Chapitre 1 sur 13
Découvrir comment Git gère le versionnage
On peut difficilement parler de Git sans mentionner la gestion de version de manière générale. La gestion de version – ou versioning – permet de conserver une trace des évolutions d’un ensemble de fichiers. Grâce à ces outils, il est notamment possible de savoir ce qui a été fait, par qui et à quel moment.
Les outils de versioning s’appellent VCS pour Version Control System ou système de gestion de version. Ils permettent de disposer d’outils performants dédiés à cette tâche. On a en effet certainement tous vécu le versioning “manuel”… et d’expérience, ça devient vite ingérable.

Git n’est ni le seul et encore moins le premier outil de versioning à avoir été créé. Cependant, il est un des plus récents et a été créé pour répondre aux lacunes de ses prédécesseurs. Les VCS ne sont pas réservés au versioning de code, cependant, les développeurs en sont les plus gros utilisateurs. C’est donc dans un contexte de gestion de code que nous nous placerons dans la suite de cet ouvrage.
Système centralisé vs distribué
Parmi les VCS, on en trouve de deux sortes. Le premier type et le premier à avoir été inventé est le système centralisé. Avec les VCS centralisés, tout réside sur une seule machine, généralement un serveur, depuis laquelle on récupère les fichiers. De même, les modifications sont effectuées directement sur le serveur distant.
L’autre approche est distribuée. Dans ce type de VCS, les dépôts sont distribués : chaque client récupère l’intégralité des fichiers du dépôt et travaille ensuite sur sa copie locale. Lorsqu’il veut partager ses changements, sa copie locale est alors poussée sur le serveur distant.
Évidemment, chacune des approches possède ses avantages et inconvénients. Les CVS distribués évitent d’avoir un point unique de défaillance en permettant des copies mutliples du code. Par ailleurs, ils apportent une grande souplesse dans la collaboration en permettant à chacun de collaborer avec différents groupes sur différents dépôts distants.
Le fait d’avoir une copie locale permet également aux développeurs d’aisément effectuer des tests qu’ils ne voudraient pas partager en l’état avec leurs pairs. En revanche, les CVS centralisés permettent une gestion plus aisée des conflits en mettant en place un système de verrous, lequel empêche quiquonque d’effectuer des modifications sur une partie du code déjà en cours de modification par quelqu’un d’autre.
Git fait partie de la famille des CVS distribués.
Git, un système de fichiers
Git est un système de fichiers : il organise la manière dont sont stockés les fichiers dans les projets qu’il gère. À ce titre, les différentes actions permises par le logiciel peuvent modifier l’état du projet tel qu’il est visible sur votre machine.
À chaque fois que vous créez un enregistrement dans Git, un instantané du projet à cet instant T est créé. Afin d’être plus efficace, Git utilise des références vers les fichiers. Cela lui permet de ne pas stocker des copies de tous les fichiers pour chaque instantané, mais seulement ceux qui ont changés.
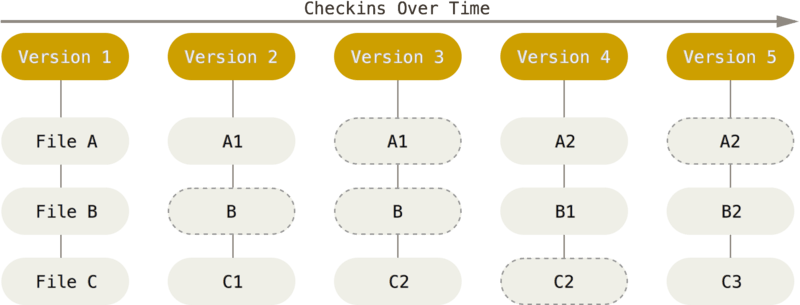
Structure interne
En interne, Git organise les informations en trois types :
- Les blob : contenu brut d’un fichier.
- Le tree, représente un répertoire. Les fichiers sont listés par leur hash et les autres répertoires possèdent eux-mêmes un hash SHA-1. Le tree associe le nom du fichier ou répertoir à chacun de ces hashs.
- Les commits. Ils contiennent le hash de l’objet tree correspondant à la racine du commit, le hash de son parent (ou plusieurs s’il s’agit d’une fusion), le message de commit, l’auteur et le timestamp.
Contrôle d’intégrité
Chaque fichier et chaque version du projet est vérifié par une emprunte SHA-1. Le SHA-1 est un algorithme de somme de contrôle permettant de créer une emprunte unique – aussi appelé hash – à partir du contenu des fichiers.
Ce faisant, il est donc impossible d’effectuer une modification dans un projet sans que Git ne s’en rende compte. Cela garanti aussi qu’il est virtuellement impossible de corrompre un projet ou de perdre des informations lors du partage d’un projet.
Les empruntes SHA-1 sont uniques et désignent donc sans ambiguité une version unique d’un fichier. Git utilise ces empruntes pour désigner chacuns des snapshots d’un projet.
Sous le capot, Git stocke tous les éléments dans sa base de données en les désignants par leurs empruntes SHA-1. Une telle emprunte est représentée par une suite de 40 caractères alphanumériques. À titre d’exemple, la chaîne de caractère “sha1” hashée en SHA-1 donne :
415ab40ae9b7cc4e66d6769cb2c08106e8293b48Les états de Git

Le projet et ses fichiers peuvent être dans différents états. Ce que nous visualisons directement sur notre machine en navigant dans les fichiers ou en les éditant via notre éditeur de texte, c’est le répertoire de travail.
