toute variable à initialiser, valeur à actualiser, test à effectuer (hors celui de la condition) doivent s’effectuer avant ou dans le corps de la boucle.
Étant donné que la condition attendue est une expression, on peut tout à fait y placer une expression qui modifie notre structure de contrôle, comme incrémenter notre variable par exemple.
Vous avez peut être remarqué que la comparaison est passé d’un inférieur ou égal à un exclusivement inférieur à. En effet, la condition est exécutée avant chaque tour de boucle. C’est d’ailleurs pour cela que le premier exemple compte à partir de zéro tandis que le second commence à un.
De ce fait, la première fois que la condition est évaluée, i vaut 0, il est incrémenté et le corps de la boucle est exécuté. Lors de la dernière exécution, i vaut 9, est incrémenté et la boucle s’exécute. Enfin, la condition est de nouveau exécutée mais i vaut cette fois 10 donc la boucle s’arrête là.
for, le classique
for est la boucle classique telle qu’on la trouve dans l’ensemble des langages issus de la famille du C. Elle prend en paramètres trois expressions optionnelles, séparées par des points virgules :
initialisation : valeur à initialiser avant le démarrage de la boucle,
condition : condition qui détermine si la boucle continue ou s’arrête, elle est évaluée avant chaque tour de boucle,
expression finale : expression évaluée après chaque tour de boucle.
const test = 5;for (let i = 0; i < test; i++) { console.log(i); // 0, 1, 2, 3, 4}
Étant donné que chacun des arguments est optionnel, on peut par exemple décider de n’utiliser que la condition, ce sera alors sur une variable définit en amont ; ou alors ne pas utiliser l’expression… Bref, tout est possible.
Il suffit pour cela d’utiliser l’instruction vide (empty statement). Cette dernière permet simplement de remplir la case dans laquelle JavaScript attend une réponse. Par exemple, dans le cas où l’on voudrait ignorer le paramètre d’initialisation.
const test = 5;let i = 0;for (; i < test; i++) { console.log(i); // 0, 1, 2, 3, 4}
Le résultat est exactement le même que précédemment, même si l’exemple est tout à fait idiot, c’est possible. Par ailleurs, comme chacun de ces arguments doit être une expression – c’est à dire un élément qui retourne une valeur – on peut en tirer parti pour mettre en place un contrôle plus riche.
Par exemple, vous lirez (ou avez lu) qu’il est conseillé pour des raisons de performances de pré-calculer la longueur d’un array dans le paramètre d’initialisation plutôt que de le recalculer à chaque tour de boucle.
const test = [1, 2, 3, 4, 5];// ainsi, il vaut mieux remplacer celafor (let i = 0; i < test.length; i++) { console.log(i); // 0, 1, 2, 3, 4}// par celafor (let i = 0, length = test.length; i < length; i++) { console.log(i); // 0, 1, 2, 3, 4}
Au delà de l’exemple, cette optimisation n’est plus utile dans la plupart des cas. En effet, presque tous les moteurs JavaScript possèdent un compilateur JIT (just in time ou compilation à la volée), lequel sait optimiser ce genre de cas tout seul.
do...while, la tête à l’envers
Celle-ci est la petite sœur de la boucle while, son fonctionnement est sensiblement le même mais l’évaluation de la condition est inversée. La boucle s’exécute puis évalue la condition.
Si cette dernière retourne true alors la boucle continue, sinon, elle s’arrête. Si on transpose les exemples du while, le premier exemple donne le même résultat, mais dans le second, la boucle s’exécutera une fois de plus.
const countUntil = 10;let i = 0;do { console.log(i++); // 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10} while (i <= countUntil);
Ici, i est incrémenté dans le corps de la boucle, cela ne change rien au résultat.
En revanche, lorsque l’incrément se fait directement dans la condition, on part de zéro et on compte jusqu’à dix, alors même que le condition est un inférieur exclusif.
En effet, la boucle s’exécute avant d’évaluer la condition. Ainsi, lors du premier tour, i est à 0, la boucle poursuit jusqu’à ce que i soit à 10, alors la condition est de nouveau évaluée, elle est toujours à true car i peut-être inférieur ou égal à 10, donc i est incrémenté, passe à 11 et une nouvelle exécution de boucle est validée. i valant maintenant 11, la prochaine condition stoppe la boucle.
for..in et for..of pour les objets
La boucle for..in permet de looper sur les propriétés énumérables et non Symbol d’un objet.
Sa cousine, la boucle for..of est plus récente car il s’agit d’une addition au langage à partir de l’ES2015. Cette dernière loop sur les valeurs d’un itérable (objet, tableau, Set, Map, NodeList…).
const person = { firstname: 'Mickey', lastname: 'Mouse', nickname: 'Mick'};for (const val of person) { console.log(val); // "Mickey", "Mouse", "Mick"}
Il est même possible d’itérer sur un String, cela se fera sur chacune des lettres du mot. Cette structure peut aussi s’avérer très utile pou itérer sur des TypedArray.
Bien que ces deux instructions semblent très similaires, certaintes différences d’envergure existent :
for..in liste les clefs tandis que for..of liste les valeurs,
for..in et for..of n’itèrent pas sur les mêmes choses. Tandis que for..in boucle sur toutes les propriétés énumérables autre que Symbol, for..of parcourt l’ensemble des données contenues dans l’objet itérable.
Cette seconde différence mène à des résultats parfois non prévus par le développeur.
const testLoop = [1, 2, 3];testLoop.test = 'hohohooo';// On loop sur les itérables du tableaufor (const val of testLoop) { console.log(val); // 1, 2, 3}// On loop sur toutes les propriétés énumérables non Symbolfor (const propt in testLoop) { console.log(propt); // "0", "1", "2", "test"}
Autre exemple qui mène souvent à des résultats imprévisibles : lors de l’usage de bibliothèques augmentant certains types natifs et objets.
// Méthode custom sur le type ArrayArray.prototype.customArrMethod = function() {};Object.prototype.customObjMethod = function() {};const testLoop = [1, 2, 3];for (const val of testLoop) { console.log(val); // 1, 2, 3}for (const propt in testLoop) { console.log(propt); // "0", "1", "2", "customArrMethod", "customObjMethod"}
customObjMethod est également listé car un Array est aussi un Object. customObjMethod fait donc dans parti du prototype de testLoop.
On comprend bien que si l’on utilise for..in pour récupérer les valeurs en faisant testLoop[propt] sans prendre ses précautions, on peut aboutir à quelques bugs inattendus.
.forEach, la méthode fonctionnelle
Contrairement aux instructions de boucles vues jusqu’ici, .forEach est une méthode définie sur certains types natifs et objets. Cette méthode est disponible par défaut sur nombre d’objets natifs : Array, Set, Map, NodeList et DOMTokenList. Il est tout à fait possible de l’ajouter à vos propres objets, il suffit de manuellement l’implémenter.
