Analyser les logs avec Graylog
Graylog est un système qui permet de centraliser, monitorer et d’analyser les logs. Ainsi, les logs de vos différents serveurs et applications se retrouvent tous consultables au même endroit. Cela permet bien évidemment une grosse économie de temps, mais également de facilement pouvoir comparer et corréler les logs de vos différents services entre eux. Enfin, il est possible de configurer des analyses automatiques qui seront ainsi capables de vous avertir en temps réel si l’un des paramètres que vous spécifiez est atteint. Convaincu ? Alors allons-y !
Grand concurrent de la célèbre stack Elasticsearch, Graylog est conçu dès le départ à 100% pour la gestion des logs. Il est donc dédié à 100% à cet usage et cela se ressent au niveau de son interface. Cependant, les deux compétiteurs ont aussi des points communs : ils sont tous deux open source, mais surtout, ils utilisent tous les deux le même moteur d’indexation, à savoir, Elasticsearch. Vous disposez ainsi de tableaux de bords regroupant vos métriques critiques tout en ayant la possibilité de rechercher efficacement parmi des térabytes de données (admettez que c’est mieux qu’un grep !).
L’installation
Graylog peut être installé de multiples manières : de la compilation des sources à l’automatisation complète via des conteneurs Docker, tout y est. Il suffit de jeter un œil au Git de Graylog pour s’en convaincre. Il y a même un package omnibus qui se charge d’installer toute la stack pour vous !
Nous n’allons pas ici compiler l’ensemble mais nous utiliserons les paquets de notre distribution (Debian flavoured dans le cas présent). Cela nous permettra d’avoir un bon niveau de compréhension de l’architecture d’ensemble et d’être à l’aise avec sa configuration.
Graylog possède deux dépendances, MongoDB et Elasticsearch. Nous allons donc commencer par installer ces derniers. Pour l’exemple, nous serons sur une machine Ubuntu en mode standalone, c’est à dire que tout se trouve sur un seul et même serveur.
MongoDB
La plupart des paquets des distributions sont clairement à la traîne pour Mongo. Il faut donc ajouter le repo contenant les versions les plus récentes. Selon votre distribution et afin de rester le plus à jour possible, le mieux est d’aller voir directement les instructions sur le site officiel. Néanmoins, dans le cas de Debian 8 et d’Ubuntu 16.04, et à l’heure où j’écris ces lignes, voici les commandes à exécuter :
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927
# pour debian
echo "deb http://repo.mongodb.org/apt/debian wheezy/mongodb-org/3.2 main" | tee /etc/apt/sources.list.d/mongodb-org-3.2.list
# pour ubuntu
echo "deb http://repo.mongodb.org/apt/ubuntu xenial/mongodb-org/3.2 multiverse" | tee /etc/apt/sources.list.d/mongodb-org-3.2.list
apt-get update
apt-get install -y mongodb-orgPour Ubuntu 16.04, il faudra également créer manuellement le script systemd. Dans /lib/systemd/system/mongod.service :
[Unit]
Description=High-performance, schema-free document-oriented database
After=network.target
Documentation=https://docs.mongodb.org/manual
[Service]
User=mongodb
Group=mongodb
ExecStart=/usr/bin/mongod --quiet --config /etc/mongod.conf
[Install]
WantedBy=multi-user.targetIl n’y a rien de particulier à configurer concernant Mongo. Puisqu’on est en local, la connexion peut-être laissée sans mot de passe.
Elasticsearch
Graylog 2.x nécessite Elasticsearch 2.3.x est compatible avec les dernières versions d’Elasticsearch, lequel nécessite Java 8. Installons donc open-jdk dans la mesure où il est déjà libre et déjà présent dans nos dépôts (contrairement au JDK d’Oracle).
apt-get install openjdk-8-jre-headlessIl ne nous reste plus qu’à installer Elastic. Là encore, plusieurs solutions s’offrent à nous, je vous invite évidemment à consulter la page d’installation d’ES afin d’obtenir les instructions les plus à jour et adaptées à votre distribution. Me concernant, je trouve que le plus pratique est de recourir aux dépôts afin de pouvoir également profiter des mises à jour.
