Sites statiques et Jamstack : la révolution frontend
Les générateurs de sites statiques (GSS ou communément nommés SSG), sont devenus en quelques années, grâce aux apports de la Jamstack, des outils de premier plan. D’une solution pour blog de développeur, ces technologies propulsent aujourd’hui des sites à fort trafic et à forte valeur ajoutée.
Spotify, Mastercard, Nike, Google, Facebook, Airbnb… Ce ne sont que quelques-uns des utilisateurs de ces solutions. Quels en sont donc les avantages, qu’est-il possible de faire avec cette nouvelle stack et comment ? Autant de questions auxquelles nous allons répondre dans cet article.
Un peu d’histoire
Lorsque Tim Berners-Lee créé le web en 1989, il n’existe rien d’autre que des sites statiques : pour créer un site, il faut manuellement écrire chacune des pages en HTML.
Rapidement, des chercheurs du National Center for Supercomputing Applications se penchent sur deux problèmes :
- Comment faire afin de n’écrire qu’une seule fois des éléments qui se répètent sur toutes les pages ?
- Est-il possible de dynamiquement générer du HTML ?
C’est en 1993 qu’ils créent un serveur web, NCSA HTTPd, avec deux technologies majeures :
- les Server Side Includes permettent de construire un document HTML à partir de plusieurs fichiers en permettant d’inclure le HTML d’un fichier dans un autre. Ainsi, le code du header et du footer (et tout autre élément redondant) n’est plus à répéter sur toutes les pages.
- la Common Gateway Interface (ou CGI) permet la communication du serveur web avec des programmes externes qui peuvent lire les requêtes reçues par le serveur et générer du HTML à envoyer au client.
Le web dynamique était né. Ce n’est qu’un an plus tard, en 1994, que Rasmus Lerdorf créé un langage spécifiquement dédié à la génération dynamique de pages HTML, le PHP. Les premiers générateurs de sites statiques grand public ne se font pas attendre très longtemps, FrontPage et Dreamweaver arrivent respectivement en 1995 et 1997.
Viennent ensuite les CMS, TYPO3 débarque en 1998, rapidement suivi par de nombreux autres : SPIP, Dotclear, Drupal, WordPress, Joomla… Les CMS vont dominer le paysage du développement web pendant près de 15 ans. Qu’il s’agisse d’un site vitrine ou d’un site e-commerce, le CMS est l’outil de choix dans près de 99% des cas.
La LAMP Stack
Je me souviens de mes débuts sur le web. J’étudiais le HTML sur le Site du Zéro et le cours terminait pas un chapitre sur les formulaires. Après avoir appris les différents champs existants, les méthodes POST et GET et l’utilité de target, le cours concluait donc :
Vous savez envoyer des données via un formulaire. Il faut maintenant apprendre un langage backend comme PHP pour les récupérer et les traiter, sinon ça ne sert à rien.
Gros éléctrochoc. C’était l’époque du “Web 2.0” et je réalisais que le seul moyen pour moi de ne pas rester bloqué au stade 1.0 était de maîtriser un langage backend… j’étais parti dans l’apprentissage de PHP, puis de MySQL.
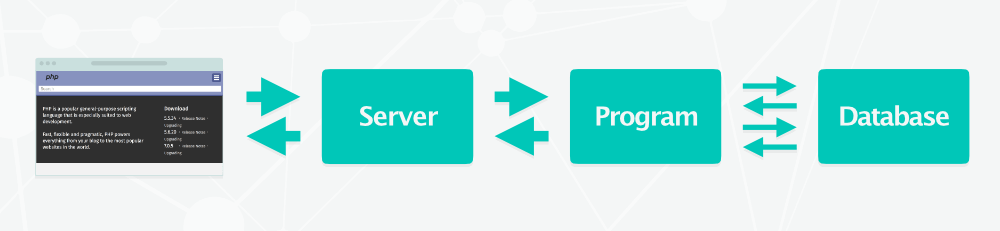
C’était il y a plus d’une décennie. À l’époque, la stack LAMP (Linux, Apache, MySQL, PHP) était reine. D’autres stack existent, mais toutes présentent le même schéma de fonctionnement :
- le navigateur du client demande une page au serveur web,
- le serveur demande à son tour la page au moteur de rendu dynamique (PHP, Java…),
- le moteur interroge la base de données,
- le moteur génère le HTML à partir des données récupérées,
- le moteur transmet les données au serveur web,
- le serveur web envoie les données au client.
Tous les CMS fonctionnent de cette manière, il s’agit du one best way en matière de programmation et d’hébergement. C’est le seul moyen de bénéficier des fonctions modernes du web.
Évidemment, générer les pages à chaque fois qu’un utilisateur la demande consomme beaucoup de ressources et n’est donc pas scalable. Si vous avez déjà utilisé WordPress par exemple, chacun sait qu’il y a de nombreux plugins de cache.
La première fois qu’une page est consultée, elle est dynamiquement générée, puis le HTML généré est stocké et sera directement servi au prochain visiteur, sans re-passer par la case génération dynamique.