Nous prendrons l’exemple du tableau car il s’agit du type le plus couramment utilisé avec le .forEach. Cette méthode exécute une fonction sur chacun des éléments de son itérable. Trois argument sont passés à la fonction callback :
Optionellement, il est également possible de spécifier le this à utiliser dans le callback :
array.forEach((el) => { … }, thisArg);
Pour un bon nombre de cas d’usage, cette méthode est souvent plus commode que les instructions vues précédemment. En revanche, comme nous le verrons par la suite, certains de ces comportements diffèrent des autres instructions de boucle.
Instructions de contrôle
Il existe deux instructions spécifiques permettant de contrôler le comportement des boucles :
break pour l’interrompre,
continue pour passer directement à l’itération suivante.
Ces deux instructions permettent d’éviter des calculs inutiles lorsqu’il n’est pas nécessaire de continuer l’exécution d’un tour de boucle ou qu’il n’est pas nécessaire de poursuivre les itérations.
Dans l’exemple suivant, nous cherchons un nombre dans une liste. Une fois que nous avons trouvé ce nombre, il n’est pas utile de poursuivre la boucle, ce sont des cycles de processeur perdus (donc du temps d’exécution).
let index = 0;const needle = 5;const haystack = [1, 2, 3, 4, 5, 6, 7, 8, 9];for (let i = 0; i < haystack.length; i++) { if (needle === haystack[i]) { index = i; break; }}
Dans le cas présent, nous n’avons que peu de valeurs et nous n’effectuons aucun calcul lourd, la différence est donc imperceptible, mais pour un grand set de données ou une exécution complexe dans la boucle, la différence peut être énorme !
Dans le même ordre d’idée, il arrive parfois qu’il ne soit pas pertinent de poursuivre l’exécution d’un tour de la boucle. Dans ce cas, continue permet de passer directement au tour suivant.
// méthode naïve de calcul de la suite de fibonaccifunction fibonacci(n) { if (n < 1) return 0; if (n <= 2) return 1; else return fibonacci(n - 1) + fibonacci(n - 2);}// on décide de trouver le nombre de fibonacci pour tous les nombres pairs entre x et y// (x et y non inclus)const x = 10;const y = 30;for (let i = x; i < y; i++) { // si c'est impair, on passe directement au tour suivant if (i % 2 !== 0) continue; console.log(fibonacci(i));}
Cet exemple est quelque peut tiré par les cheveux, on peut en effet dans ce cas utiliser directement un if pour n’appeler la fonction que si la valeur nous convient. Mais lorsque le corps de la boucle comporte beaucoup de code, cela nous évite des indentations nuisibles à la lisibilité.
Label de bloc
En plus des deux instructions que nous venons de voir, il est possible d’utiliser l’instruction de bloc avec un label. Assez peu connue des développeurs, cette instruction permet d’attribuer un nom à un bloc de code.
break termine par défaut la boucle immédiate, mais si plusieurs boucles sont imbriquées, le break ne met pas fin à la boucle parente. En donnant un label à la boucle parente, c’est possible.
Dans l’exemple suivant, on cherche à nouveau à identifier une valeur précise dans un tableau, mais ce dernier est cette fois imbriqué. Il nous faut donc trouver la position dans les tableaux parent et enfant.
let indexParent = 0;let indexChild = 0;const needle = 5;const haystack = [[1, 2, 3], [4, 5, 6], [7, 8, 9]];outer: for (let i = 0; i < haystack.length; i++) { for (let k = 0; k < haystack[i].length; k++) { if (needle === haystack[i][k]) { indexParent = i; indexChild = k; break outer; } }}
Sans le label, quand bien même la valeur serait trouvée dans le premier tableau, nous devrions itérer sur toutes les valeurs du parent. Le label nous permet ici d’indiquer à break que nous voulons stopper une boucle de plus haut niveau (en plus de la boucle courante).
return, the end
Le return met fin à la fonction courante (et retourne optionnellement une valeur). À ce titre, il peut être utilisé pour mettre fin à une ou plusieurs boucles.
Si la ou les boucles sont dans une fonction, la fonction s’arrête alors à ce stade, si nous sommes dans un contexte global ou dans un module, aucun autre code ne sera exécuté.
const needle = 5;const haystack = [[1, 2, 3], [4, 5, 6], [7, 8, 9]];function findNeedle(needle, haystack) { for (let i = 0; i < haystack.length; i++) { for (let k = 0; k < haystack[i].length; k++) { if (needle === haystack[i][k]) { return { indexParent: i, indexChild: k }; } } }}findNeedle(needle, haystack);
Dans le cas du .forEach, étant donné qu’à chaque itération, une nouvelle fonction est lancée, le return ne mettra fin qu’à l’itération courante, à la manière du continue pour les autres structures de boucles.
Il n’est tout simplement pas possible d’arrêter un .forEach.
Synchrone et asynchrone
C’est ici que commencent les choses sérieuses ! Comme vous le savez, le JavaScript est un langage asynchrone. Cela veut dire que le code ne s’exécute par forcément de manière linéaire de haut en bas.
En l’absence totale de code asynchrone, quelle que soit l’option de boucle choisie, tout se passe sans surprise, le code est exécuté linéairement.
Prenons pour exemple le calcul d’une suite de Fibonacci des nombres entre 0 et 40 (plus que 40 risque vite de faire planter votre navigateur).
// on utilise fibonacci pour avoir une fonction qui prend un peu de tempsfunction fibonacci(n) { if (n < 1) return 0; if (n <= 2) return 1; else return fibonacci(n - 1) + fibonacci(n - 2);}// on démarre le chronoconst timeStart = Date.now();for (let i = 0; i < 40; i++) { // vous pouvez afficher les valeurs returnées si vous le souhaitez // console.log(fibonacci(i)); fibonacci(i)}// temps total d'exécution,// si le code était asynchrone, on serait proche de zéroconsole.log((Date.now() - timeStart) / 1000);
Le résultat est le même avec toutes les autres boucles ainsi que le .forEach.
Il y a plusieurs manières de gérer du code asynchrone, les plus utilisées sont les callbacks, les Promises et les structures async/await. L’exécution du code asynchrone est alors immédiatement lancée et le moteur JavaScript passe à la suite du code, sans attendre le résultat de l’opération.
function wait() { return new Promise((resolve) => { setTimeout(resolve, 1000); });}for (let num of [1, 2, 3]) { wait().then(() => console.log('wait is over')); console.log(num);}console.log('loop over');// 1// 2// 3// "loop over"// "wait is over"// "wait is over"// "wait is over"
On se rend compte ici que la boucle est intégralement exécutée avant même que la première Promise soit résolue. Ce comportement est tout à fait normal car nous n’avons pas indiqué au moteur JS d’attendre le retour du code asynchrone afin de poursuivre son exécution. Le code s’exécute ici exactement de la même manière qu’il le serait en dehors d’une boucle.
function wait() { return new Promise((resolve) => { setTimeout(resolve, 1000); });}async function test() { for (let num of [1, 2, 3]) { await wait().then(() => console.log('wait is over')); console.log(num); } console.log('loop over');}test();// "wait is over"// 1// "wait is over"// 2// "wait is over"// 3// "loop over"
Cette fois ci, la temporalité du code est bien respectée. L’instruction await fait que la boucle attend la résolution de la promesse lors de chaque itération. Seulement une fois la promesse résolue, la boucle reprend son cours. Ce comportement se vérifie pour l’ensemble des instructions de boucle.
