Chapitre 4 sur 8
L'endianness, les headers et le BOM
Nous savons que de nombreuses données peuvent être représentées sur plusieurs octets. Vous le savez, selon le type de données, ces octets ne signifient pas toujours la même chose. Une suite de bits n’a pas la même signification s’il s’agit d’un nombre signé, d’un float etc. Saviez-vous que ces octets peuvent, selon la configuration, se lire de gauche à droite ou de droite à gauche ?
Cette particularité s’appelle endianness, aussi dit boutisme en français. On parle également parfois de byte order, ordre des octets ou byte sex.
Endianness
Avant d’attaquer, définissons les termes français et anglais, lesquels sont utilisés de manière interchangeable. Boutisme et endianness sont synonymes et représentent le concept. Les termes big-endian, gros-boutiste en français, et little-endian, soit petit-boutiste en français, définissent l’ordre dans lequel sont organisés les octets.
L’ordre correspond à la position des différents octets en mémoire. La mémoire est découpée en octets, une unité de stockage, dont chacune est adressable via son adresse mémoire ou index.
Big-endian
Entrons maintenant dans le vif du sujet. Cette différence est initialement lié au matériel. En effet, certains processeurs stockent les informations en big-endian, c’est à dire l’ordre naturel, comme on a pu le voir jusqu’ici.
En gros-boutiste, pour le nombre 192DAF66hex, stocké sur quatre octets, les chiffres de poids forts sont stockés en premier, donc aux adresses mémoire les plus petites. Le nombre sera alors stocké comme ceci 19 2D AF 66, octet par octet, du plus fort au moins fort.
Little-endian
Cependant, certains processeurs, comme ceux ayant une architecture x86, stockent les informations dans l’ordre inverse.
Une raison historique
Si la majorité des processeurs actuels sont petit-boutistes, c’est parce que cela simplifiait le câblage des processeurs dans les années 70. On en hérite aujourd’hui, bien que son impact matériel soit maintenant insignifiant.
Dans une architecture petit-boutiste, notre nombre est stocké en ordre inverse, les octets de poids faible correspondent aux adresses mémoire les plus petite et inversement. Ainsi, 192DAF66hex est stocké en petit-boutiste de la manière suivante : 66 AF 2D 19.
Ce n’est pas tout, il faut prendre en considération le fait qu’un processeur n’a pas forcément une structure de mémoire où l’unité atomique est de un octet. Dans le cas où la plus faible unité de mémoire allouable correspond à deux octets, alors notre nombre sera stocké de cette manière : AF66 192D.
Middle-endian
Les deux principaux sont ceux dont nous avons parlé ci-dessus. Cependant, certaines architectures permettent les deux, on les appellent bi-boutistes. L’ordre est alors fixé soit au niveau matériel, soit au niveau logiciel.
Enfin, il existe encore une autre variante, appelée mi-boutiste, laquelle inverse les octets composants les unités atomiques. Ainsi, dans une architecture mi-boutiste, pour 192DAF66hex, on peut avoir :
- 2D19 66AF,
- 66AF 2D19.
Comme l’ordre est ambigu, on parle alors de gros-boutisme avec byte-swap ou de petit-boutisme avec byte-swap.
On notera que les différents boutismes peuvent se retrouver dans l’écriture humaine des dates :
- 17/02/2019 norme française, petit-boutiste,
- 2019/02/17 standard ISO, gros-boutiste,
- 2019/17/02 norme américaine, mi-boutiste.
Matériel et protocole
Nous avons jusqu’ici parlé de processeurs. Le little-endian est en effet le plus répandu, la plupart des processeurs étant little-endian. Les systèmes utilisant ces processeurs fonctionnent sous le même mode.
Cependant, lorsqu’un système est big ou little-endian, il doit tout de même interagir avec d’autres systèmes. Il faut donc s’accorder sur un standard afin que les machines soient interopérables. C’est pourquoi, au delà du matériel et du logiciel l’utilisant, les protocoles ont un boutisme.
Par exemple, tous les protocoles réseaux sont big-endian. Cela va du TCP/IP aux structures de données binaires en passant par les sockets UNIX standards. Ainsi, toutes les données sont converties avant transmissions sur le réseau et re-converties lors de la réception.