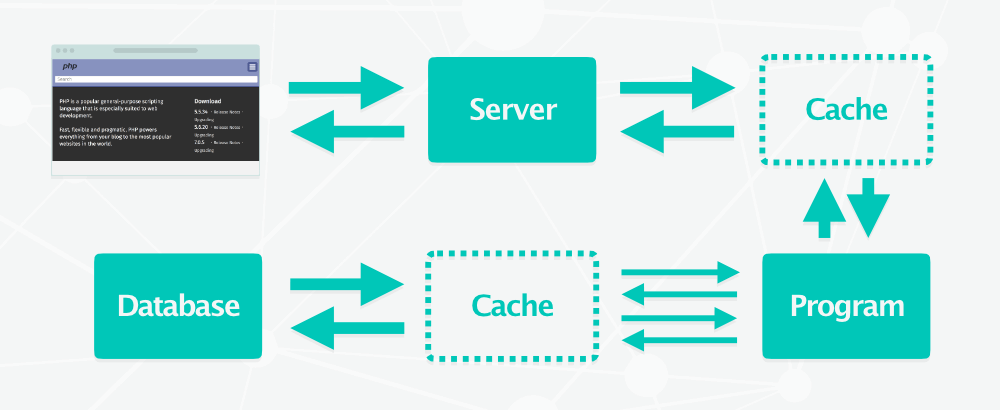
Cela fonctionne pour les pages dont le contenu est majoritairement statique, mais ce n’est pas valable pour les site proposant un compte utilisateur dont le contenu est unique à chaque visiteur. Dans ce cas là, on utilise un cache partiel et on ajoute un cache à la base de données pour ne pas requêter les mêmes informations encore et encore.
Évidemment, pour améliorer les performances, on stocke les fichiers statiques (CSS, JavaScript, images) sur un CDN. On peut aussi y placer les fichiers pseudo-statiques : les pages HTML qui ne sont pas générées à la volée (celles qui ne changent que quelques fois par jour ou moins).
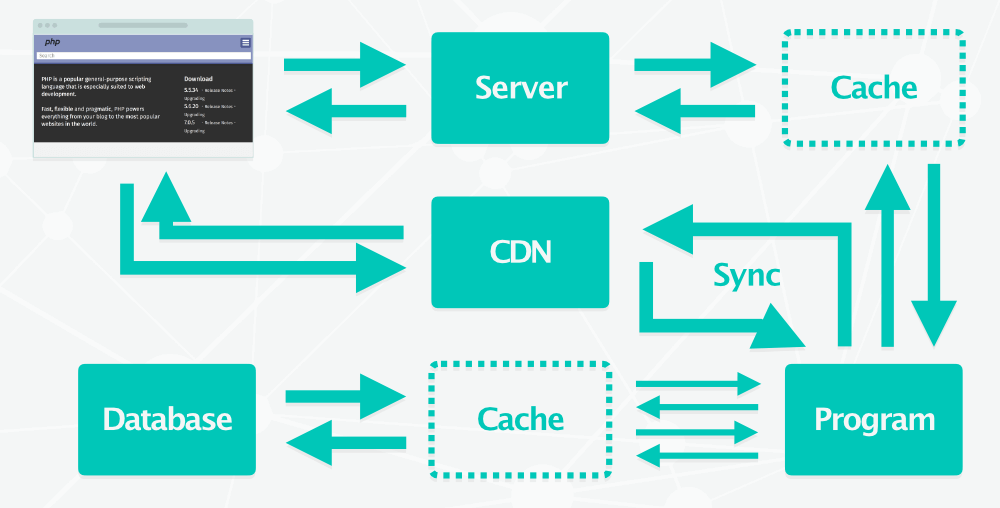
Toute cette infrastructure est complexe. Il faut s’assurer que la bonne version des fichiers est servie depuis le cache, effectuer les mises à jour de sécurité, veiller à ce que toutes les briques de la pile soient fonctionnelles, ajouter des serveurs pour encaisser l’augmentation du trafic etc.
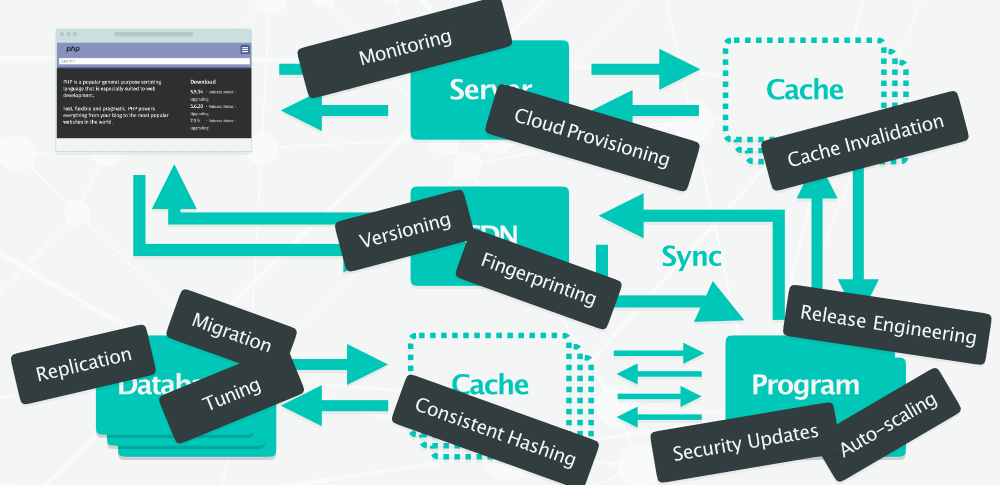
On arrive à un stade où il faut être ingénieur fullstack pour le moindre projet d’envergure. Même pour un simple blog sous WordPress, il faut continuellement se soucier des mises à jour, de la compatibilité des différents plugins, du thème etc.
Autant dire qu’une certaine stack fatigue finit par se faire sentir. Les développeurs veulent développer et non passer leur temps à faire de l’ops et de l’adminSys.
Le retour des SSG
Les générateurs de sites statiques (SSG ou GSS en français) ne sont pas nouveaux. En plus des générateurs grand public déjà mentionnés, ils sont largement utilisé par les développeurs afin de générer la documentation logicielle.