En revanche, dans le cas de la méthode .forEach, la fonction callback est appelée avec l’ensemble des valeurs sans considération pour la valeur de retour du callback, et donc sans attendre la résolution de la promesse.
Voici une implémentation simplifiée de la méthode .forEach :
Array.prototype.forEach = function (callback) { // ici, this fait référence à l'objet représenté, // donc au tableau considéré for (let index = 0; index < this.length; index++) { // le callback est appelé, ignorant les comportements asynchrones callback(this[index], index, this); }};
De par sa nature même, .forEach est conçu pour ses effets de bords et non pour sa valeur de retour. Cette dernière ne peut d’ailleurs pas être récupérée (array.forEach() retourne toujours undefined).
function wait() { return new Promise((resolve) => { setTimeout(resolve, 1000); });}function test() { [1, 2, 3].forEach(async (num) => { console.log('before await'); await wait().then(() => console.log('wait is over')); console.log(num); }); console.log('loop over');}test();// "before await"// "before await"// "before await"// "loop over"// "wait is over"// 1// "wait is over"// 2// "wait is over"// 3
Le await est bien respecté au sein de la fonction callback. Néanmoins, la boucle est intégralement exécutée avant même la résolution de la première promesse.
Il est toutefois possible de lancer l’ensemble des promesses et d’attendre qu’elles soient ensuite toutes résolues afin d’exécuter la suite d’un programme.
// tous les traitements sont lancés en parallèle et placés dans un arrayconst promises = [];array.forEach(el => promises.push(asyncFunction(el)));// lorsque l'ensemble des traitements ont terminé// on peut déclencher la suitePromise.all(promises).then(() => { …});
Dans ce dernier cas, on préférera parfois le .map au .forEach car il permet de directement récupérer les valeurs.
Aucune des manières de faire n’est meilleure qu’une autre. Les quatre instructions de boucle sont fonctionnellement identiques, elles ne diffèrent que par les instructions qu’elles acceptent et le moment auquel elles évaluent la condition.
.forEach diverge de par sa nature et son comportement avec l’asynchrone. Il sera parfois bénéfique de pouvoir lancer l’ensemble des promesses sans en attendre le résultat. On tire ainsi parti de la puissance de la nature asynchrone du JavaScript pour paralléliser les tâches qui requièrent de l’I/O.
Dans d’autres circonstances, on voudra attendre la résolution d’un traitement précédent afin de déclencher le suivant, cela peut être le cas pour des tâches consommatrices en CPU, RAM ou réseau et afin de ne pas surcharger la machine.
La richesse et la souplesse du langage nous offrent de nombreuses possibilités pour travailler avec les boucles et les traitements asynchrones. Il ne tient qu’à nous, développeurs, de tirer profit de cette souplesse pour écrire des programmes puissants et performants.
]]>
Il existe une multitude de façon de "looper" sur des valeurs en JavaScript. Les maîtriser et en connaître les différences (synchrone/asynchrone, Promises) vous permettra d'écrire un code plus clair et plus efficace.
Bien commenter son codehttps://buzut.net/bien-commenter-son-code/2019-12-02T09:17:24.000Z2024-09-05T06:56:59.836ZCommenter son code, c’est un cadeau que vous envoyez dans le futur. Peut-être pour le prochain développeur qui maintiendra le projet ou vous donnera un coup de main, mais probablement surtout pour votre futur vous.
En effet, ce qui est limpide dans votre esprit à l’instant où vous écrivez le code, sera clairement plus opaque lorsque quelques semaines ou mois se seront écoulés. La documentation – en plus d’un code bien structuré – participe activement à faire de votre base de code dans son ensemble un “bon code”.
Chacun a sa propre définition du bon code, mais un bon code est toujours clair
Les commentaires inline
Il ne s’agit pas d’expliquer ligne par ligne ce que fait le code, loin de là. Si un petit commentaire inline s’avère parfois utile, le code ne doit pas en être truffé.
Ce type de commentaire permet d’expliquer au plus près du code une particularité de ce dernier, la raison d’être d’un détail ou le pourquoi de l’emploi d’une méthode qui ne semble par forcement évidente.
function humanDate(date, locales) { … const dateYear = dateObj.toLocaleString(locales, { year: 'numeric' }); const dateMonth = dateObj.toLocaleString(locales, { month: 'numeric' }); const dateDay = dateObj.toLocaleString(locales, { day: 'numeric' }); const now = new Date(); const nowYear = now.toLocaleString(locales, { year: 'numeric' }); const nowMonth = now.toLocaleString(locales, { month: 'numeric' }); const nowDay = now.toLocaleString(locales, { day: 'numeric' }); … // set year only if not the same year as now if (dateYear !== nowYear) options.year = 'numeric'; // if today, display relative time if (dateYear === nowYear && dateMonth === nowMonth && dateDay === nowDay) { … } …}
Ici, on comprend tout de suite l’intérêt des commentaires inline, ils précisent de manière univoque le rôle des if, sans qu’il faille méthodiquement se plonger dedans à la lecture pour comprendre ce que font ces conditions.
Function level, c’est là que ça se passe
Les commentaires inline permettent d’apporter du contexte, mais c’est bien les commentaires au niveau des fonctions qui représentent la réelle plue-value des commentaires.
Ils constituent une documentation en eux-même. De nombreux langage ont leur standard, en JavaScript, il s’agit de JSDoc.
Grâce à ça, il n’est la plupart du temps même pas utile de se pencher dans la fonction elle-même, à la simple lecture du commentaire, on sait tout de la fonction :
ce qu’elle fait,
les paramètres qu’elle accepte,
la réponse qu’elle retourne.
Le JSDoc est composé d’un bloc, commençant par /**, ensuite chaque ligne commence par un * et enfin, le bloc est fermé comme n’importe quel commentaire multi-lignes.
Ce format permettra à votre éditeur d’immédiatement reconnaître le JSDoc et de lui appliquer la coloration syntaxique. Malheureusement, highlight.js, que j’utilise sur ce site, échoue dans cette mission.
Expliquer ce que fait la fonction
La première chose que fait un commentaire JSDoc est d’expliquer en langage humain ce que fait la fonction.
Bien qu’aucun format ne soit imposé, on tente tout de même de rester concis. Cependant, si cela est nécéssaire, l’explication peut être écrite sur plusieurs lignes. C’est bien plus propre et lisible que d’avoir une seule ligne de 10Km de long !