Identifier l’information
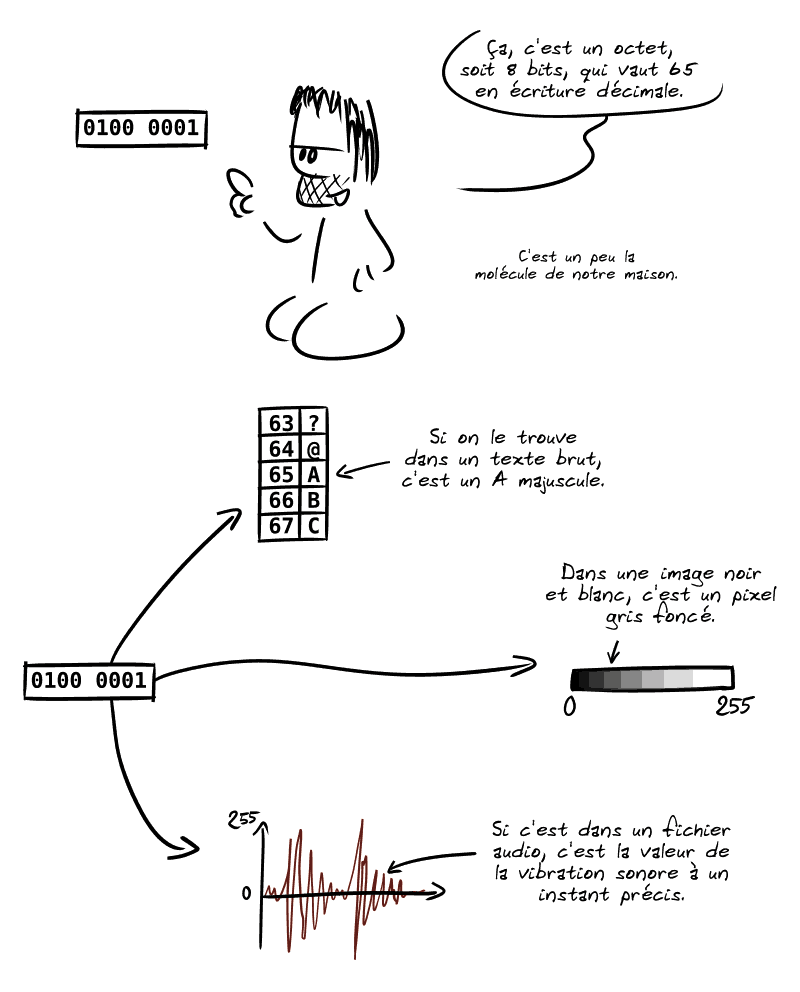
À ce stade, nous savons qu’une même suite de bits peut avoir plusieurs significations. Une question vous taraude peut-être : comment la machine sait-elle qu’une suite de bits est une instruction, un nombre signé, du texte ou une vidéo ? En effet, 1111 1111bin vaut 255dec s’il s’agit d’un entier non signé. En revanche, s’il s’agit d’une représentation signée, la valeur est de -127dec.
On réalise donc qu’il faut qu’à un niveau, on puisse faire la différence. Pour les programmes, c’est le travail du compilateur. Il prend le code source des programmes et le transforme dans un langage que la machine peut comprendre. Ce ne sera d’ailleurs pas toujours le même selon le type de processeur utilisé. C’est pour cela que dans les langages compilés, on compile pour une cible particulière (ARM, x64 etc).
Le processeur est aveugle
Le processeur ne sait pas ce qu’il fait, c’est un peu comme si l’on dirigeait quelqu’un avec les yeux bandés pour qu’il cuisine. On lui dirait “tourne le bouton qui est à ta gauche de 4 crans sur la droite”, plutôt que “met le four à préchauffer à 200 degrés”. Les instructions sont compréhensibles par le processeur mais il les exécute aveuglément, sans vraiment savoir de quoi il s’agit.
À plus haut niveau, c’est le système d’exploitation qui gère les différents types de fichiers. D’ailleurs, un logiciel est un fichier.
Un fichier exécutable, parfois (par métonymie) un programme, ou simplement un exécutable est un fichier contenant un programme et identifié par le système d’exploitation en tant que tel. Le chargement d’un tel fichier entraîne la création d’un processus dans le système, et l’exécution du programme, par opposition au fichier de données qui doit d’abord être interprété par un programme pour prendre sens.
Pour les fichiers, dont les programmes après compilation, il y a très souvent un en-tête qui indique à l’OS de quel type de fichier il s’agit. Il sait alors avec quel logiciel ce fichier doit être ouvert. À son tour, le logiciel sait comment l’interpréter (un fichier audio en mp3 n’est pas décodé de la même manière qu’un fichier audio en flac).
Les headers
Si vous connaissez les headers dans les protocoles réseaux, comme l’en-tête IP ou HTTP, c’est exactement le même concept. Il s’agit d’une métadonnée donnant des instructions sur la manière de traiter le contenu : la donnée. Nous parlons ici d’en-tête dans des fichiers.
De ce fait, le binaire d’un logicel .exe sous Windows commencera très souvent par “MZ”, les initiales de l’inventeur du format, Mark Zbikowski. Cela signale à Windows qu’il s’agit d’un binaire exécutable, l’OS lance alors un thread afin que le programme puisse exécuter son code.
Plusieurs utilitaires permettent d’afficher le contenu brut d’un fichier, sous le format d’un dump binaire ou hexadécimal. Sous Linux ou macOS vous disposez des outils xxd, od, hd ou hexdump. Ils servent plus ou moins tous à la même chose. Vous utiliserez l’un ou l’autre selon vos préférences et leur disponibilité sur votre système.