Les générateurs de documentation produisent le HTML à partir du code source. Le plus ancien SSG destiné à la documentation est JavaDoc, sorti en 1995. Doxygen arrive quelques années plus tard et supporte de nombreux langages. Enfin, bien bien d’autres sont spécifiques à leur propre langage.
C’est cependant en 2008 que l’usage des SSG explose avec les GitHub pages. Cette feature de GitHub permet de publier des sites directement depuis le dépôt Git. Il suffit pour cela de glisser/déposer un site pré-construit (fichiers statiques) ou d’utiliser Jekyll, le SSG créé par le co-fondateur de GitHub.
Il était possible d’utiliser un SSG avant les GitHub Pages et de simplement déployer sur le cloud, sans avoir à se soucier de maintenance et de sécurité. Néanmoins, avec les GH Pages, les développeurs accèdent à une approche résolument moderne : terminé les déploiements via FTP ou rsync, on n’utilise désormais plus que Git et tout est automatisé avec la CI/CD.
S’en suit alors une explosion des générateurs de site statique. Les blogs de développeurs migrent par milliers des CMS aux SSG. Le site statique devient une mode et il se créé des SSG toutes les semaines, même WordPress possède sont SSG.
Aujourd’hui, l’environnement est mature, chaque langage présente un choix d’outils confortable. Développeur Python, Ruby, Java, Go ou JavaScript ? Aucun problème. Barbu ne jurant que par le C ou le Rust ? T’inquiète. Sysadmin amoureux du Bash ? On a ce qu’il te faut !
Bien qu’il ne soit absolument pas nécessaire de connaître le langage dans lequel un SSG est programmé pour l’utiliser, de nombreux développeurs apprécient de pouvoir l’étendre ou le modifier au besoin (même s’il ne le font jamais…).
Pour trouver le SSG qui saura combler vos besoins, direction le site Jamstack.org, où l’ensemble des SSG disponibles sont référencés et triables par langage et moteur de template.
La puissance des navigateurs
Dans les années 90 et dans le début des années 2000, les navigateurs étaient de simples lecteurs de documents. Toute l’interactivité devait donc se passer côté serveur.
Cependant, avec l’émergence de l’Ajax dans les années 2000 apparaissent les SPA et les WebApps, lesquelles sont des sites web qui ne nécessitent pas de rechargement de page et offrent une expérience identique à un logiciel natif.
On pense immédiatement aux applications web de Google (Gmail, Google Docs…), mais les exemples d’applications web ne manquent pas. Sans aucune exécution côté serveur, vous pouvez par exemple compresser vos images, vos SVG ou gérer vos listes de tâches.
Les fonctions jusque là réservées aux applications natives, plein écran, hors connexion, notifications, fonctionnement en arrière plan, accès au GPS, au Bluetooth etc, sont aujourd’hui regroupées sous le terme PWA.
Jamstack, le stéroïde du SSG
Le titre parle de “révolution frontend”, mais jusque là, rien de bien nouveau me direz-vous : les développeurs frontend peuvent faire des sites statiques… c’est ce qu’ils ont toujours fait.
Site statique ou non, on a tout de même certains besoins – immédiatement identifiés ou qui arrivent au fil de l’eau – les commentaires, la recherche, éditer sans passer par un éditeur de code etc.
La Jamstack arrive à une période où l’on migre un peu tout vers le cloud et c’est en réalité bien de cela qu’il s’agit. L’idée de la Jamstack est que l’on veut se concentrer sur le front (d’où le lien avec le site statique) et que l’on confie le reste à des services cloud (recherche, paiement, base de données, authentification…).
Définition de la Jamstack

Le terme a été créé par Mathias Biilmann, le fondateur de Netlify, un hébergeur cloud dédié aux sites statiques et à la Jamstack. La plupart des images précédentes sont d’ailleurs tirées des slides d’une de ses conférences.
JAM signifie JavaScript, APIs et Markup. La Jamstack désigne tous les sites/webapps dont le contenu est pré-généré (processus de build ou pages statiques) à partir de Markup (Markdown, JSON, HTML) et dont l’interactivité repose exclusivement sur le JavaScript côté client et l’usage d’APIs.
Tout site de la Jamstack a comme point commun de ne pas dépendre d’un langage côté serveur et d’être pré-compilé. Un site dédié est créé pour évangéliser la communauté et expliquer les mérites de cette nouvelle stack.
Bien entendu, une stack LAMP classique reposait aussi souvent sur des services externes. Par exemple, un WordPress/WooCommerce utilisera un service de paiement externe (que l’on appelle cela cloud ou pas, il ne sera donc pas complètement autonome).
La différence est qu’en mode Jamstack, on pousse l’externalisation à l’extrême : il n’y a plus de serveur du tout et plus vraiment de backend. On utilisera peut-être une base de données (cloud) pour stocker les produits et leurs prix (certains stockent tout directement via l’API Stripe), les comptes clients pourront être gérés via des fonctions serverless, les emails seront envoyés via Sendinblue ou Mailchimp etc.
Évidemment, l’avantage est que comparé à une stack classique, on ne se soucie absolument pas de l’infrastructure, des mises à jour, de la sécurité etc. En somme, Jamstack = Cloud.
Le terme Jamstack regroupe donc des choses bien différentes :
- un SSG qui prend du Markdown en entrée (ou texte brut ou HTML) et recrache un site en HTML (par exemple ce site),
- une application full JS avec un framework tel que React qui appelle de nombreux services externes.