Enfin, c’est une question de goût, mais je m’astreins à ce que cette phrase commence toujours par une majuscule, cela indique qu’il s’agit d’une vraie phrase construite avec une grammaire valide. Je ne l’utilise pas mais il existe même une règle ESLInt pour ça.
Les paramètres
On entre ici dans le cœur de la documentation : quels sont les paramètres que la fonction prend en entrée ?
Ce sujet est plus épineux qu’il ne paraît. En effet, un paramètre possède un type contraint ou peut en accepter plusieurs, il peut être requis ou optionnel, avoir une valeur par défaut, accepter certaines valeurs… Voyons comment exposer ces contraintes de manière claire.
Pour spécifier qu’on documente un paramètre, on commence toujours la ligne par @param. Ensuite, entre accolades, le type du paramètre, puis son nom et, optionnellement, une description. Notez d’ailleurs que cette phrase peut être séparée du nom du paramètre par un tiret.
De nouveau, j’ai pour convention de laisser un espace entre le type du paramètre et les accolade (comme dans les objets JavaScript) et de mettre la première lettre du type en majuscule. Rien ne vous y oblige, mais je trouve cela plus clean.
Par ailleurs, la liste des types n’est pas restreinte aux types natifs JavaScript. Si vous souhaitez dire que le paramètre est un entier, vous pouvez parfaitement mettre Integer car c’est plus précis que le simple type natif Number.
Cela dit, vous pouvez également le préciser en commentaire.
* @param { Number } age Age of the user as an integer
Lorsque je documente des fonctions en front, lesquelles reçoivent des éléments du DOM, je trouve qu’il est plus clair d’indiquer directement de quel type d’élément il s’agit plutôt que de vaguement indiquer qu’il s’agit d’un objet.
Vous pouvez à ce titre regarder comment je documente les fonctions dans ƒlightDom, dont l’exemple ci-dessous est tiré.
/** * Toggle a class on an element * @param { HTMLElement } el * @param { String } className */export function toggleClass(el, className) { if (hasClass(el, className)) removeClass(el, className); else addClass(el, className);}
Multi-types
C’est un cas qui arrive, un paramètre peut recevoir des valeurs d’un type ou d’un autre, par exemple un nombre ou une chaîne de caractère (laquelle peut représenter un nombre).
/** * Send an email via SMTP * @param { (String | Array) } to * @param { String } text * @param { String } subject * @return { Promise } */function sendMailWithSMTP(to, subject, text) { …}
Il est possible qu’on ne puisse connaître à l’avance le type ou que tous les types soient acceptés, dans ce cas, comme dans les REGEX, on utilise le symbole *.
* @param { * } response Response of the previous function call
Dans le cas où le paramètre accepte un type donné ou null, on le signifie à l’aide d’un ?.
* @param { ?Integer } age
Paramètre optionnel et par défaut
Si le paramètre est optionnel, on l’entoure de crochets.
/** * Send client err if it's validation error or log if it's a native or low level error * @param { Object } err error object * @param { Object } [res] */function handleError(err, res) { …}
Dans cette fonction, il est clair que la paramètre res n’est pas obligatoire. Il existe également des cas où, sans passage du paramètre, on lui assigne une valeur par défaut.
/** * Signup a new user * @param { String } name * @param { String } password * @param { Integer } age * @param { String } [gender=male] */function createUser(name, password, age, gender = male) { …}
Il est à noter qu’il n’est pas obligatoire que le paramètre ayant une valeur par défaut soit optionnel, c’est cependant souvent le cas, question de logique.
Type valide et…
L’autre question à laquelle on doit souvent faire face est la restriction du paramètre, voyons quelques exemples.
// la valeur doit être une des options de la liste* @param { String="male, female" } gender// limiter le nombre de caractères d'un string* @param { String{..25} } password// ou l'encadrer entre 10 et 25 par exemple* @param { String{10..25} } password
La logique sera la même pour un nombre, mais cela précisera sa valeur, pas sa longueur. Un bon exemple concerne les codes postaux français.
* @param { Integer{10000-99999} } zipcode
Documenter les objets
Lorsque l’on passe un objet en paramètre, il s’avère souvent utile de préciser son contenu. La logique reste la même que ce que nous avons vu jusqu’à maintenant.
/** * Signup a new user * @param { Object } user * @param { String } user.name * @param { String } user.password * @param { Integer } user.age * @param { String } user.gender */function createUser(user) { …}
Il existe une autre forme plus compacte, notamment utile lorsque l’on veut succinctement documenter un return.
* @param { Object.<name: String, age: Integer> }
Documenter les tableaux
La documentation des tableaux est assez proche de celle des objets. On déclare qu’il s’agit d’un tableau puis les types qu’il contient.
/** * Compute student's mean grade * @param { Object[] } students * @param { String } students[].name * @param { Number } students[].mathMean * @param { Number } students[].frenchMean */function computeMean(students) { …}
De même que pour les objets, il existe une notation plus compacte,
// dans le cas où le tableau contient un unique champ* @param { Array.<String> } studentsNames// dans le cas où il est composé d'objets* @param { Array.<Object> } studentsNames// on peut aussi spécifier le contenu de l'objet* @param { Array.<{ name: String, age: Integer }> } studentsNames
Documenter les fonctions
N’est-ce pas déjà ce dont nous sommes en train de parler
C’est probablement ce que vous vous demandez. Cependant, il s’agit ici des fonctions que nous passons en argument. Comme vous le savez, en JavaScript, les fonctions sont des citoyens de premier rang, les fonctions peuvent donc accepter des fonctions en paramètres et retourner d’autres fonctions en résultats.
Dans le cas le plus simple, on se contente de déclarer le type comme étant Function. Cependant, un fonction acceptant elle-même des paramètres, il peut être utile de préciser quels sont ces derniers. Notamment lorsqu’on définit un callback.
/** * Get a user from database * @param { String } userId * @param { Function(err<Error | Null>, user<Object>) } callback */function getUser(userId, (err, user) => { …})
Alternativement, vous pouvez préciser les paramètres de la fonction dans la description.
* @param { Function } callback { err, width, ratio, color }
Nombre de paramètres variable
On utilise pour cela la même syntaxe que le spread operator de JavaScript. ...parameter. Un exemple concret acceptant un nombre variable de paramètres pouvant être de deux types diférents.
/** * Check if all DOM elements exist, call ƒn with said els if they exist * @param { Function } fn * @param { ...HTMLElement | ...NodeList } */export function callFnWDomElsIfExist(fn, ...els) { …}
Combiner les tous !
Les déclarations sont tout à fait combinables, ainsi vous pouvez déclarer des types composés.
// date ou array de dates de rendez-vous, également optionnel* @param { Date | Date[] } [appointmentDates]// tableau pouvant contenir des objets ou des strings* @param { Array.<String|Object> } paramsList// paramètre optionnel d'un objet/** * Signup a new user * @param { Object } params * @param { String } params.[gender] */// tableau imbriqué/** * Compute student's mean grade * @param { Object[] } students * @param { String } students[].name * @param { Number[] } students[].mathGrades * @param { Number[] } students[].frenchGrades */
La seule limite est votre imagination (et la complexité de votre modèle de données).