# ajout de le clef & repo update et install
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | apt-key add -
echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list
apt-get update
apt-get install -y elasticsearchEnsuite, pour qu’ES démarre automatiquement au boot de la machine, il faut configurer les script d’initialisation. Systemd tend à être le nouveau standard (Debian 8, Ubuntu 16.04 et dérivés) mais sysV est encore utilisé sur de très nombreux systèmes.
# s'assurer que ce petit monde se lance au boot
# systemd
systemctl daemon-reload
systemctl enable elasticsearch.service
# SysV init
update-rc.d elasticsearch defaultsOn ira ici modifier le fichier de configuration se trouvant à /etc/elasticsearch/elasticsearch.yml :
# modifications directes via sed
sed -i -r 's/# cluster.name: [a-zA-Z0-9-]+/ cluster.name: graylog/' /etc/elasticsearch/elasticsearch.yml
sed -i -r 's/# node.name: [a-zA-Z0-9]+-1/ node.name: graylog-server/' /etc/elasticsearch/elasticsearch.yml
sed -i 's/# node.max_local_storage_nodes: 1/ node.max_local_storage_nodes: 1/' /etc/elasticsearch/elasticsearch.ymlEn résumé, on définit le nom du cluster ainsi que celui de la node (dans notre cas nous avons un cluster d’une seule node) et on précise à ES que l’on veut avoir une seule node maximum. Il n’y a, dans le cas présent, pas d’intérêt à avoir plus d’une node sur le même serveur.
Graylog serveur
Maintenant que nos dépendances sont satisfaites, entrons dans le vif du sujet, j’ai cité, Graylog ! Une fois n’est pas coutume, vous pouvez consulter les instructions sur la page de Graylog afin d’avoir les détails pour votre propre distribution. Pour nos amis Debian et Ubuntu, voici les commandes :
apt-get install apt-transport-https
wget https://packages.graylog2.org/repo/packages/graylog-2.0-repository_latest.deb
dpkg -i dpkg -i graylog-2.0-repository_latest.deb
apt-get update
apt-get install -y graylog-serverÉvidemment, nous voulons que Graylog démarre au boot. Pour les OS utilisant systemd, il faudra donc faire systemctl enable graylog-server, pour SysV c’est update-rc.d graylog-server defaults 95 10.
Ici aussi, nous allons devoir modifier un peu la configuration par défaut dans /etc/graylog/server/server.conf :
# utilisation d'une chaine pour saler les mots de passe des utilisateurs enregistrés
# on peut la générer avec la commande : openssl rand -base64 32
sed -i 's/password_secret =/password_secret = MOT_DE_PASSE/'
# le login de l'utilisateur root
sed -i 's/#root_username = admin/#root_username = VOTRE_LOGIN/'
# Il s'agit ici du mot de passe du compte root hashé avec sha2
# on peut le générer avec la commande :
# echo -n "MOT_DE_PASSE_ROOT" | shasum -a 256 | awk '{print $1}'
sed -i 's/root_password_sha2 =/root_password_sha2 = MOT_DE_PASSE_HASH/' /etc/graylog/server/server.conf
# email du compte root
sed -i 's/#root_email = ""/root_email = "ROOT_EMAIL"/' /etc/graylog/server/server.conf
# configuration de la timezone
# CET pour UTC+1 soit Paris et autres capitales Européennes
sed -i 's/#root_timezone = UTC/root_timezone = CET/' /etc/graylog/server/server.conf
# nombre de shards ES, comme nous n'avons qu'une node, ce n'est pas utile d'avoir plusieurs shards
sed -i 's/elasticsearch_shards = 4/elasticsearch_shards = 1/' /etc/graylog/server/server.conf
# ici, idem, on sait immédiatement où trouver les nodes de notre cluster (un seul en localhost !)
sed -i 's/#elasticsearch_discovery_zen_ping_multicast_enabled = false/elasticsearch_discovery_zen_ping_multicast_enabled = false/' /etc/graylog/server/server.conf
sed -i 's/#elasticsearch_discovery_zen_ping_unicast_hosts = 127.0.0.1:9300', replace: 'elasticsearch_discovery_zen_ping_unicast_hosts = 127.0.0.1:9300/' /etc/graylog/server/server.confVous êtes bien entendu encouragés à regarder plus en détails l’ensemble du fichier de configuration, il est dans l’ensemble assez explicite. Par ailleurs, nous ne l’avons pas mentionné ici mais l’API peut-être passée en TLS aussi.
