Chapitre 7 sur 13
Git workflow : organiser son travail
La courbe d’apprentissage de Git peut être rude. En effet, pour un usage efficace de l’outil, il faut passer maître dans l’organisation du dépôt.
Dans le chapitre précédent, nous avons vu comment rédiger des messages de commit expressifs et concis. Nous allons maintenant aborder une dimension primordiale dans tout répo de taille : la gestion des branches.
Doit-on avoir une politique à cet effet ? Y-a-t-il un modèle de référence à suivre ? Doit-on systématiquement pusher les branches ? Peut-on altérer l’historique ? Autant de questions auxquelles il convient d’apporter une réponse pour une collaboration efficace.
Gestion de l’historique
Git ne serait rien sans son historique, c’est tout l’intérêt de l’outil : pouvoir naviguer à sa guise entre différentes versions du projet, revenir en arrière, annuler des modifications etc.
Le git log, commande centrale dans l’usage de Git, permet justement d’afficher l’historique. Pour que ce dernier soit exploitable, il faut qu’il soit lisible.
Lisible signifie que les messages de commit reflètent les changements effectués – c’est ce que nous avons vu dans le chapitre précédent – mais aussi que l’historique soit le plus linéaire possible. Sans cela, on a tendance à être perdu et l’intérêt de l’historique diminue.
C’est pour cela qu’il faut prendre soin de son historique. Et malgré l’utilisation de messages de commit adéquats, la nature même du développement fait que l’on aboutit à des commit de bugfix, que l’on oublie des choses, lesquelles sont commités dans un second temps etc.
Par ailleurs, les commits atomiques font sens pendant le développement d’une fonctionalité, mais une fois celle-ci terminée et testée, on se retrouve avec de nombreux commits sans réelle valeure ajoutée :
- 🌟 (user) add test
- 🌟 (user) add model and test datas
- 🌟 (user) add ability to reset password
Si tous ces commits font partie d’une même fonctionalité en cours de développement – par exemple l’ajout de la récupération de mot de passe par email – alors une fois cette fonctionalité terminée, autant réunir tous les commits en un seul résumant l’ensemble : “🌟 (user) add reset password by email”.
Nous conservons ainsi un commit atomique, tout en gagnant en clareté. Lorsque vous naviguerez l’historique quelques semaines ou mois plus tard, ce niveau de détail est idéal.
Le rebase est évidemment l’outil indiqué. Grâce à lui, on peut réordonner les commits, les modifier, changer les messages de commit, rassembler plusieurs commits en un seul etc. Cette commande, très puissante, nécessite néanmoins quelques précautions et considérations.
Réécrire l’historique
Le rebase, c’est extraordinaire et il faut en faire usage… avec modération. Le point clivant concerne l’historique, qui est, comme nous l’avons évoqué, un élément central de Git. Cependant, tout le monde s’accorde sur un point :
Les gens peuvent (et devraient probablement) utiliser rebase sur leur historique privé (leur propre travail). Il s’agit d’un nettoyage de l’historique.
Ainsi, le rebase a une utilité incontestée. Là où naissent les divergences, c’est sur l’objet son usage :
- pour intégrer les changements d’une branche dans une autre,
- la modification de l’historique non privé.
Merge vs rebase
Deux écoles s’affrontent, l’école du rebase et l’école du merge. C’est une de ces fameuses guerres éternelles, au même rang que tabs vs space, Mac ou PC et bien d’autres dans le monde de l’informatique.
Personnellement, je préfère conserver un historique propre et linéaire. Ainsi, j’ai tendance à utiliser le merge pour intégrer les changements d’une branche dans une autre.
Cette façon de faire permet d’avoir un historique linéaire comme si tout les changements avaient été effectués sur la branche principale (master en général). Le fait d’utiliser plusieurs branches est une organisation propre au développement, pas aux fonctionnalités développées.
Dès lors, ces détails n’apportent que peu de valeur à l’historique et nuisent à sa lisibilité. Lorsque l’on utilise le merge, l’historique est criblé de messages ressemblant à ceci :
Merge branch 'feature-branch' of git://gitdomain.com/git-project/
Comportement par défaut du merge
Par défaut, le git merge n’ajoute pas toujours de commit de merge. Lorsque la branche à fusionner est un enfant direct de la branche récipiendaire, alors git utilise le mode fast forward, les commits de la branche à fusionner sont ajoutés “au dessus” des commits de la branche le recevant.