Si je résume de manière assez prosaïque, la Jamstack, c’est du site statique qu’on saupoudre de Serverless au besoin. Frank de Jamstatic.fr, nous offre une synthèse en français du site Jamstack.wtf.
Maintenant que vous savez vraiment en quoi consiste ces différentes technologies, voyons comment se frayer un chemin dans cette jungle technologique.
Choisir son SSG
Nous l’avons dit, il existe de très nombreux SSG. Le site Jamstack les regroupe presque tous, c’est donc un bon point de départ si vous n’avez pas déjà un SSG préféré.
De manière générale, il y a trois grandes méthodes pour générer le contenu. Cela dépend beaucoup du type de projet :
- Le volume de contenu est limité et il change peu (site vitrine…) :
- vous codez le HTML à la main,
- vous utilisez un SSG minimaliste intégrant un moteur de template afin de placer les portions répétitives (header, footer, menu…) dans des templates séparés et de bénéficier de l’interpolation de variables (pour centraliser des données dans un fichier de config par exemple).
- Le volume de contenu est plus conséquent (blog, magazine, site d’entreprise, e-commerce…) et/ou il aura tendance à souvent évoluer (éditions, ajouts…), vous vous dirigez dans ce cas vers un SSG qui génère le HTML à partir de markup (Markdown en général, mais d’autres existent).
- Lorsque l’architecture du contenu est très complexe ou de grande ampleur, il est possible d’utiliser des CMS Headless, lesquels délivrent le contenu via des API. On se dirigera alors vers un SSG capable de récupérer le contenu depuis une API ou vers un framework web tel que React, Angular ou Vue.js.
Dans le premier cas, j’utilise Dopamine. Il s’agit d’un SSG que j’ai créé, basé sur npm et EJS, un langage de template dont la syntaxe est celle de JavaScript. Il n’y a donc rien à réapprendre et on s’évite juste de faire des copier-coller dans tous les sens, parfaitement adapté pour les sites marketing.
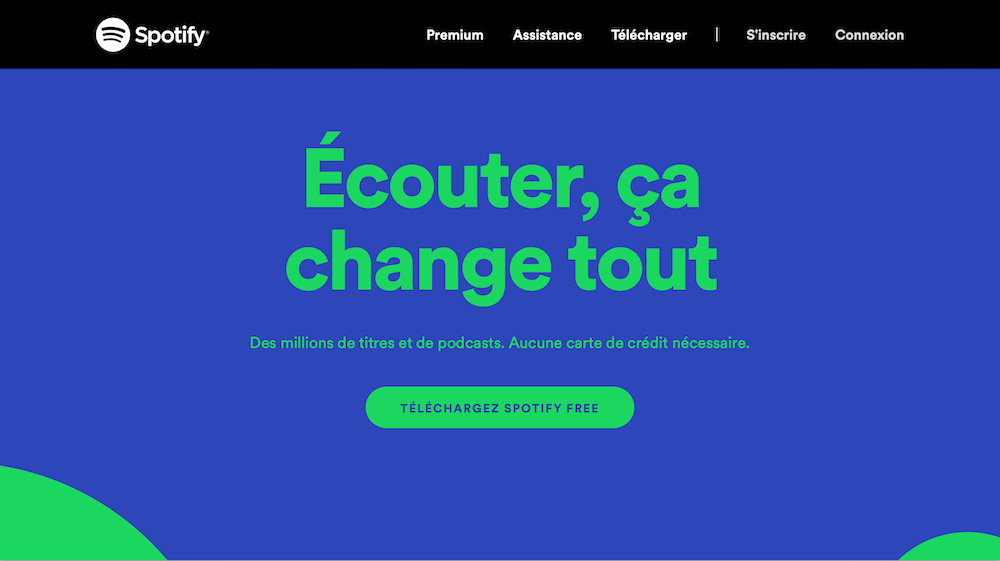
Dans un cas de figure comme celui-ci, on pourrait presque se contenter de coder le tout à la main sans SSG. Un générateur simple comme Dopamine offre un peu plus de confort avec du templating, l’inclusion d’un pré-processeurs CSS et la compilation du JavaScript.
Dans le second cas, en tant que développeur JavaScript, j’utilise Hexo (ce site l’utilise). C’est mon SSG de choix car il est développé en JavaScript, qu’il est rapide, très bien documenté et qu’il dispose d’un nombre de plugins et de thèmes impressionnants.