Les classes
Personne n’a oublié que l’ES6 nous a donné les outils pour déclarer des classes. Si vous n’êtes pas au parfum, n’hésitez pas à jeter lire ou relire mon article dédié à la programmation objet en JavaScript.
Il arrive donc que nous ayons à documenter des classes. Dans une classe, on peut documenter trois niveaux :
la classe dans son ensemble,
le constructeur,
les méthodes.
Le constructeur et les méthodes se documentent de manière classique, comme n’importe quelle fonction. En revanche, il existe des mots-clefs spécifiques pour la classe.
/** * @class * @classdesc Create an error for bad HTTP request (contain http status to send err back to the client) */class BadRequestError extends Error { …}
D’après la documentation, il est possible de décrire sur la première ligne ce que fait le constructeur, je trouve cependant plus intuitif et direct de le documenter directement à l’intérieur du code de la classe.
Les valeurs de retour
Jusque là, nous avons documenté les paramètres des fonctions. Cependant, dans la plupart des cas, une fonction retourne une valeur. Si ce n’est pas le cas, c’est que votre fonction est impure, qu’elle a donc des effets de bord. C’est parfois inévitable, mais c’est à éviter au maximum dans un contexte de programmation fonctionnelle.
Dans le cas où la valeur de retour est simple, il suffit de préciser le type en utilisant @return.
/** * Get the first matching element * @param { String } selector CSS selector * @return { HTMLElement } */export function find(selector) { return document.querySelector(selector);}
En outre, une fonction peut retourner différentes valeurs selon le contexte, par exemple un nombre en cas de succès ou une erreur en cas de problème. Là encore, la logique vu jusqu’alors s’applique.
* @return { (Number | Error) }
Par ailleurs, on a de plus en plus recours aux promesses, la fonction retourne donc une promesse, laquelle peut être dans plusieurs états :
en attente,
résolue,
rejetée.
Dans le cas le plus simple, on spécifie simplement que la fonction retourne une promesse. On sait dès lors, car c’est la nature même d’une promesse qu’elle peut réussir ou échouer.
/** * Get comments for a given article id (w/ authors names) * @param { Number } articleId * @return { Promise } */function getForId(id) { …}
Cependant, dans de nombreux cas, il est souhaitable de documenter les différents états de manière plus précise. Dès lors, on adopte la même syntaxe que pour documenter les objets.
Nous avons vu comment commenter la plupart des cas que vous rencontrerez. Les commentaires vous permettent non seulement d’améliorer votre compréhension du code et de relire et maintenir plus vite et efficacement une base de code, mais aussi de générer une vraie documentation.
Par exemple, dans le cas d’une bibliothèque à destination d’autres développeurs, vous pouvez générer une documentation grâce à JSdoc. Une application en CLI vous permet de dynamiquement générer la doc liée à votre projet. C’est ce que j’utilise pour la documentation de ƒlightDom.
Dans la même veine, vous pouvez documenter vos API avec APIdoc. C’est la solution que j’utilise pour documenter les endoints de Jamments.
]]>
Commenter le code est une bonne pratique, mais c'est surtout un indispensable qui vous fera gagner énormément de temps. Le premier bénéficiaire, c'est vous ! Commenter c'est documenter, voyons comment.
Workflow multi-machines : pourquoi et comment ?https://buzut.net/travailler-sur-plusieurs-machines-pourquoi-comment/2019-10-21T23:31:50.000Z2024-09-05T06:56:59.840ZSi l’on veut être productif, il faut que nos outils le soient aussi. Pour ma part, en plus de l’environnement logiciel et matériel de la machine principale déjà expliqué dans un précédent article, j’estime que plusieurs machines sont nécessaires à ma productivité.
En tant que développeurs, nos outils sont de deux catégories :
les outils logiciel,
les outils matériel.
Que l’on me donne six heures pour couper un arbre, j’en passerai quatre à préparer ma hache.
Lincoln
Il ne s’agit pas là de consumérisme débridé, j’essaye toujours au mieux de faire durer mon matériel.
La tablette
De nombreuses personnes ont aujourd’hui délaissé l’ordinateur pour ne plus utiliser que tablette ou téléphone. Pour nous, développeurs, ce n’est tout simplement pas envisageable.
Il est possible de travailler sur tablette dans certaines conditions, mais il est tout bonnement impensable d’en faire sa machine de travail principale.
Néanmoins, une bonne partie de notre travail consiste à faire de la veille et à se former. Cette partie est donc principalement constituée de lecture. Et pour la lecture une tablette est idéale.
J’ai donc un iPad qui me sert tous les jours pour faire ma veille, j’y lis Haker News, le Journal du Hacker, Smashing Magazine, CSS Tricks etc. Ces moments de lecture - qui font partie intégrante d’une journée de travail - sont tout de même plus confortables dans un canapé, ou même dehors quand le temps le permet.
On passe en effet déjà énormément d’heures assis à notre bureau, changer un peu d’endroit et de position ne peut que nous faire le plus grand bien.
La seconde machine
Certains ont un ordinateur fixe en machine principale, ce qui n’est pas mon cas, car je bouge beaucoup.
Ma machine de développement principal est un MacBook Pro 15”. J’en suis très content et, la plupart du temps, il fait office d’unité centrale, posé sur un bureau, branché sur deux écrans externes et relié à un clavier ainsi qu’à une souris.
Cette machine est confortable et puissante. Son seul problème est qu’elle est assez volumineuse et comme elle est toujours branchée, avec des fenêtres réparties sur trois écrans, je suis toujours réticent à la bouger si ce n’est pas pour partir (déplacement, voyage…).
J’apprécie donc d’avoir une deuxième machine, un ordinateur plus compact et léger. Je m’en sers lorsque je dois brièvement partir pour un rendez-vous ou pour travailler hors du bureau.
S’il fait beau et que je veux m’installer dehors, ou le soir pour écrire un article depuis le canapé ou mon lit. Cette machine n’est pas nécessairement puissante. J’utilise un Dell XPS qui a presque dix ans. Il tourne sous Solus OS et fonctionne à merveille.
Gérer la diversité
L’inconvénient de jongler entre plusieurs machines, c’est qu’on ne retrouve pas toujours tout si l’on n’est pas bien organisé.
Fort heureusement, l’époque où l’on tentait de rester synchronisé à coup de clef USB et de pièce jointe d’email est révolue.
Il y a 3 composantes que j’aime avoir à portée de main et synchronisées sur tous mes appareils :
mes favoris,
mes emails, calendrier et contacts,
mes documents (principalement sur les ordinateurs).
Emails, contacts, calendriers et favoris
Je n’ai pas mentionné le smartphone jusque là, mais c’est une évidence, tout le monde en a un, et en plus de me servir pour les emails, je l’utilise pour lire lorsque j’ai des temps morts.