Certains pro-merge préconisent au contraire de toujours utiliser un message de fusion afin de bien matérialiser le fait qu’il y a eu un merge, cela se fait en passant l’argument --no-ff lors du merge. J’estime que cela n’aboutit qu’à l’ajout de bruit, mais cela se discute et un usage nuancé se défend.
Cela dit, si vous devez travailler sur un repo collaboratif ou le merge est de rigueur, sachez que Git permet de vous épargner la rétine avec le git log --no-merge.
Par ailleurs, si vous souhaitez vous prémunir de merge commits accidentels, la commande merge accepte --ff-only, elle refusera ainsi d’effectuer la fusion si elle n’est pas possible via la technique du fast forward. Vous pouvez le mettre en alias au niveau de votre configuration Git si vous souhaitez l’appliquer de manière globale.
git config --global merge.ff onlyEnfin, il arrive (souvent) que le fast forward ne soit pas possible. C’est le cas dès que la branche à fusionner n’est plus descendante directe de la branche récipiendaire. Dans ce cas, le rebase est la seule solution si vous souhaitez éviter le commit de fusion.
A---B---C feature
|
A---D---E---F---G masterLe rebase “redéfinit la base” de la branche. Dans l’exemple précédent, voici le résultat d’un rebase en fonction du contexte.
# git rebase master depuis feature
A---D---E---F---G---B---C feature
# git rebase feature depuis master
A---B---C---D---E---F---G masterAussi, comme nous ne devons pas modifier l’historique de ce qui a déjà été publié (sous peine de semer le chaos), lorsque l’on est dans un cas où master contient des commits présents sur la remote, alors on rebase master sur feature, avant d’intégrer feature à master (via un merge, lequel sera fast forward friendly).
Rebase automatique lors du pull
Le pire de tous les messages de fusion est bien celui où l’on récupère des modifications depuis une branche distante pour l’inclure sur la même branche locale.
Si le fast forward n’est pas possible, nous obtiendrons un magnifique message disant en somme que l’on a fusionné la branche distante dans la branche locale. En terme de pollution visuelle, il est difficile de faire pire. Pour parer à ce fléau, vous pouvez spécifier à Git dans la configuration globale le comportement qu’il convient de toujours adopter.
git config --global pull.rebase trueBien utiliser les branches
Maintenant que l’on a abordé les deux principales stratégies de fusion d’une branche dans une autre, voyons tout de même comment utiliser les branches à bon escient.
Là encore, plusieurs écoles existent. Une des première préconisation de flux de travail avec les branches, et de fait, la plus connue est Git flow. On trouve également parmi les organisations populaires GitHub flow et Gitlab flow. La lecture des différents articles s’avère intéressante si vous en avez le temps :
GitHub et Gitlab flow sont des variantes d’un modèle appelé trunk based ou cactus. Dans ce modèle, le développement est effectué sur la branche master par défaut. Il y a une règle à respecter : les commits publiés ne doivent pas casser la build.
Git flow consiste en une organisation et une hiérarchie de branches persistantes bien définie. Ce modèle précise la manière dont le code doit circuler d’une branche à l’autre et la manière dont les changements sont intégrés à la base de code. Bien qu’il ait beaucoup d’adeptes, ce modèle présente trois problèmes majeurs :
- son organisation est trop complexe pour des projets simples,
- il devient compliquée à gérer dès lors qu’il y a de nombreux contributeurs travaillant en parallèle,
- il n’est pas (ou difficilement) compatible avec l’intégration continue (CI).
À l’inverse, le modèle cactus offre une organisation plus simple et efficace. Ce système est disponible en plusieurs variantes, lesquelles sont adaptées au nombre de développeurs et au type de projet (obligation de maintenir plusieurs versions actives en même temps…). Utilisée par des sociétés travaillants sur de gros projets (Google et Facebook pour ne mentionner qu’eux) son efficacité n’edt plus à prouver.
Comment s’organiser concrètement ?