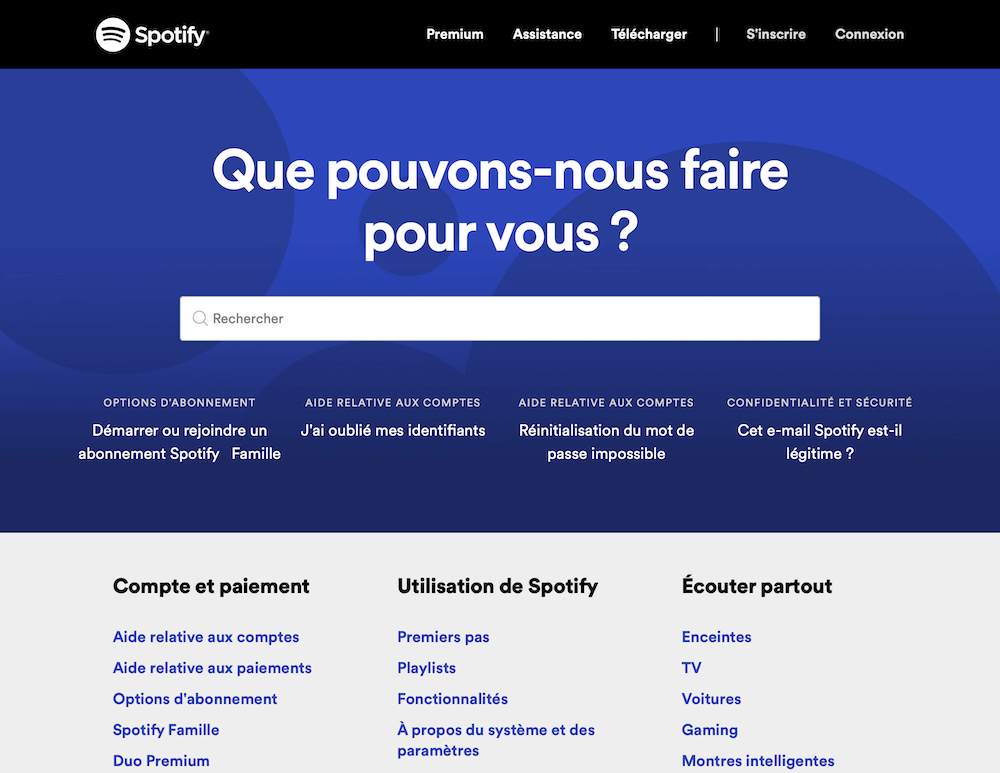
On peut ici légitimement penser que le contenu n’est pas géré par les développeurs. Un SSG comme Hexo répondrait bien à cette problématique : tout est mis en place par les développeurs mais le contenu est totalement gérable sans toucher au code. Le contenu sera réparti entre des fichiers Markdown et Yaml qui pourront être édités sans connaissances particulières. Chaque fichier Markdown dispose d’ailleurs d’un en-tête Yaml afin de définir des métadonnées : de la meta description au nom de l’auteur, vous y mettez ce que vous voulez, le SSG pourra récupérer ces éléments pour les utiliser dans les templates.
La communauté d’Hexo est très développée en Asie (son principal développeur est Taïwanais). De ce fait, on verra plus souvent des articles sur Eleventy (s’écrit aussi 11ty) sur les sites et blogs francophones et anglophones. Néanmoins, toutes la documentation et l’aide dont on peut avoir besoin se trouve en anglais et l’offre de plugins est incomparablement plus riche du côté d’Hexo.
Si le contenu n’est accessible qu’au travers d’API, on veillera à utiliser un SSG compatible avec cette méthode de récupération. Parmi les SSG JavaScript, à la fois Hexo et 11ty en sont capables, mais on a également souvent recours à des SSG basés sur React et Vue.js : Next.js, Gatsby et Nuxt.js.
Ces derniers SSG permettent bien entendu également de consommer du Markdown. On les préférera la plupart du temps pour des sites complexes et lorsque les sources de données sont multiples.
Choisir son hébergeur
Dans sa forme la plus simple, le site statique n’est qu’un ensemble de fichiers statiques. Virtuellement tous les hébergeurs conviendront donc. J’ai hébergé des sites statiques sur des mutualisés, des VPS, etc.
Un simple mutu fait donc l’affaire, lorsque le site est build, on peut le déployer de la manière qui nous plaît. J’ai par exemple déjà utilisé les modules sftp et rsync pour déployer un site respectivement sur un hébergement mutualité et un serveur virtuel.
Il existe cependant des hébergeurs spécialisés. Ces derniers permettront de se connecter directement au repo Git et s’occuperont automatiquement de build et deploy dès que des modifications seront effectuées sur une branche donnée. Ainsi, vous ne vous occupez plus que de pusher, le reste est automatique !
En outre, ces hébergeurs apportent un peu de dynamique aux sites statiques : gestion des formulaires, identification des utilisateurs (pour un espace membre par exemple), exécution de fonctions cloud…
Les deux principaux sont Vercel et Netlify. Leurs fonctionnalité sont assez similaires, chacun ayant toutefois ses domaines de prédilections. Netlify permet de facilement ajouter des fonctions aux sites statiques grâce à son catalogue de plugins. Vercel se distingue dans une fine gestion des fonctions cloud et permet le pre-rendering ; Vercel est développé par les auteurs de Next.js.
J’utilise pour ma part Netlify mais Vercel pourrait tout aussi bien convenir pour mes besoins. Pour plus d’informations à ce sujet, le mieux est de lire les retours de personnes ayant utilisé les deux : Vercel vs Netlify et retour d’expérience entre Vercel, Netlify et Azure Static WebApp.
Nous avons parlé de Git sans jamais mentionner les endroits où la plupart de nos dépôts sont stockés. GitHub et GitLab permettent tous les deux d’héberger des sites statiques : GitHub Pages et GitLab Pages. Comme ces deux platformes offrent des minutes de build dans tous leurs plans, il est possible de déclencher un build dès lors que de nouvelles modifications sont pushées.
Les deux services offrent des fonctions spécifiques afin de pouvoir gérer les 404 et des redirections basiques. Pour plus de contrôle et de performances, il est même possible de servir ces Git Pages depuis Cloudflare.
Positionner Cloudflare en front permet un contrôle assez fin de la réécriture et redirections, options qui font notamment défaut à Netlify. Il n’est par exemple actuellement pas possible de forcer la redirection de tout monsite.com/page/index.html vers monsite.com/page/ ni monsite.com/test.html vers monsite.com/test, ce que je trouve assez dommageable.
D’ailleurs, puisque l’on parle de Cloudflare, ce dernier aussi est monté dans le train du Serverless et de la Jamstack. Il propose des Function as a Service (FaaS), ainsi qu’un hébergement spécifique pour les sites statiques. De quoi concurrencer Vercel et Netlify. Il s’adresse toutefois aux développeurs avec un plus grand besoin de contrôle (au détriment d’une complexité supérieure).