J’utilise principalement Firefox en navigateur et Safari sur mes appareils iOS. Je ne suis pas fan des favoris des navigateurs, ça manque un peu d’organisation pour moi.
Pour cela, j’utilise Shaarli avec un thème material design, car le thème d’origine n’est pas à mon goût. Grâce à cela, j’ai mes favoris sur absolument tous mes appareils, et même ceux qui ne sont pas à moi, car il s’agit d’un site internet.
Les contacts et le calendrier sont synchronisés par NextCloud. Les protocoles sont des standards, donc ça peut se synchroniser avec à peu près n’importe quoi, c’est la beauté des standards. Idem pour l’email, imap/smtp, ça se synchronise sur tous les clients.
Synchro des fichiers
Là où ça se complique, c’est pour les documents. J’ai mentionné Nextcloud, je l’utilise pour les documents également. Il est dispo sur Linux, Mac et PC, donc pas de problème à ce niveau là.
Il y a aussi la possibilité de monter le disque en disque distant, à nouveau, c’est du standard : WebDAV. Vous n’aurez alors rien à installer si votre système le supporte (c’est le cas de tous les OS principaux). En revanche, notez que les performances ne sont pas aussi bonne et vous ne pouvez pas écrire sur le disque en étant hors connexion.
NextCloud (ou les drives de manière générale) sont vraiment très pratiques car leur usage est transparent. En revanche, dès lors que vous avez de très nombreux petits fichiers, ça devient un peu moins efficace.
Je désactive donc la synchro de tous les dossiers qui s’appellent “Code” - j’en ai en général un par projet ainsi que des “node_modules”. Ils sont de toute façons toujours dans “Code”, mais sait-on jamais.
Dès qu’il s’agit de code, Git prend la relève avec Gogs comme serveur et interface web. Mes deux ordinateurs partagent la même clef ssh, donc je suis authentifié de la même façon qu’il s’agisse du portable Mac ou Linux.
Il faut faire bien attention lorsque vous transférez cette clef d’une machine à l’autre. Soit on utilise un support chiffré, soit un efface bien la clef usb après usage. Et en aucun cas on ne s’envoie ça par email ou un cloud !
Une fois que l’on a tout cela de bien synchronisé, la dernière petite étape consiste à mapper les quelques fichiers de config que l’on veut garder synchro et qui vivent en dehors du cloud.
En ce qui me concerne, quelque coups de ln suffisent à garder synchronisé mon ssh config ainsi que mes hosts Ansible. De cette manière, d’une machine ou d’une autre, je suis en mesure de me connecter à tous mes serveurs !
Les mots de passe
Les mots de passes sont des fichiers particuliers dans la mesure où ils nécessitent une attention accrue et une gestion très fine des accès.
Il n’est ni question d’avoir le même mot de passe partout, ni question de consigner sa liste de mot de passe dans un fichier sauvegardé sans plus de précautions.
J’utilise à cet effet un gestionnaire de mot de passe. De nombreux gestionnaires existent. J’ai pour ma part choisi les standards avec le chiffrement via GPG et je les fonctionalités propres à la gestion de mot de passe via le logiciel cross-plateforme open source QtPass.
Avec QtPass, un fichier est créé pour chaque site ou logiciel, avec toutes les informations afférentes. Il est possible de préciser dans quel répertoire stocker les mots de passe et ainsi les synchroniser sur le cloud de manière totalement sécurisée : sans le mot de passe “maître”, rien n’est lisible.
Par ailleurs, si j’ai besoin de déchiffrer l’un de ces fichier, je peux le faire depuis n’importe quelle machine ayant GPG installé. Je ne suis pas bloqué avec un gestionnaire en particulier. QtPass m’offre une interface efficace, spécifiquement pensée pour la gestion des mots de passe et m’évite d’utiliser la ligne de commande dans cette tâche quotidienne.
En revanche, je ne peux pas accéder à mes mots de passe depuis ma tablette ou mon mobile. Il est peut être possible de mettre cela en place, mais n’en n’ayant pas le besoin, je n’ai pas effectué de recherches.
Conclusion
Si les appareils sont différents, il n’est pas forcement possible de répliquer l’environnement de partout. Cependant, de nombreux logiciels sont multi-plateformes (Windows, macOS, Linux).
Par exemple, pour ce qui concerne la programmation, mon shell bash et mon éditeur de code, Atom, ont exactement les mêmes configurations sur toutes mes machines.
Le reste est bien synchronisé et accessible depuis tous mes devices, sans aucun accroc depuis de nombreuses années. Testé et approuvé !
N’hésitez pas à partager vos outils et votre organisation ou à exprimer des besoins particuliers dans les commentaires.
]]>
Si vous jonglez entre plusieures ordinateurs, tablettes et smartphones, vous savez qu'avoir ses données toujours à disposition représente un énorme gain de productivité. Voyons comment maintenir tous vos appareils synchronisés.
Les modules JavaScript indispensableshttps://buzut.net/modules-javascript-indispensables/2019-09-01T11:17:13.000Z2024-09-05T06:56:59.840ZL’un des motos de tout bon développeur est DRY, don’t repeat yourself. Pourtant, une très grosses partie de nos projets ont des besoins similaires : valider un email, uploader des fichiers…
À ce titre, conformément à un autre moto de tout bon développeur – ne pas réinventer la roue – on utilise des outils et modules déjà existants et éprouvés. Voici donc un petit listing des modules que j’utilise régulièrement.
Nous parlons ici de JavaScript, il va donc sans dire que tous ces outils se trouvent sur npm, le package manager du monde JS.
Par ailleurs, vous avez aussi très certainement vécu la situation où vous vous retrouvez à copier d’un projet à un autre des petits helpers ou lib maison. C’est donc peut-être le moment d’en faire un module npm et de le publier afin de pouvoir l’utiliser plus facilement.
À ce titre, certains modules de ce listing sont des modules que j’ai moi-même développé et mis à disposition de tous sur npm.
Modules front-end
Je parle ici des modules qui sont utilisés pour le front et se retrouvent dans le build final envoyé au navigateur du client.
humanTime est un module qui permet d’afficher des dates dans un format human readable. Le format s’adapte en fonction de la date – par exemple “il y a 37 mn” ou “le 24 décembre 2017”, selon la récence de la date – et des préférences de langue navigateur de l’internaute (ça repose sur l’API d’Internationalisation des navigateurs).
autoTimer est un petit module fournissant un timer automatiquement unbounced. C’est à dire que s’il est appelé plusieurs fois avant le timeout défini, seul le dernier appel sera exécuté. C’est très utile pour tout ce qui s’exécute suite aux fonctions d’évènements (frappe clavier, resize du navigateur…).
resize-image permet de compresser (et automatiquement cropper) des images dans le navigateur afin de pouvoir les uploader plus rapidement.