Vous l’aurez deviné, nous allons ici décrire une organisation respectant l’esprit du trunk based develoment. Ainsi, master étant la branche par défaut, il semble logique de l’utiliser par défaut pour le développement (but premier de Git). Il n’y a nul besoin de documenter quelle devrait être la branche de développement, quelle est la branche qui contient les dernières modifications etc, tout est sur la master.
Bien entendu, cette règle n’est valable que pour le dépôt central et il est recommandé – dès lors que l’on développe quelque chose de raisonablement complexe – d’utiliser les branches dans notre processus de développement local. L’utilisation de branches nous permet de conserver une master propre pendant notre développement et, au besoin, de pouvoir créer un hotfix ou une autre branche propre à partir de master.
Ce qui est interdit, c’est d’avoir des branches distantes dont le développement est parallèle à master. En effet, si le développement est de courte durée (quelques heures à quelques jours), alors son utilité est nulle car le commits peuvent tout aussi bien directement être intégrés à master.
En revanche, s’il s’agit d’une branche ayant une durée de vie plus longue, on aboutit inéluctablement a creuser un écart entre la base de code de la master et la base de code de la feature branch. On augmente donc statistiquement les problèmes lors de l’intégration de cette dernière à la master : conflit de fusion, features divergentes, code s’appuyant sur du code que vous avez modifié ou l’inverse…
Exemple de flux de travail
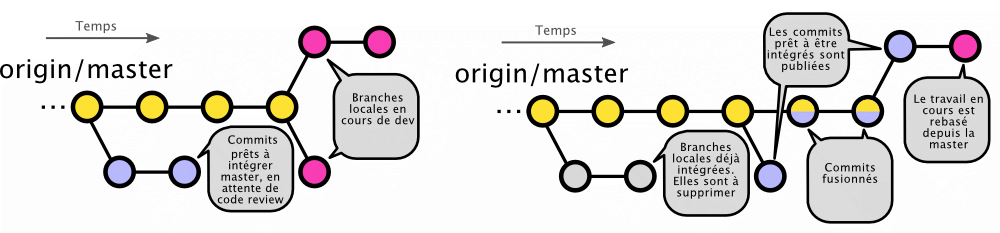
Sur le schéma de gauche, nous avons trois branches locales en cours de développement (couleur rose) et deux branches en revue de code, prêtes à être intégrées à master (couleur bleue).
Le schéma de droite représente le même projet un peu plus tard. Les deux branches précédemment en code review ont été intégrées à master (couleur jaune/bleue), nous avons soumis deux nouveaux commits pour code review (couleur bleu) et sommes en train de travailler sur une nouvelle feature (couleur rose).
Nous constatons qu’à la fois nos branches en code review et en cours de développement ont été rebasées sur la master. C’est à dire qu’elles intègrent toutes un état récent de master afin de limiter au maximum les divergences et faciliter l’intégration finale dans master.
J’ai récupéré ce schéma depuis un article expliquant pourquoi le Git-flow est mauvais [en].
Méthodes d’intégration à master
Nous avons jusqu’alors laissé entendre que les branches distantes étaient le mal absolu… Cela nécessite tout de même quelques précisions. Comme déjà expliqué, ce qui est déconseillé est la publication de branches distantes en tant que branche de travail.
Néanmoins, le partage de feature branch un élément central de collaboration entre développeurs. Partager votre branche lorsque votre fonctionnalité est terminée permet à un pair d’effectue une revue de code.
Le Gitlab flow dévie en ce point légèrement du trunk based dans la mesure où il est possible de partager une branche alors qu’elle n’est pas tout à fait prête à intégrer la master. Dans ce cas, le PR sera préfixée par un “WiP” afin de bien signifier qu’il s’agit d’un chantier en cours. Cette méthode peut être une bonne solution afin d’obtenir des retours et conseils sur la manière d’implémenter une fonctionnalité.
Ainsi, votre code est relu par une paire d’yeux supplémentaire et les bugs potentiels sont réduits. Toutes les plateformes de collaboration offrent des outils de pull request ou merge request (PR pour les intimes). De cette façon, la discussion intégrée à la PR permet au reviewer de facilement faire ses remarques.
Si besoin, on modifie notre PR en conséquence et lorsque la fonctionnalité est prête à intégrer la branche master, elle est intégrée à cette dernière – soit directement par l’auteur de la PR, soit par le développeur en ayant les droits et la responsabilité.