J’ai une petite préférence pour le format de xxd, lequel affiche par défaut les caractères représentables en ASCII à droite de la ligne correspondante. Cependant, lorsque certaines options avancées sont requises – comme afficher le dump dans différents formats (octal, floats, endianness…) – on a tendance à utiliser od ou hexdump. Ils sont équivalents, l’un est initialement issue du monde Unix tandis que l’autre vient du monde BSD.
J’utilise donc xxd pour afficher le dump en hexadécimal de l’illustration ci-dessus.
xxd signification-octet.png | head
00000000: 8950 4e47 0d0a 1a0a 0000 000d 4948 4452 .PNG........IHDR
00000010: 0000 0320 0000 03e0 0806 0000 00ca 9818 ... ............
00000020: dc00 0004 1969 4343 506b 4347 436f 6c6f .....iCCPkCGColo
00000030: 7253 7061 6365 4765 6e65 7269 6352 4742 rSpaceGenericRGB
00000040: 0000 388d 8d55 5d68 1c55 143e bb73 6723 ..8..U]h.U.>.sg#
00000050: 24ce 536c 3485 74a8 3f0d 250d 9356 34a1 $.Sl4.t.?.%..V4.
00000060: b4ba 7fdd dd36 6e96 4936 da22 e864 f6ee .....6n.I6.".d..
00000070: ce98 c9ce 3833 bbfd a14f 4550 7c31 ea9b ....83...OEP|1..
00000080: 14c4 bfb7 8020 28f5 0fdb 3eb4 2f95 0a25 ..... (...>./..%
00000090: dad4 2028 3eb4 f883 50e8 8ba6 eb99 3b33 .. (>...P.....;3La première colonne à gauche indique l’offset, c’est à dire la position, l’adresse de la mémoire relativement à ce fichier. Ainsi comme chaque ligne contient huit octets (8 x 8 = 16), la ligne suivante commence à 10hex soit 16dec.
On aperçoit immédiatement des métadonnées au début du fichier png. Notamment le fait qu’il s’agit d’un fichier png, première ligne, mais également l’espace colorimétrique utilisé, lignes trois et quatre.
Ces informations constituent donc le header du fichier et c’est grâce à cela qu’avec un simple clic, l’OS sait quel logiciel il doit utiliser pour l’ouvrir et qu’à son tour, le logiciel en question sait comment l’afficher (algorithme PNG utilisant l’espace colorimétrique x ou y).
Vous pouvez essayer sur des pdf, des jpeg, des exécutables etc, presque tous les fichiers posséderont un en-tête ASCII donnant quelques informations sur son contenu.
BOM a.k.a Byte Order Mark
Le BOM – aussi appelé IOO en français, pour indicateur d’ordre d’octet – est utilisé dans les fichiers textes au format Unicode. Vous imaginez bien que même s’il s’agit de texte – on parle de fichier texte et non de binaire – en réalité, le fichier n’est qu’une suite de bits comme tout autre fichier.
En tant que suite de bits, il faut indiquer comment les interpréter. Le BOM, comme son nom l’indique, permet de rendre explicite l’ordre des octets qui prévaut dans le fichier. C’est un nombre magique qui, s’il est placé au début du fichier, permet d’indiquer au logiciel qui lit le texte, comment l’interpréter.
Le BOM est facultatif, aussi, s’il est présent, il indique trois choses :
- l’endianness du document,
- le fait qu’il s’agit d’un texte en Unicode, à une probabilité assez élevée,
- quel encodage est utilisé.
Le BOM est le caractère Unicode U+FEFF, aussi comme il est encodé de la même manière que le document, s’il est lu à l’envers, soit FFFE, il ne représente pas un caractère Unicode valide, de ce fait le programme lisant le stream de texte sait qu’il faut opérer une inversion des octets. Idem pour l’UTF-32, où le BOM sera encodé comme 0000 FEFF ou FFFE 0000 selon qu’il s’agit de big ou small-endian.
En revanche, le BOM est peu utilisé en UTF-8 et son usage est même déconseillé par l’IETF et le standard Unicode. En effet, en UTF-8 le boutisme n’a pas d’incidence sur l’encodage. Par ailleurs, comme l’UTF-8 est rétro-compatible avec l’ASCII, l’usage du BOM, qui n’est pas un caractère ASCII valide, casse cette compatibilité et empêche certains logiciels non compatibles avec l’Unicode de fonctionner.
BOM le farceur
La présence du BOM est bien souvent source de bugs. Par exemple, dès lors que l’on veut concaténer deux fichiers texte, si l’on utilise l’outil Unix cat par exemple, le BOM du second fichier se retrouve en plein milieu du fichier nouvellement créé.
Par ailleurs, en PHP la présence du BOM fait que, techniquement parlant, <?php n’est pas la première chaîne de caractère présente dans le fichier source. Aussi, en présence du BOM, vous rencontrerez tôt ou tard l’erreur Cannot modify header information – headers already sent by.
Maintenant que nous avons compris ces notions essentielles, dans le prochain chapitre, nous allons nous pencher sur l’Unicode !
Commentaires
Rejoignez la discussion !