BigPicture est un module lightbox permetant de visualiser photos et vidéos. Il est léger et offre des transitions morphing de type scale to fit du plus bel effet.
similar to BigPicture, PhotoSwipe supports fullscreen and offers more controls over the gallery.
huge-uploader gère les uploads de très gros fichiers de manière intelligente en “coupant” le fichier et en l’envoyant par petits bouts. De cette manière, il est possible de mettre en pause l’upload et les erreurs du réseau ne mettent pas l’upload en échec.
ƒlightDom ou functional light DOM est une bibliothèque destinée à faciliter l’utilisation du DOM de manière fonctionnelle. Depuis que les navigateurs modernes nous permettent de nous passer de jQuery, on travaille souvent directement avec les API natives du DOM. Leur syntaxe est souvent lourde et non adaptée à la programmation fonctionnelle. Ce module permet donc d’adresser cette situation avec une API fonctionnelle et légère.
Fuse.js est un module extrêmement léger pour faire des recherches dans des tableaux ou objets de manière très performante. La recherche reste fonctionnelle malgré quelques fautes de frappe. À titre indicative, c’est ce qui est utilisé pour la recherche de ce blog.
Rough.js permet de dessiner (Canvas et SVG) dans un style “crayon”. Il possède de nombreuses formes prédéfinies mais ses possibilités sont illimités.
Base sur le précédent, RoughNotation permet de de créer des annotations de texte (entourer, barrer, sur-ligner, sous-ligner…) dans un style “main levée”.
Comme je travaille beaucoup avec Vue.js, il y a certains modules front forts utiles qui sont spécifiques à Vue. Les voici.
V-Hotkey permet de facilement binder des touches ou combinaisons de touches à un comportement. Pratique pour mettre en place des raccourcis clavier.
V-click-outside permet à un composant d’être averti lorsqu’un click est effectué à l’extérieur de celui-ci. On l’utilisera pour fermer un champ de recherche autocomplete, une lightbox ou mettre en pause un player vidéo.
V-Clipboard permet de copier un texte dans le presse-papier de l’utilisateur.
Modules back-end
Le but n’est pas ici de lister tous les modules que l’on utilise régulièrement en back, mais plutôt de mettre en évidence ceux qui sont pratiques et que l’on a pas tout de suite en tête.
Valider une adresse email est une opération que nous avons constamment à faire. Aussi simple que cela puisse paraître, il est possible d’appliquer plusieurs niveaux de vérification : validation syntaxique, vérification des enregistrements DNS et validation SMTP. Si la première étape se fait avec une simple REGEX, les autres permettent d’aller plus loin. isemail permet d’appliquer une simple vérification syntaxique, avec un algorithme plutôt avancé. email-domain-check vérifie si le domaine possède des enregistrements MX. Enfin, email-deep-validator vous fait la totale (REGEX, MX et SMTP) !
Express.js est le framework web de Node.js. Son usage n’est pas impératif mais il apporte son lot d’outils très utiles et aide à structurer le code dès lors que le projet n’est pas trivial.
knex.js est un SQL query builder. À ce titre, il permet simplement de gérer la plupart des bases de données SQL (MSSQL, MySQL, Postgres, SQLite). Ainsi, si vous changez de base de données en cours de route, votre code reste le même. C’est aussi également très pratique pour un projet qui veut offrir une compatibilité maximale à ses utilisateurs. C’est ce que j’utilise pour Jamments. On profite également d’une syntaxe familière pour ceux qui sont un peu allergiques au SQL.
mysqljs permet à l’inverse, d’écrire du SQL directement pour MySQL ou MariaDB. Il y a plusieurs clients possibles pour MySQL, mais celui-ci est mon préféré. Très performant, son API est simple et logique. On peut faire du bulk insert, streamer les résultats, profiter du pseudo UPSERT avec ON DUPLICATE KEY UPDATE… Il ne lui manque pour l’instant que les promises, mais un petit wrapper fait l’affaire dans 99% des cas.
bad-request-error est un constructeur d’erreur dédié aux erreurs dans les paramètres de requête HTTP. On lui passe un message d’erreur ainsi que le code d’erreur HTTP. Il vise à permettre l’automatisation des réponses HTTP au client.
express-body-validator est un module de validation des paramètres des requêtes HTTP : never trust user input ! Orienté promise et basé sur v8n, ce module rend la validation des paramètres aussi simple qu’efficace. Les données sont passées directement à then en cas de succès, et si un paramètre n’est pas validé, on catch une erreur BadRequestError. Fini les conditions et REGEX qui polluent vos controlleurs, le flux des données est maintenant préservé. Le module existe aussi pour Node.js sans framework : node-body-validator.
emailjs permet d’envoyer des emails directement en SMTP, une tâche elle aussi assez récurrente en back.
huge-uploader-nodejs est la partie serveur du module huge-uploader listé dans la partie frontend. Il réceptionne les “morceaux” envoyés par le navigateur et les assemble à la fin de l’upload afin de récupérer le fichier complet.
Dans le domaine des modules d’upload de fichiers, plusieurs options existent côté Node.js. Les quatre principales solutions sont Multer, Busboy, Formidable et Multiparty. Chaque module présente des avantages et inconvénients. Vous pouvez consulter cet article [en] pour faire un choix avisé.
winston se passe presque de présentation. C’est le logger roi de Node.js, on ajoute les transports (plugins) qui vont bien et les logs partent vraiment où vous voulez (fichier, ELK, Graylog…).
winston-log2gelf est un transport Winston pour envoyer vos logs vers un serveur Graylog ou GELF.
Modules isomorphiques
Nous parlons ici des modules que l’on utilise aussi bien en front qu’en back. Je considère plus le cas d’usage que le potentiel technique à tourner en front ou back.
uniqid permet, comme son nom l’indique, de générer des id uniques, de manière similaire à la fonction éponyme de PHP. Pour des besoins plus complexes avec des ids de longueur personnalisable (plus longs, ou plus courts), on peut se diriger vers Nono ID.
v8n pour validation, est un module permettant de valider les données (type, valeur etc). Il remplace très avantageusement des conditions et des regex. De plus, son api est chainable, ce qui la rend vraiement conviviale à l’usage pour crééer des règles de validation.
validator est un autre module de validation. Contrairement au précédent, il ne permet pas de créer des règles de validation mais propose un set de règles prédéfinis pour les cas souvent rencontrés : numéro de téléphone (nombreux pays disponibles), numéro de carte bancaire, email, url…
socket.io n’est pas à proprement parler isomorphique, mais une partie s’exécute dans le navigateur tandis qu’une autre tourne sur le serveur. Cette librairie – qu’on ne présente plus – est une surcouche à l’api websockets, qui permet facilement de tirer profit de cette technologie full duplex. La bibliothèque fallback automatiquement sur du polling si la configuration (réseau ou navigateur) ne permet pas l’usage des websockets.
color.js Il s’agit ici d’une collection de modules pour travailler avec les couleurs. La majorité – je ne sais pas si c’est le cas de tous – tournent aussi bien en front qu’en back.
Modules de développement
Ce sont ici les modules qui restent sur nos machines de dev, mais dont on pourrait difficilement se passer… Certains de ces modules s’utilisent de manière différentes selon que l’on travaille sur un modèle de pages “classiques” ou avec un bundler tel que Webpack.