Graylog supporte le TLS, aussi bien pour l’API que pour le serveur web. Pour ma part, comme à mon habitude, je préfère laisser comme cela, placer un reverse proxy devant et effectuer le chiffrement au niveau du reverse. Sachez néanmoins que, comme Graylog expose son API, votre navigateur effectue directement les requêtes auprès de l’API pour récupérer les données. Ainsi, je créé deux sous-domaines, un pour l’interface web, par exemple graylog.buzut.fr et un pour l’API api.graylog.buzut.fr.
Pour que cette configuration soit fonctionnelle avec un reverse, il faut aussi configurer le web_endpoint_uri. Dans le cas d’un sous domaine avec “api”, nous aurions donc :
web_endpoint_uri = https://api.graylog.buzut.fr:443/Ensuite, n’oubliez pas de créer les deux vhosts au niveau de votre proxy et le tour est joué !
Faites péter les logs !
Une fois que tout est en place, il ne reste plus qu’à rapatrier les logs de vos différents serveurs et applications vers Graylog. Pour cela, il faut avant tout ouvrir un input afin que votre serveur écoute sur un port donné.
Vous vous rendez dans system / inputs > inputs, vous choisissez un type d’input, ici le GELF TCP, vous pouvez définir vos ports, choisir d’utiliser le TLS etc.
Je fais ici une petite digression, mais sachez que si vous voulez rapidement tester la connectivité, vous pouvez vous aidez de CURL ou de Netcat pour des connexions en HTTP et TCP ou UDP respectivement.
# connexion HTTP, petit coup de curl
curl -XPOST http://graylog.server.com:12202/gelf -p0 -d '{"version": "1.1", "host":"api.buzut.fr", "short_message":"Hello there", "full_message":"Backtrace here\n\nmore stuff"}'
# et en UDP (notez l'option -u)
echo -e '{"version": "1.1", "host":"api.buzut.fr", "short_message":"Hello there", "full_message":"Backtrace here\n\nmore stuff"}' | nc -u graylog.server.com 12202
# enfin en tcp
echo -e '{"version": "1.1", "host":"api.buzut.fr", "short_message":"Hello there", "full_message":"Backtrace here\n\nmore stuff"}\0' | nc graylog.server.com 12202Vous noterez qu’en TCP, on ajoute un \0 – le null character – afin de délimiter les packets TCP les uns des autres, dans un flux qui est continu. En effet, ce problème n’existe pas en UDP qui possède des paquets de taille fixe.
Gelf s’intègre à de nombreuses solutions, par exemple, si vous utilisez Winston comme outil de logging, plusieurs solutions s’offrent à vous pour (dont une dont je suis l’auteur) avoir un transport spécial Graylog directement dans Winston vous pouvez configurer Gelf comme un transport et automatiquement envoyer tous les logs de votre application vers Graylog.
Dans l’absolu, tous les logs n’ont pas besoin d’être centralisés. Pour ma part, je récupère les logs d’erreurs du serveur web s’il y en a un, le syslog et enfin, bien évidemment, les logs d’erreurs de mes applications (géré directement dans le code de l’app). Pour ce qui est du syslog, j’ai écrit un petit collecteur en nodejs afin de lire le fichier de logs (syslog, Apache2 ou Nginx error.log) et d’envoyer au fur et à mesure tout ça à Graylog au format GELF via TCP ou HTTP.
Le module s’installe très simplement avec npm install -g log2gelf et vous n’avez ensuite qu’à le lancer au démarrage du serveur. Par exemple, pour envoyer le syslog, je créé un petit script qui s’assure que log2gelf est bien lancé et je l’appelle régulièrement via une crontab :
#!/bin/bash
if ! ps aux | grep -v grep | grep "/usr/bin/nodejs /usr/bin/log2gelf"
then
/usr/bin/log2gelf bztBlog graylog.buzut.fr 12201 tcp true syslog /var/log/syslog 2>&1 | logger &
fiCe script, que je place dans /usr/local/sbin/startLog2Gelf.sh est appelé toutes les minutes via la crontab de root :
* * * * * /usr/local/sbin/startLog2Gelf.shGraylog au quotidien
À ce stade, nous avons configuré Graylog sur notre serveur de monitoring et nous avons un ou plusieurs serveurs qui envoient des données vers Graylog. Parfait.