La zone d’index, nommée staging en anglais, est une zone temporaire dans laquelle on ajoute les fichiers qui feront partie du prochain instantané. Dans le langage de Git, les instantanés se nomment des commits.
La zone d’index stocke un fichier (ou plusieurs) et ses modifications, c’est un snapshot à l’échelle d’un fichier. Si d’autres modifications sont faites par la suite, il faudra individuellement les ajouter à la staging si l’on veut qu’elles fassent partie du prochain commit.
Ce mécanisme est très puissant car il permet d’effectuer des modifications, de les pré-valider, puis d’essayer autre chose. Dès lors que des modifications ont été ajoutées à l’index, trois scénarios sont possibles :
- les modifications ne sont pas concluantes, on restaure notre fichier tel qu’il est dans la staging,
- les modifications sont concluantes et font parte du même groupe de modifications (ou fonctionnalité) que celles déjà ajoutées, on indexe nos modifications pour qu’elles fassent toutes partie du prochain commit,
- les modifications sont concluantes mais modifient des choses qu’on préfère ajouter à un autre instantané, on les ajoutera après avoir commité les modifications déjà indexées.
Lorsque l’on est satisfait de l’état des modifications indexées, on peut alors commiter celles-ci. Git calcule le hash de tous les fichiers à inclure au snapshot, lui attribue une emprunte unique et l’ajoute à sa base de données.
Nos modifications sont alors archivées dans la base de données de Git. Dès lors, il est possible de lister ces modifications, d’en connaître la date et l’auteur.
Il est aussi possible de restaurer un fichier ou l’ensemble du projet à son état d’un commit précis. Concrètement, il s’agit d’un extraction depuis la base se données de Git. Cette extraction place le ou les fichiers dans l’état demandé directement dans le répertoire de travail.
L’atout énorme de Git est qu’aucune de ces modifications n’est destructive. Après restauration, vous pouvez modifier vos fichiers puis créer un nouvel instantané, une version paralèlle de votre projet ou simplement revenir à l’état d’avant restauration.
Installer Git
Maintenant que nous avons vu les concepts derrière Git et le versioning, nous allons pouvoir entrer dans le vif du sujet. Dès le prochain chapitre, nous passons à la pratique. Pour cela, vous allez avoir besoin de Git sur votre machine. Que vous soyez sous Windows, macOS ou Linux, Git est compatible avec votre système.
Bien que certains logiciels proposent une interface graphique pour Git, Git lui-même est en ligne de commande. C’est donc cette dernière que nous allons utiliser dans les prochains chapitres.
Sur de nombreux systèmes, Git est déjà istallé. Pour le vérifier, il suffit d’ouvrir la ligne de commande et de taper git --version.
Linux et Unix
Git est forcément disponible dans les paquets de votre distribution. Dans la famille Debian, on se contentera d’un habituel :
apt install gitSi vous désirez une version plus récente que celle disponible dans les dépôts, et pour les autres distributions, veuillez vous référer directement au site officiel.
Windows
Pour Windows, deux solutions existent, soit vous utilisez Git au travers du sous-système Linux (WSL), soit vous installez Git via l’exécutable pour Windows.
macOS
Vous avez ici plusieurs solutions. Si vous avez installé les outils pour développeurs, il y a de grandes chances pour que Git soit déjà présent sur votre système. Toutefois, si vous souhaitez une version plus récente que celle fournie par défaut, vous pouvez en insaller une autre.
Si vous utilisez Homebrew, alors installez directement à partir de ce dernier.
brew install gitSi vous êtes plutôt utilisateur de MacPorts, alors vous n’êtes plus qu’à une seule commande d’avoir Git sur votre système.
# Installe Git avec le gestionnaire de mot de passe
sudo port install git +bash_completion+credential_osxkeychain+docGestion de l’authentification
Lorsque l’on travaille avec des répertoires distants, il faut s’identifier pour pouvoir synchoniser du code. Deux méthodes d’authentification sont disponibles :
- clef SSH lors de l’utilisation du protocole SSH,
- nom d’utilisateur et mot de passe lors de l’utilisation du HTTPS.
Vous l’avez deviné, Git supporte deux protocoles. Si l’identification lors de l’utilisation du SSH est gérée directement par la clef SSH de votre système, l’usage du HTTPS requiert un mot de passe.
Tapez le mot de passe à chaque fois que l’on veut synchroniser le dépôt distant peut vite devenir rébarbatif. Git propose pour cela plusieurs méthodes :
- mise en cache du mot de passe en mémoire pour une certaine durée,
- stockage du mot de passe dans le dossier de configuration de Git (de manière non chiffrée),
- stockage du mot de passe dans le gestionnaire de mot de passe intégré au système d’exploitation pour macOS ou Windows.
Si le disque de votre machine est chiffré, il semble tout à fait acceptable d’avoir recours à la méthode cache de Git qui stocke les mots de passe dans son répertoire de configuration.
Pour les utilisateurs de Windows et macOS, il est possible d’utiliser les gestionnaires natifs desdits OS. Pour Mac, le gestionnaire est livré avec Git si vous installez via les binaires ou via Homebrew et est optionnelle avec MacPorts.
Pour windows, il faut l’installer directement à partir du GitHub de l’extension. Toutefois, si vous utilisez Linux, que vous voulez vous éviter une installation manuelle sur Windows ou que vous ne voulez pas stocker les identifiants dans le trousseau de macOS, nous verrons dans le prochain chapitre comment configurer la méthode cache de Git.
Commentaires
Rejoignez la discussion !