Je vais donc commencer par l’usage classique – lequel est détaillé dans mon article sur Rollup – puis on verra comment gérer les choses avec Webpack (dans un cadre type Vue.js ou React).
eslint le linter JavaScript, celui-ci est dans absolument tous mes projets. Il se marie idéalement avec eslint-config-airbnb-base, on lui adjoint aussi eslint-plugin-import afin de bien valider la syntaxe ESModules. De plus, pour les projets Node.js, on peut également avantageusement utiliser eslint-plugin-security, lequel permet de détecter certaines erreurs menant à des failles de sécurités.
stylelint même chose mais côté styles. Je l’utilise conjointement à stylelint-config-standard afin d’avoir une config de base qui fait sens et stylelint-order afin de forcer un ordre dans les styles. C’est meilleur pour la compression et pour s’y retrouver. Là il y a deux écoles : ceux qui veulent de l’alphabétique et ceux qui veulent grouper les choses sémantiquement proche (width et height devraient être à côté…).
postcss-cli permet, toujours au rang des styles, de faire énormément de choses selon les plugins qu’on luit adjoint. Je considère comme indispensable de l’utiliser avec autoprefixer.
less permet de compiler le LESS en CSS. Bien que les récentes version de CSS permettent beaucoup, je reste un utilisateur habitué au confort de LESS. On verra dans quelques années si la situation évolue.
cssmin est indispensable afin de compresser les styles qui seront envoyés à nos visiteurs.
purgecss parse vos fichiers CSS et supprime tout ce qui n’est pas utilisé. Un outil qui fait fondre vos feuilles de style comme neige au soleil.
Rollup
Là où on utilisait avant Browserify avec le CommonJS, on aura maintenant plutôt tendance à utiliser un module bundler capable de gérer les module ECMAScript.
J’utilise pour ma part Rollup. On l’installe avec ses indispensables plugins que sont :
node-resolve afin d’importer des modules installés via npm,
commonjs afin de prendre en charge les modules qui ne sont qu’au format commonjs (require),
et terser afin de minifer le code pour le rendre plus léger à télécharger.
Webpack & Vue.js
Dès lors que le projet est un peu plus complexe (ou selon les préférences), on a tendance à utiliser Webpack. C’est par exemple le bundler par défaut avec Vue CLI et il accompagne quasi automatiquement les projets React.
Bon nombre des dépendances sont directement installées et configurées par Vue CLI lorsqu’on l’utilise pour initialiser un projet. Il n’est donc pas forcement utile de les détailler ici car elles ne sont pas manuellement installées.
less-loader permet de charger et convertir les fichiers LESS.
worker-loader permet de charger comme il se doit les web workers.
Comme je l’ai mentionné en introduction, il ne s’agit absolument pas d’une liste exhaustive de tous les modules utiles ou que j’utilise, mais plutôt de ceux que l’on retrouve presque systématiquement dans la plupart des typologies de projets. N’hésitez pas à me faire part de vos propres préférences et conseils en commentaires.
]]>
Le JavaScript possède un large écosystème de modules permettant d'accélérer le développement. Le plus difficile est de trouver les bons. Découvrez les modules indispensables dont vous ne pourrez plus vous passer !
PSTconverter: convertir les archives Exchange/Outlookhttps://buzut.net/pstconverter-convertir-les-archives-exchange-outlook/2019-08-22T07:00:00.000Z2024-09-05T06:56:59.840ZAu pringtemps 2018, ma mère avait besoin de récupérer le contenu d’une archive PST Exchange de plus de 50GB. Impossible d’importer ça sur Linux, pas possible non plus sur les autres systèmes sans s’abonner à Office 365. Je fais quelques recherches et entre 400 logiciels Windows payants, je finis par trouver un outil libre en ligne de commande.
Ce logiciel s’appelle readpst et fait partie de la collection d’outils libpst. Je fais la conversion et tout fonctionne à merveille. Le seul bémol : j’imagine mal ma chère maman installer et utiliser un logiciel en CLI. De là me vient l’idée d’en faire une solution web : PSTconverter.
Une seule question : pourquoi une solution web ? Tout simplement parce que j’installe le minimum de choses sur ma machine. De plus, l’idée d’installer un logiciel que je n’utiliserai qu’une seule fois me donne des boutons. D’autant plus qu’il s’agit pour la plupart de logiciels qui donnent moyennement confiance.
L’objectif est donc de fournir un outil en ligne permettant très simplement la conversion d’archives PST vers MBOX.
La technique
Le seul challenge que représente ce service est l’upload de très gros fichiers, on parle ici de plusieurs dizaines de gigaoctets. C’est donc sur ce point que je vais me concentrer.
Je ne compte pas passer mon été sur ce projet. Je prends donc un thème libre depuis HTML5 Up et je l’intègre à mon outil de build pour sites statiques. Ça me permet de profiter d’une bonne base, de booster un peu les perfs avec minification et pre-compression et d’ajouter ce dont je vais avoir besoin pour l’upload.
Côté back, rien de très complexe. Toute la vitrine du site est statique, reste plus qu’à mettre en place une micro API pour gérer les uploads, les conversions et les notifications. Bien entendu, c’est Node.js qui sera utilisé. La tâche est simple, je n’utilise aucun framework. Libpst sera bien entendu utilisée pour les conversions et les notifications seront envoyées par email, du classique !
Concernant l’upload, il est d’usage d’utiliser Resumable.js pour cette tâche. Je ne trouve pas la bibliothèque à mon goût pour de multiples raisons et puis il n’y a pas de module npm. On est en 2019, je ne me vois pas utiliser un truc qui nécessite que je l’intègre via script src="…".
Je décide donc de créer un module d’upload. Il devra gérer le chunking pour permettre l’upload de très gros fichiers, gérer les défaillances du réseau et permettre la mise en pause. Je créé en fait deux modules : huge uploader est le module client dans le navigateur et huge uploader nodejs est, comme son nom l’indique, son pendant côté serveur.
Une fois l’upload terminé, l’archive est réassemblée sur le serveur et une crontask s’assurera de convertir l’archive PST en archive Mailbox. Lorsque c’est terminé, un email est envoyé au propriétaire de l’archive afin qu’il puisse la télécharger.
Enfin, 48h plus tard, tout est effacée car je n’ai ni l’usage ni la place de garder tout cela et qu’on est en Europe, RGPD ready baby.
Business ?
Comme je l’ai mentionné, j’avais simplement l’envie de créer un service face à un besoin perçu et pour le fun de coder une solution. Il est clair que ce n’est pas la prochaine licorne française.
Je fais simplement payer un coût fixe de 5€ pour les archives de plus de 100Mo histoire d’amortir le serveur, ni plus ni moins.
]]>
PSTconverter permet de convertir les archives PST en MBOX. Explications des technos derrière le service et sur le pourquoi de sa création.