Dans le modèle trunk based, il existe ainsi trois méthodes d’intégration de code :
- Publication directe sur master. Cela fonctionne pour les petites équipes ou lorsque la fonctionnalité à intégrer est vraiment simple et ne nécessite pas de revue de code.
- La publication d’une feature branch pour revue de code tel que décrit précédemment. Dès lors que le développeur en charge de la revue donne son feu vert, le code peut être intégré. Ce modèle scale bien, même pour de très grosses équipes.
- Un modèle à base de patch qui utilise des outils tiers tels que Gerrit. C’est un process plus lourd et il concerne des base de code sur lesquelles collaborent plusieurs milliers de développeurs. C’est une approche notamment adoptée par Google.
Dans le cas de la publication d’une feature branch, après son intégration à master, elle doit être supprimée. Son existence même ne sert qu’à partager le code en vue de l’intégration à la master. Dès son intégration, elle n’a plus de raison d’exister.
Enfin, l’intégration se fait toujours pas un rebase. Dans les variantes GitHub et Gitlab flow, le merge avec message de commit (no-ff) est souvent utilisé, ce qui n’est pas le cas du modèle cactus, à vous de voir si l’aspect “sapin de noël” vous plaît.
Passage en production
Chaque projet est différent, et s’il est vrai que tous les commits ajouté à master doivent garantir le build, cela ne veut pas forcement dire qu’à tout moment, on peut pousser master en production.
À nouveaux, ici, plusieurs stratégies existent. Dans le meilleur des mondes, vous travaillez sur un logiciel en SaaS, vous avez en place un pipeline de CI/CD et tout est automatisé. La mise en production se fait automatiquement à partir de la master et vous n’avez rien de plus à faire.
Dans cette première éventualité, il faut être bien vigilant à utiliser des drapeaux (feature flag) pour activer et désactiver certaines fonctionnalités qui sont en cours de développement. En effet, on ne voudrait pas qu’une feature incomplète soit répercuté sur la prod.
La seconde option est une variante de la première. La branche master est dédiée au développement, les releases sont simplement des points particuliers sur cette dernière branche marqués par des tags. Chaque tag représente donc une version de la production.
Enfin, la dernier cas concerne les équipes qui doivent maintenir plusieurs versions simultanément. Dans ce cas, on freeze une version du logiciel sur une branche de release. Celle-ci n’est alors plus développée. Cependant, en cas de bug découvert, celui-ci est corrigé sur la master et le correctif est appliqué sélectivement sur la ou les release branch via un cherry-pick.
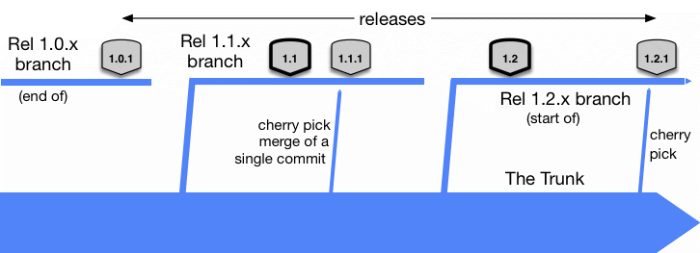
Cette méthode de hotfix est aussi applicable aux releases via tag. Dans le cas où on doit apporter un hotfix à la production mais qu’on ne peut pas à ce stade directement déployer depuis la master, on peut alors créer une branche depuis le release tag et de la même manière appliquer le bugfix via un cherry-pick. Cette branche temporaire servira alors comme base de déploiement du hotfix.
Conclusion
Quelle que soit la taille et le type de projet sur lequel vous travaillez, vous êtes maintenant armé des bons outils et méthodes pour mettre en place un flux de travail flexible et efficace. Si vous souhaitez une documentation dédiée au modèle cactus, un site lui est dédié : trunkbaseddevelopment.com.
J’espère que ce cours vous permettra d’augmenter votre productivité et d’améliorer la qualité et l’exploitabilité de votre versionning avec Git. N’hésitez pas à utiliser les commentaires pour me faire part de vos avis et suggestions.
Commentaires
Rejoignez la discussion !