Pour l’instant, la seule manière d’exploiter ces données est de se rendre dans l’interface de Graylog et d’y effectuer des recherches. Nous en conviendrons aisément, c’est déjà pas mal. Mais au travers des dashboard et des streams, Graylog peut offrir bien plus !
Les dashboards
Le terme est tellement courant que vous devez déjà avoir une idée de l’utilité de la chose. Dans Graylog, un dashboard permet de sauvegarder des requêtes et d’afficher, sur le dashboard donc, les résultats de ces requêtes actualisés en temps réel. On pourra donc avoir un dashboard présentant le compte des messages ou alertes d’un certain programme.
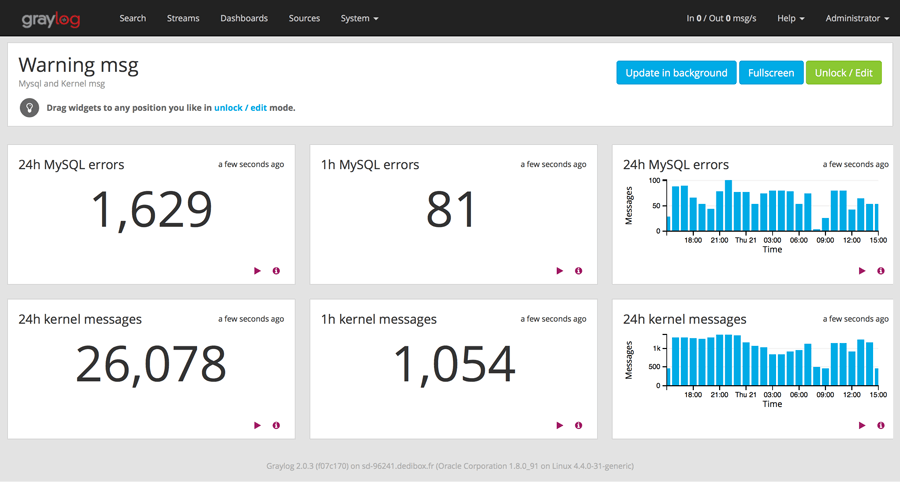
Il suffit de se rendre dans l’onglet dashboard et de cliquer sur “Create new” pour créer un nouveau dashboard, vide. Ensuite, lorsque vous effectuer des recherches, il vous faudra exporter les widgets vers le dashboard de votre choix. C’est tout !
Pour en savoir plus sur les dashboard et les différents widgets disponibles, je vous invite à lire la doc dédiée.
Les streams
Moins évidents que les dashboards, les streams permettent d’analyser et de traiter les logs en temps réel. On compte deux principaux avantages aux streams. Le premier est une fonction de routing. Chaque stream présente en effet des conditions, ainsi, chaque log sera routé – ou pas – dans un stream.
Si par exemple je défini qu’un stream ne contient que les messages de la crontab, lorsque je me rends sur le stream en question, je n’ai que les messages en question. La grosse différence en terme de performance avec une recherche à posteriori sur des conditions comparables est que les streams sont traités en temps réel. Ainsi, sur un nombre de logs important, une recherche nécessitera une puissance de calcul importante et nécessitera potentiellement du temps, tandis que pour le stream, tout est déjà pre-calculé. On peut ainsi effectuer d’autres recherches, de manière plus flexible et plus rapide, dans le stream.
Le second avantage est qu’avec les streams, il est possible de déclencher des alertes automatiquement (email, slack, etc.). Vous pouvez déclencher une alerte au dessus d’un certains nombre de messages par unité de temps, où lors de la présence d’un certain message dans les logs, ou lorsque la moyenne d’une valeur numérique dépasse un certain seuil. Il existe deux types d’alertes, les alertes email, et le http callbacks qui permettent donc d’interagir avec toute api exposée en http (d’où slack).
En dernier lieu – on en aura peut-être moins souvent l’usage – les streams permettent de rediriger du contenu via GELF ou stdout. De même que pour les dashboards, je vous laisse le soin de visiter la doc associée aux streams pour en savoir plus.