Performances
En terme d’hébergement, il est important de mentionner les performances. Je peux facilement comparer car le présent site était il y a un an encore sur WordPress.
Mon site WordPress était ultra-optimisé avec un thème codé à 100% par mes soins, de la même manière que le thème actuellement utilisé avec Hexo. De ce fait, les performances ne bénéficient pas d’un boost notable.
En revanche, j’ai essayé différents hébergements pour le site statique. Actuellement, ce site utilise Netlify. Cependant, la recherche est effectuée directement en front et les commentaires sont gérés par Jamments une API de commentaire open source dont je suis l’auteur. De ce fait, n’importe quel hébergeur ferait l’affaire.
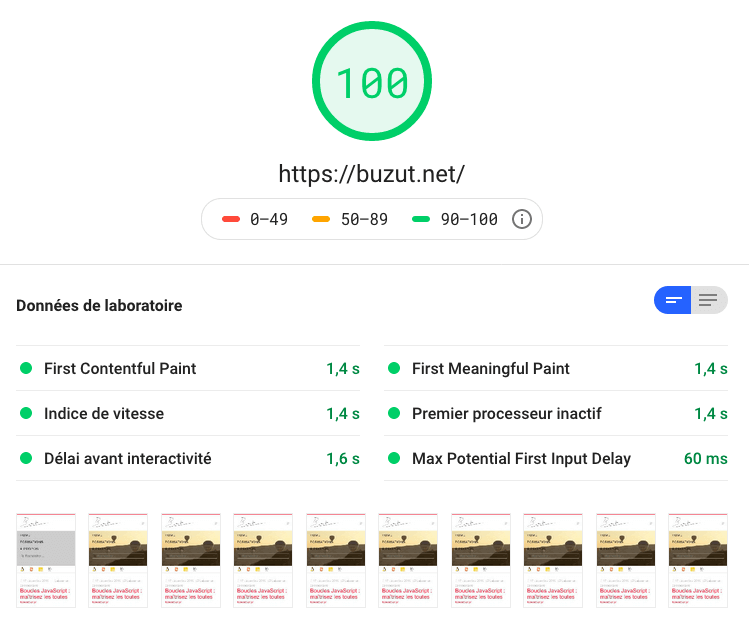
J’ai tout d’abord utilisé un server virtuel sur lequel j’avais d’autres sites webs, dont des WordPress. Les fichiers étaient simplement servis par Apache, configuré aux petits oignons. On voit qu’on obtient de très bonnes performances avec cette configuration toute simple, mais efficace.
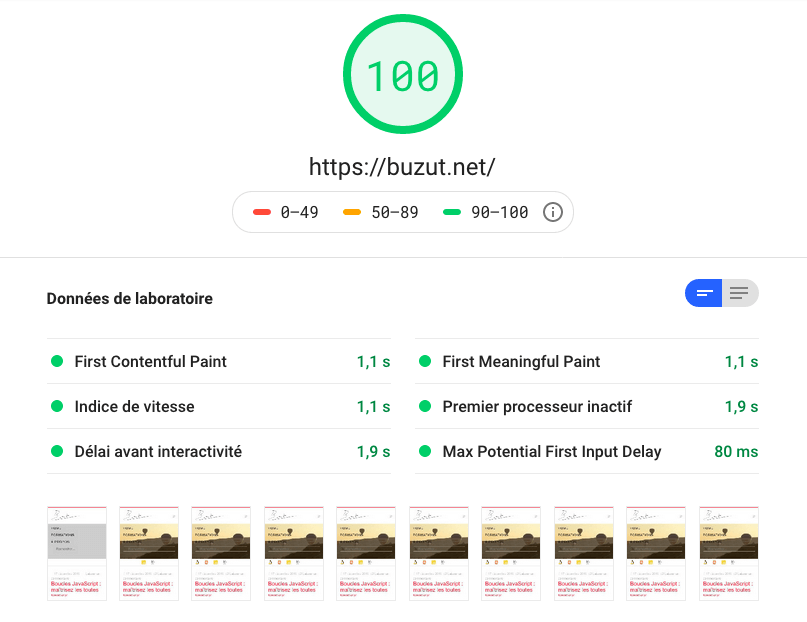
Ensuite, j’ai voulu simplifier le workflow et ne plus du tout avoir à gérer de serveur : un VPS, comme un serveur dédié, nécessite une configuration et une maintenance manuelle, peut poser problème en cas de très fort trafic etc. J’ai donc naturellement utilisé GitLab pages (puisque c’est là que j’héberge le code du blog) et placé Cloudflare par dessus.
Notez qu’on obtient des performances raisonnables même sans Cloudflare, mais on bénéficie d’un peu moins d’options de configuration.
