Chapitre 7 sur 8
RAM, Stack, Heap : les différents types de mémoires informatiques
Quels sont les différents types de mémoire d’un ordinateur ? Comment ce dernier assigne-t-il la mémoire pour l’usage par les différents programmes ? C’est ce à quoi nous allons nous intéresser dans ce chapitre.
Comment l’OS et les programmes stockent-ils leurs données de travail en RAM ? On dénombre trois modes d’allocation de la mémoire :
- l’allocation statique : lorsque le programme s’initialise, il demande une quantité donnée de mémoire, laquelle ne pourra pas changer par la suite. La quantité nécessaire est spécifiée dans le code source du programme.
- l’allocation dynamique sur la stack : cette allocation se fait lors de l’exécution du programme et obéit au principe de fonctionnement de la stack. Cela convient bien pour les variables locales.
- l’allocation dynamique sur la heap : cette allocation permet le stockage de volumes de données plus importants, leur accès aléatoire et le partage d’informations entres différentes fonctions et threads.
Allocation statique
Dans la pratique, seul les langages compilés (C, C++, Pascal, Haskell…) permettent l’usage de l’allocation statique. Les langages interprétés (PHP, Python, JavaScript…) ne peuvent allouer la mémoire que sur demande, de manière dynamique.
L’avantage est ici principalement la performance. La mémoire est immédiatement utilisable par le programme sans avoir à demander à l’OS l’attribution d’espace mémoire.
Ce type de mémoire manque cependant de souplesse car son allocation doit être prévue lors de l’écriture du programme, et cela ne peut être modifié à l’exécution. On s’en sert donc principalement pour des variables statiques ou des variables globales dont les valeurs sont déjà connues à la compilation.
Allocation dynamique
L’allocation dynamique se fait pendant l’exécution d’un programme. Le programmeur n’a pas besoin de définir l’espace nécessaire en amont, dans le code source. Le programme effectue la demande d’allocation d’espace à l’OS au cours de son exécution.
C’est le seul mode d’allocation disponible pour les langages interprétés. Cependant, même pour les langages compilés, c’est particulièrement intéressant lorsque l’on ne sait pas à l’avance la taille de l’espace dont on va avoir besoin (données de tailles variables).
Allocation sur la stack
La stack est une zone mémoire qui sert d’espace de stockage aux variables déclarées par les fonctions. La stack est aussi appelée la pile en français. La plupart du temps, elle est de taille fixe, déclarée lors du démarrage du thread. Cependant, l’allocation à l’intérieur de la stack est dynamique.
Elle tient son nom de son mode de fonctionnement, semblable à une pile de dossiers. Il s’agit d’une structure de données fondée sur le principe “dernier posé sur le dessus de la pile, premier à sortir”. Cet ordonnancement s’appelle LIFO (Last In, First Out). La stack possède deux fonctions principales : push, pour ajouter un élément, et pop pour retirer et récupérer cet élément.
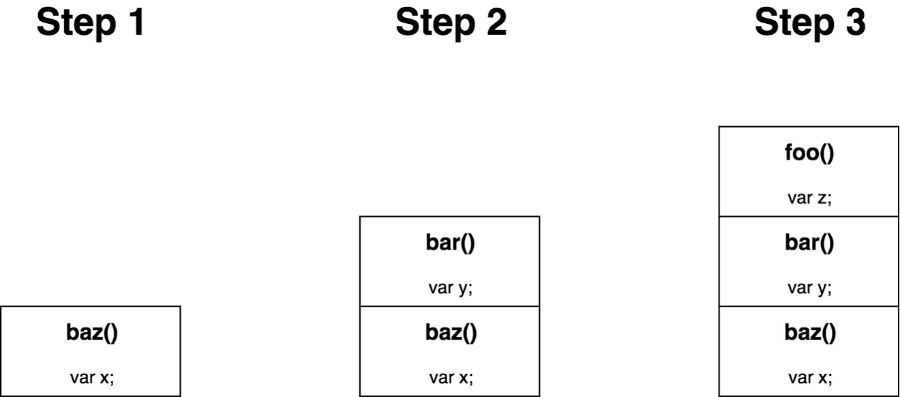
La stack a une origine fixe, le pointeur référence toujours le haut de la stack (adresse mémoire plus haute ou basse selon le sens d’expansion), son accès est donc séquentiel. Le pointeur ne peut pas aller au delà des limites de la stack, il s’agit sinon de stack overflow, une tentative d’écriture dans des zones de mémoire adjacente. Cela aboutit généralement à un crash du programme.
Comme les accès à la stack sont séquentiels et que les mêmes adresses mémoire tendent à être réutilisées, le processeur optimise l’accès à cet espace mémoire en le mettant dans son cache. Par conséquent, les lectures et écritures dans la stack sont très performantes.
En revanche, comme sa taille est déclarée lors de la création du thread, il n’est pas possible d’y stocker des quantités trop importantes de données. En outre, chaque thread possède une stack propre. Dans les langages permettant le multithreading, la stack ne peut servir à partager de l’informations entre différents threads.
Dans les langages de bas niveau pour lesquels la gestion de la mémoire n’est pas automatique, l’usage de la stack a l’avantage de ne pas avoir à se préoccuper de libérer la mémoire. De fait, lorsqu’une fonction termine son exécution, toutes les variables qu’elle a déclarées sont instantanément supprimées.
Allocation sur la heap
La heap permet le contrôle complètement arbitraire de l’allocation et de la libération. Par ailleurs, il n’y a aucune contrainte de taille. Lorsque le processus nécessite plus de mémoire, il en fait simplement la demande à l’OS.
Il n’y a pas de gestion de l’attribution et de l’accès aussi stricte que celle de la stack, la heap est plus flexible. Cependant, elle demande le maintient de pointeurs pour chacune des valeurs stockées. Cette gestion étant plus complexe, les performances n’en sont pas aussi bonnes – toute proportion gardée.
En outre, la heap permet l’allocation de variables globales partagées entre plusieurs fonctions (sans recourir au passage de paramètres) et permet, le cas échéant, le partage de valeurs entre threads d’un même processus. Cette particularité fait que la heap doit la plupart du temps être thread-safe, ce qui impacte aussi légèrement les performances.
De plus, le fait que cet espace mémoire soit alloué et libéré sans contrainte le rend sujet à la fragmentation.
Par ailleurs, dans les langages de programmations n’ayant pas une gestion automatique de la mémoire, le développeur devra s’assurer de bien libérer la mémoire utilisée après usage. Dans le cas contraire, on aboutit à une fuite de mémoire.
Enfin, pour les langages ayant une gestion automatique de la mémoire (Python, Go, Java, PHP, JavaScript…) le choix du mode d’allocation est directement réalisé par le compilateur selon différents scénarios. Voici par exemple quelques explication du fonctionnement du moteur JavaScript V8 [en].
En résumé
Il est bon de connaître ces différents types de mémoires et leur fonctionnement. Toutefois, si vous utilisez un langage dynamique, vous n’avez probablement pas de maîtrise sur la gestion de la mémoire. À l’inverse, dans le cas contraire, il est de bon ton d’utiliser le type de mémoire le plus rapide et/ou flexible adapté à votre usage.
Commentaires
Rejoignez la discussion !