Conclusion
Graylog est un système global et, s’il nécessite un minimum de configuration, il saura ensuite se montrer d’une puissance redoutable, tant dans la prévention grâce à l’alerting, que dans la recherche détaillée après avarie ou simplement pour diagnostiquer un problème. Puisqu’il utilise ElasticSearch comme moteur de stockage et d’indexation, la recherche précise parmi des TB de logs ne pose aucun problème.
Avez-vous pu installer le tout facilement ? La prise en main a-t-elle été intuitive ou est-ce bataillez-vous avec l’interface ? N’hésitez pas à faire part de vos commentaires.
Commentaires
fredix dit –
Pour la transmission des logs applicatifs et système je conseille l'excellent nxlog http://nxlog.co Il gère le format GELF, fonctionne sur Linux et Windows en service.
Buzut dit –
Merci pour ce petit soft ! J'ai regardé rapidement, il supporte le GELF en sortie d'après ce que je comprends, il peut lire le syslog, mais est-ce qu'il peut être paramétré pour lire dans d'autres fichiers de logs (Nginx, Apache etc) ?
Je me souviens en avoir essayé plusieurs (j'ai fait et écrit tout ça il y a plusieurs mois déjà) et soit c'était très compliqué (ou impossible) de récupérer les logs depuis plusieurs sources, soit il fallait tout envoyer dans le syslog, soit j'ai pas été assez bon et j'ai pas réussi à configurer la chose…
Enfin, je voulais impérativement que la communication se fasse en TCP parce que l'UDP ne prend pas en charge le TLS et que n'ayant pas un réseau privé dédié entre tous mes serveurs, passer les logs en clair sur l'Internet n'était pas une option !
NiKaro dit –
En terme d'espace de stokage, tu préconiserais quelle taille pour disons une vingtaine de serveurs simples (DHCP, DNS, LDAP, proxy, pare-feu, etc.) ?
Buzut dit –
C'est difficile à dire. Cela dépend vraiment de ce que tu veux collecter, s'il s'agit juste du syslog ça ne fait pas beaucoup de données, en revanche, j'ai un client chez qui l'applicatif génère énormément de logs (plusieurs centaines de MB/jour), forcement, tu comprends que ça impacte le choix du stockage.
La deuxième facteur concerne la rétention que tu veux. J'estime qu'en terme de logs, s'il ne s'agit pas de données métiers, après quelques semaines ces derniers ne sont plus très intéressants (dans le cadre de prévention de panne et d'investigation après panne), ce qui permet de libérer de l'espace assez rapidement.
Cela dit, pour une dizaine de serveurs, avec le syslog pour tous, les error logs de apache + nginx sur 3 d'entre eux, MySQL sur 2 et de l'applicatif qui n'envoie que quelques centaines de KB/jour, je n'ai qu'un SSD de 128GB et ça suffit amplement !
bobricard dit –
Donc en gros c'est une usine à gaz avec du java dedans...bye...et une fois que vous avez vos supers graphiques, vous faîtes quoi ?
Buzut dit –
Dois-je répondre où c'est juste un troll ? Je pense qu'au delà des graphiques, les dashboad et les streams présentent un réel intérêt de diagnostique. Au delà de ça, la fonction de recherche est puissante et bien plus pratique qu'un
cat /var/log/syslog | grep monerreurfredix dit –
Tu peux utiliser plusieurs input file et envoyer en TCP :
Module im_file File "/var/log/syslog" SavePos TRUE
Module im_file File "/var/log/apache2/error.log" SavePos TRUE
Module om_tcp Host srv-graylog Port 12205 OutputType GELF_TCP Exec $ShortMessage = $raw_event;
# Path in1 => fileout1 Path syslog,apache-error.log => out
Buzut dit –
Je vais essayer dès que j'ai un moment alors. Merci de tous ces renseignements !
David Pilato dit –
Pour info, on dit maintenant "Elastic Stack" ou la Suite Elastic car elle apporte aussi Beats qui fait des merveilles avec Elasticsearch 5.0 et son ingest pipeline.
En gros, ta stack est largement simplifiée par:
Sur ta machine à monitorer, un agent filebeat qui stream les logs vers elasticsearch Sur elasticsearch, un pipeline comprenant du Grok par exemple. + Kibana pour la visualisation (Timelion est dispo par défaut maintenant)
Et c'est tout...