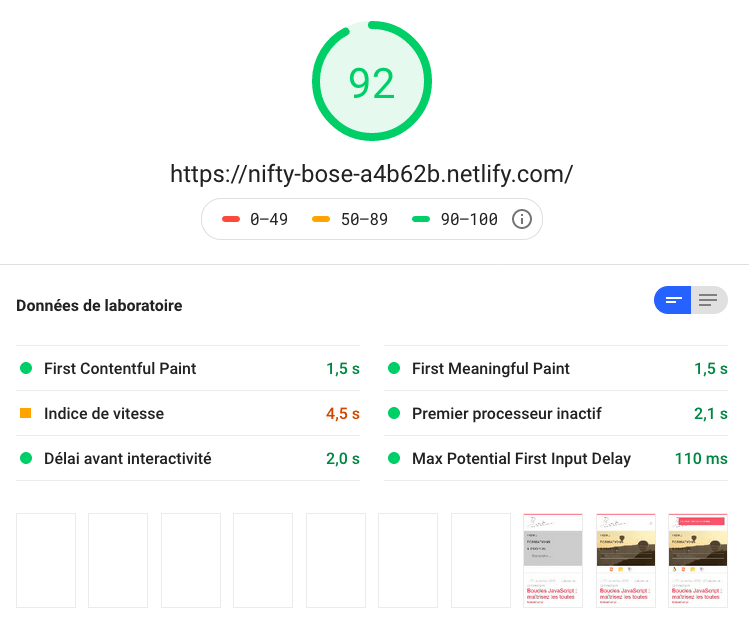
En dernier lieu, le même site hébergé chez Netlify obtient, malgré tout le discours marketing, de moins bonnes performances. On obtient en échange une facilité de deploy inégalable et de nombreux plugins pour ajouter du dynamique à son site statique. De plus, Netlify permet de se connecter à de très nombreux outils pour gérer le back-office, c’est un gros plus.
Choisir son back-office
Lorsque l’on parle de site statique et de SSG, de manière classique, le contenu est géré au même niveau que le code : les fichiers sont côte à côte, tout s’édite via l’éditeur de code/texte et l’ensemble est versionné (en général dans Git).
Cette expérience peut convenir aux développeurs, mais s’il y a ou doit avoir dans l’équipe des rédacteurs non développeurs, cela peut vite devenir compliqué. Par ailleurs, force est de reconnaître que l’expérience que l’on a avec les CMS traditionnels me paraît plus plaisante de ce côté là.
Personnellement, lorsque je veux modifier une typo, je n’ai pas envie d’ouvrir mon éditeur de code, commiter ma modification, puis la pusher (ou build & deploy selon la config du projet).
C’est là qu’entrent en jeux les CMS dit headless. Ce sont des interfaces d’éditions totalement découplées du front. Leur objectif est de gérer le contenu, rien d’autre. Contrairement aux CMS classiques, ils ne s’occupent pas de gérer le contenu.
Il y a principalement deux types de CMS headless :
- les CMS basés sur Git, on les utilise pour gérer des sites dont les sources sont principalement des fichiers texte (Markdown, Yaml, JSON),
- les CMS API driven, permettent de gérer des sites de plus grande ampleur ou plus complexes.
L’approche Git-based est tout à fait viable pour les sites d’envergures. À titre d’exemple, Smashing Magazine utilise Git et Netlify.
En revanche, un gros site e-commerce avec des milliers de références aura plutôt tendance à utiliser un CMS de la seconde catégorie. Ce choix est fortement corrélé au type de SSG précédemment abordé. Par ailleurs, le contenu issu d’un CMS API-based sera plus facilement consommé par différents terminaux (site, application mobile, montre connectée, assistant vocal, panneau d’affichage…).
Je ne vais pas m’éterniser sur les comparaisons entre les deux. Pour plus de détails, vous pouvez lire l’article de Jamstatic à ce sujet.
Git-based
En ce qui me concerne, ce que je n’apprécie pas tellement avec l’approche Git-based, c’est d’avoir tous mes fichiers au même endroit (code et contenu). C’est un avantage pour certains, moi, ça m’ennuie un peu pour les projets dans lesquels il y a beaucoup de contenu et qu’il est modifié la plupart du temps indépendamment du code.
J’ai en effet pour habitude d’avoir des commits atomiques proprement nommés. Lorsque l’on modifie principalement du contenu, cette règle devient plus compliquée à respecter. Ce n’est pas du tout le cas lorsqu’il s’agit d’un site marketing/vitrine où il y a moins de contenu et où celui-ci est intimement lié au design et donc au code.
Pour remédier à cette situation, je divise souvent le projet en deux repos : un pour le code à proprement parler et l’autre pour le contenu. Mis à part cela, c’est la configuration la plus simple et la plus portable. Votre contenu est dans un format standard flat file (Markdown, Yaml, JSON) et vous pouvez donc changer de CMS comme de SSG en un rien de temps.
Une grande partie des CMS Git-based se destinent à un SSG particulier. Il y en a cependant aussi des généralistes. Vous trouverez une liste assez complète sur le site Jamstack.org. Nous allons nous concentrer sur les deux plus populaires parmi ceux prenant en charge tous les SSG.
Netlify CMS
Netlify CMS est un outil open source (vous pouvez l’utiliser indépendamment de Netlify) qui offre des fonctions de CMS pour les projets hébergés sur GitHub, GitLab et Bitbucket).
Il est possible de placer le code du CMS directement dans la codebase du projet. Ce CMS offre une interface simple et permet de gérer des projets relativement simple. Il permet toutefois de gérer un workflow de publication permettant une validation par un éditeur avant publication des contenus et permet également l’open authoring.
Néanmoins, Il ne convenait pas pour le présent site car il était impossible d’avoir plusieurs niveaux de répertoires : j’utilise un répertoire regroupant toutes formations/ pour les formations, et chacune possède plusieurs chapitres regroupés dans un répertoire par formation. Cela me permet d’avoir des urls du genre /formations/formation_y/chapitre_z/ et ça n’était pas possible dans Netlify CMS.
Si vous désirez en savoir plus sur la manière de le configurer, je vous invite à regarder cette vidéo assez complète.
Forestry
C’est vraiment la solution qui a retenu mon attention. Il s’agit d’un SaaS et non d’une solution open source. Vous ne vous souciez donc pas de l’hébergement, et vous devrez prendre un abonnement pour accéder à certaines fonctionalié.