L'idée est de te permettre de faire un tail -f de tes logs et de les voir directement sans trop d'effort.
Buzut dit –
Je rejoins @fredix. J'ai tenté Kibana à un moment, je trouve que l'interface est beaucoup moins intuitive (peu être plus puissante car plus souple, mais c'est pas intuitif de prime abord). Comme je le dis dans l'article, Graylog est vraiment fait pour ça et ça se voit !
En ce qui concerne la stack elastic, oui ils viennent en effet de nommer leur stack, mais ce qui ne veut pas dire qu'on ne peut plus parler d'elasticsearch lorsqu'il est utilisé indépendamment du reste de la stack. Un produit ne constitue pas une stack à lui seul. Sur leur home je lis bien d'ailleurs "Elasticsearch as a Service" ;)
David Pilato dit –
Je faisais référence à ELK. Nous n'utilisons plus ce terme.
Buzut dit –
Ahhhhhh, my bad on s'est mal compris ! Je vais corriger ça alors :)
sebclick dit –
Je rejoins également @fredix : Graylog a plusieurs avantages vis à vis de la suite Elastic : - Graylog gère les alertes - Graylog gère la partie authentification - Graylog gère l'épuration des logs (en fonction d'un volume ou d'un délai) - Et enfin, Graylog permet de configurer tout ça depuis une seule IHM sans avoir besoin de changer une configuration dans un fichier logstash (et c'est encore plus vrai dans Graylog 2.2 qui arrive).
fredix dit –
Perso je trouve largement plus simple la stack Graylog, qui permet de plus de gérer l'authentification des utilisateurs ce qu'il n'y a pas dans kibana.. Et l'agent open source nxlog est largement au dessus que tous les autres agents en java pourri.
fredix dit –
et graylog gère les alertes emails ce que ne fait pas la stack elasticsearch...
Marion dit –
Super outil qui va me faire gagner énormément de temps ! Merci
Marco77 dit –
Merci Quentin pour cet article J'en suis au tout début du montage d'une archi serveur de logs et j'ai opté pour Graylog pour sa supposée simplicité par rapport à la pile ELK. J'espère faire en sorte que les collègues sauront gérer tout seuls :)
VM Debian 8 avec mongodb et nginx dans les dépôts standard, OpenJDK 8 depuis jessie-backports (je crois), elasticsearch et graylog depuis les dépôts tiers après ajout des signatures GPG. Il faut que j'étudie comment chiffrer le disque avec dm-verity et je travaille encore avec un certificat TLS bidon.
Quelques observations donc (si je me gourre n'hésitez pas à me corriger):
-1. la différence notable avec ELK : c'est graylog-server qui alimente elasticsearch et pas les collecteurs source (logstash)
0. pour l'install, il me semble qu'il y a même des appliances ova prêtes à l'usage, mais bon on est là pour apprendre hein
1. pourquoi mongodb dans la dernière version? Je crois comprendre que c'est une base de métadonnées avec peu d'activité
2. graylog est sorti en 2.1, autant partir sur celle-ci
3. Je pense partir sur graylog-sidecar pour la gestion des configs filebeats (ruby) pour le parsing des traces techniques (syslog, auth, accesslogs apache/nginx). Plus tard si ça donne satisfaction : fluentd pour le buffering des traces métier et winlogbeat pour les windows Beats m'intéresse car il dit mémoriser les lignes déjà analysées, je sais pas si ton outil gère cela.
La fonction archivage m'intéresse également mais c'est l'option entreprise. Enfin c'est pas la priorité pour le moment.
Buzut dit –
Merci Marco pour ton retour !
-1. Oui c'est bien ça. Tout passe d'abord par le serveur, ce qui permet notamment de faire des traitements à priori (voir les flux).
0. L'install est dispo dans beaucoup de formes différentes, il y en a pour tous les goûts, du build des sources à l'OVA en passant par les outils d'automatisations les plus courants, Docker, tarballs et dépôts DEB et RPM, bref, on a l'embarras du choix pour le coup ! J'ai fait ma sauce avec un mix de Ansible et leur dépôt
.deb(c'est assez souple pour conserver une version à jour).1. En ce qui concerne Mongo, d'après ce que j'ai compris, c'est vraiment pour stocker les préférences, les mots de passe, les utilisateurs, les flux et dashboards, tout ce qui est config quoi. Tout le reste va dans ES. Si ton ES est down (ou pas encore up), tu peux quand même te connecter dans Graylog et diagnostiquer un minimum et/où attendre que Graylog se connecte à ES.
2. Autant partir sur la dernière version en date au moment de l'install.
3. Pour Graylog-sidecar je ne l'ai pas vraiment testé. Sur la version 1 il y avait un simple collector qui faisait le boulot, là ça m'a tout de suite semblé plus lourd et plus compliqué donc je n'ai pas cherché plus loin. Par ailleurs, il faut garder à l'esprit que le sidecar fait installer Java sur tous les clients, je préférais utiliser un outil plus light. fluentd et winlogbeat je n'ai jamais eu l'occasion de les tester donc je ne peux pas trop me prononcer dessus, quoique fluentd jouit d'une très bonne réputation.
Quand tu dis qu'il mémorise les lignes déjà analysées, j'imagine que tu parles de ça: <blockquote> In any environment, application downtime is always lurking on the edges. Filebeat reads and forwards log lines and — if interrupted — remembers the location of where it left off when everything is back online. </blockquote>
Mon outil est très très simple (190 lignes tout mouillé), il fait un
tail -fsur les fichiers de logs et forward tout sur le socket TCP ou via HTTP en direction de Graylog. Il n'a pas de mémoire à proprement parler et il ne gère quesysloget leerror.logde Nginx et Apache2. Mais c'est de l'open source et il ne demande qu'à être amélioré :)Cela dit, dès que j'ai un peu de temps, j'essayerais bien nxlog que m'a indiqué Fredix en commentaire.
Pour les traces métier, je trouve qu'il est plus souple de directement l'intégrer dans la solution métier (dans la mesure du possible) puisque tu gères la chose plus finement. Tu peux par exemple envoyer des traces détaillées (et même des stacktraces), le tout avec des champs personnalisés</a> directement en JSON bien propre sans devoir faire moults efforts de parsing. Le tout conjugué avec <a href="http://docs.graylog.org/en/2.1/pages/extractors.html" rel="nofollow">un extracteur dans Graylog, c'est extrêmement puissant !
J'avais vu la fonction archivage lorsqu'elle est sortie, pas d'expérience là dessus non plus. Tout dépend de la masse de logs que tu as, du temps que tu veux les garder etc. Sur un serveur avec un espace confortable, si tu n'amasses pas de dizaines de GB par jour, tu peux conserver quelques mois dans Graylog. Si ensuite tu estimes que tu veux conserver un an de données ou plus, l'archivage peut répondre à ce besoin.
Il y a aussi la solution de conserver les fichiers de logs eux-même, tu peux automatiquement les centraliser depuis les clients vers un serveur central par exemple. Juste après que tes logs aient été rotated un petit scp du log.1 => date-client.log.gzip et voilà. Faut voir comment tu as besoin de les exploiter aussi… bref, tout dépend du cas d'usage !
Marco77 dit –
Merci pour ces précisions Quentin.
sidecar joue le rôle d'agent puppet/chef si tu veux. il va chercher les configs sur graylog par api (en fonction des tags) et les applique en générant des fichiers de config locaux selon qu'on utilise beats ou nxlog. Il est écrit en Go tout comme beats, je suppose qu'il a une empreinte réduite (hum pas de dépendance java je crois).
pour mes besoins d'archivage, je pensais plutôt à des exigences légales avec service d'horodatage certifié/qualifié par un tiers de confiance (TSA ou TSP/QTSP). J'ai pas encore évalué graylog en ce sens, je sais même pas s'il est fait pour ça en réalité.
Buzut dit –
J'ai un peu trop survolé la question sidecar je crois… Oui Go est assez light donc ça ne m'inquiète pas trop. Légalement, en ce qui concerne seulement l'obligation de rétention, aucun problème et peu importe le format. En revanche, Graylog ne peut pas, à ma connaissance, certifier l'horodatage (peut-être peux tu regarder du côté des plugins…)
Rejoignez la discussion !