Le tiers gratuit est cependant assez généreux et permet de bien tester la solution. Comme le CMS de Netlify, il permet de se connecter à GitHub, GitLab et Bitbucket et y ajoute aussi Azure DevOps. Les fonctionalités sont plus étendues que son cousin.
On aura notamment accès à l’édition avancée de répertoires contenant des sous-répertoires, des étideurs spéciaux pour des data files – ces fichiers JSON ou Yaml qui contiennent des données structurées consommées par le SSG (structure de menu, informations de contact, configuration de layout…).
Par ailleurs, on pourra procéder à la configuration directement depuis l’interface web sans avoir à s’égarer dans le fichier de config JSON.
API-based
Contrairement aux CMS Git-based, ceux-ci sont destinés à un très large panel de solutions. Nous l’avons dit, le contenu accessible via une API peut tout aussi bien être consommé par un SSG que par une webapp, une application mobile ou desktop, un assitant vocal etc.
C’est l’un des principaux avantages de ce type de CMS. Par ailleurs, il est possible de requêter les données de manière dynamique depuis le site ou l’application et cela offre de nombreux avantages :
- génération de page selon la requête de l’utilisateur ou ses préférences (filtres…),
- possibilité de faire de la recherche sur un volume de données important,
- permet de ne pas avoir à relancer un build dès qu’un contenu est modifié (primordial dans les cas où le contenu change constamment).
Le choix est immense ! Contrairement aux CMS Git-based, le choix de CMS API-driven est énorme. Même des CMS classiques comme Ghost, WordPress ou Drupal disposent d’API permettant d’en récupérer le contenu. Dans ce cas, le CMS ne gère que le contenu, il ne s’occupe pas de rendre et d’afficher les pages web et peut être considéré comme headless.
Par ailleurs, de nombreux services n’étant absolument pas destinés à être des CMS peuvent le devenir. C’est par exemple le cas de Trello et Google Sheets.
Si un service propose une interface pour entrer des données et une API pour les récupérer, cela peut potentiellement devenir un CMS headless. Bien entendu, en plus des hacks précédemments mentionnés, il existe de nombreux services dédiés à cet usage.
Quoi qu’il en soit, avant d’adopter une solution API-driven, il faut bien être conscient de ses inconvénients :
- les possibilités offertes par l’API à votre disposition peuvent vous limiter (recherche fulltext, filtres avancés…),
- les CMS et leurs API ont des limites d’usage : stockage, nombre de requêtes par min/heure/jour…
- vendor lock-in : on retombe dans le même schéma qu’avec les CMS traditionnels, le contenu n’est pas facilement portable d’une solution à l’autre.
Parmi les solutions les plus populaires, il se trouve les services cloud et les solutions open source à héberger soi-même. De nouveau, les deux côtés ont leurs avantages et leurs inconvénients. Une chose est certaine, héberger soit-même son CMS headless, qu’il s’agisse d’un WordPress ou d’une solution plus “moderne”, cela revient tout de même à retrouver les inconvénients de la gestion et de la maintenance backend classique.
Certains CMS sont plus spécialisés dans certains domaines que d’autres, mais de manière générale, vous définissez un modèle de donnée et les relations que ces données possèdent entre elles (un modèle comments et un modèle articles, ce dernier modèle peut référencer des comments). Une fois cela fait vous pouvez ajouter des données et les requêter.
Il va m’être difficile de vous présenter l’ensemble des possibilités du côté de l’offre API-driven. Le plus connu est incontestablement Contentful, mais Sanity, DatoCMS, ButterCMS et Prismic sont aussi populaires. Tous proposent une API GraphQL, certains proposent aussi REST.
Du côté des open source, le plus connu est sans conteste Strapi, lequel offre du GraphQL ou REST au choix et supporte les principales bases SQL ainsi que SQLite et MongoDB. Keystone – qui gagne en popularité – ne propose quant à lui que le GraphQL et supporte MongoDB et PostgreSQL. Strapi et Keystone sont codés en JavaScript.
Du côté de PHP, Cockpit est assez populaire et semble offrir une interface élégante et efficace. Cockpit supporte SQLite et MongoDB et offre une API JSON REST.
Face à tant de choix, mieux vaut se diriger vers la section Headless CMS de Jamstack.org et de voir celui qui correspond le mieux aux critères du projet.
Conclusion
On réalise que les sites statiques ont de réels atouts et des usages bien définis. Les générateurs de sites permettent de s’affranchir des tâches manuelles et répétitives. De leur côté, les workflows modernes basés sur Git permettent de se concentrer sur le code et d’automatiser la génération et le déploiement des modifications.
Enfin, les APIs, lorsqu’elles sont appellées en front, permettent de suppléer aux déficits inhérents des sites statiques en leur adjoingant la puissance du cloud, quand bien même, techniquement parlant, il s’agit plus de cloud et de serverless que de site statique.
On notera également que les CMS traditionnels trouvent leur place dans cet environnement complexe : ils permettent d’une part de servir de headless CMS en récupérant le contenu de leur API, mais peuvent aussi être utilisés comme SSG.
WordPress possède plusieurs plugins à cet effet : Static HTML Output et WP2Static. Shifter est un hébergeur spécialisé dans le WordPress statique : vous utilisez du WordPress, mais Shifter ne sert que du HTML statique et vous permet de paramétrer les règles de build de votre site.
Vous l’aurez compris, les possibilités sont infinies, l’ancien fait son renouveau et chaque besoin trouve sa solution !
Commentaires
Rejoignez la discussion !