Chapitre 6 sur 8
L'encodage du texte et Unicode
Maintenant que nous connaissons le besoin derrière Unicode et son histoire, penchons-nous sur les détails techniques. Nous avons dit que le consortium standardise plusieurs encodages, alors quels sont-ils et comment fonctionnent-ils ?
Ces encodages étant très populaires, leurs noms vous sont familiers, d’autant plus que nous les avons déjà mentionné dans les chapitres précédents. Il s’agit des encodages UTF-n. La différence entre ces encodages est la longueur minimale d’octets nécessaires à la représentation d’un caractère.
Nous avons dit qu’originellement, Unicode représentait tout sur deux octets. Comme la plupart des langues latines n’utilisent en proportion que très peu les signes non ASCII, cela constitue une perte d’espace inacceptable pour beaucoup.
En revanche, pour des langues utilisant des signes ne faisant pas partie de l’ASCII, ces encodages ont toute leur utilité. Il fallait donc trouver une solution qui convienne à tous. Ainsi, en Unicode, les codepoints et l’encodage sont deux choses bien distinctes.
La table Unicode
Unicode est avant tout une table géante attribuant un numéro unique à chaque caractère, son point de code ou codepoint. La table Unicode permet d’attribuer 1 114 112 (216 x 17) points de code. Seulement 25% de ces points de code sont aujourd’hui attribués.
Les plans Unicode
Cette table est divisés en 17 plans (de 0 à 16) de deux octets chacun, soit 65 536 points de code par plan (65 536 x 17 = 1 114 112). Ces plans permettent de désigner facilement des groupes de caractères. Le premier plan, appelé Basic Multinlingual Plane (BMP), ou Plan Multinlingue de Base, regroupe les 65k caractères les plus courants. Les plans 1 à 16 sont appelés plans supplémentaires.
Par ailleurs, parler “d’encodage Unicode” n’a pas vraiment de sens. Par exemple en Unicode, “bonjour” se traduit par :
U+0062 U+006F U+006E U+006A U+006F U+0075 U+0072Il s’agit des points de code Unicode qui correspondent aux différentes lettres du mot. Comme vous pouvez le constater, les points de code sont exprimés en hexadécimal. Bien que d’ordinaire exprimés de cette manière, on peut également les représenter via leur équivalent décimal.
Le HTML permet d’ailleurs les deux notations.
# En hexadécimal (notez le x)
bonjour
# En décimal
bonjourVous pouvez tester cela avec l’encodeur HTML. Les différents signes et points de codes afférents sont tous listés sur le site Unicode Table.
Ces points de codes, qu’ils soient exprimés en hexa, décimal ou binaire, ne sont pas suffisant pour encoder un signe en sa représentation binaire.
Les encodages
Jusque là, nous n’avons qu’un moyen de faire correspondre un signe et son numéro dans la table Unicode. Cela ne nous dit en rien comment stocker ces éléments en mémoire. C’est là qu’interviennent les encodages.
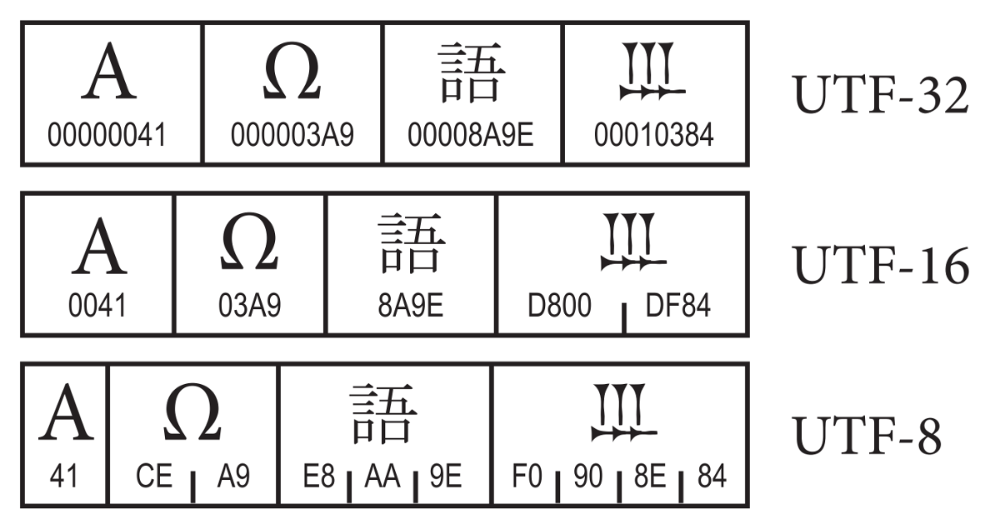
Encodages à taille fixe
Ces encodages ont comme avantage une facilité de parsing et de recherche, ainsi que de troncage car quel que soit le caractère, sa taille est connue par avance. Le mapping binaire vers point de code est facilité. Cela se fait cependant au détriment de l’espace utilisé (RAM, disque, bande passante…).
UCS-2
Au début d’Unicode, comme nous l’avons vu, tout était stocké sur deux octets. Cet encodage, bien que déprécié, existe toujours, il s’appelle UCS-2 et est de longueur fixe. Il ne permet pas de représenter l’ensemble des caractères Unicode, mais seulement les 65k premiers, qui sont les plus courants (pas d’emojis cependant).
Notre “bonjour” peut donc être stocké en mémoire de la manière suivante (représentation en hexa).
0062 006F 006E 006A 006F 0075 0072Mais comme nous l’avons mentionné, sur une machine en little-endian, les octets seront inversés.
6200 6F00 6E00 6A00 6F00 7500 7200L’exemple illustre bien l’usage inutile d’espace, tout étant stockés sur deux octets, si l’on utilise que des caractères de l’ASCII – et même pour certains caractères latin comme les lettres accentués, un octet est gâché par caractère.
Maintenant, si l’on regarde la représentation du signe “€”, les deux octets sont bien utilisés`
20ACEn revanche, tous les caractères qui sont en dehors de la BMP, soit les 65536 caractères les plus courants, ne sont pas représentables en UCS-2. C’est pourquoi cet encodage ne fait aujourd’hui pas parti de la norme Unicode.
UTF-32
Cet encodage est le plus long qui soit à taille fixe du standard Unicode et c’est aussi le seul de taille fixe qui ne soit pas déprécié. Il permet de représenter l’intégralité des caractères Unicode sur 32 bits, soit quatre octets. On reprend notre exemple précédent et on l’encode en UTF-32BE.
00000062 0000006F 0000006E 0000006A 0000006F 00000075 00000072Ici, l’espace perdu est tout juste ahurissant. Même les emojis ne prennent pas autant de place, voici une pizza 🍕 en UTF-32BE.
00 01 F3 55L’avantage de cet encoding est d’avoir l’ensemble des caractères de même taille. À cet effet, il n’est presque jamais utilisé pour stocker du texte mais sert plutôt dans des API internes. Par exemple Python 3 l’utilise pour représenter les variables de texte.
Encodages à taille variable
À ce jour, deux encodages à taille variables sont dans la norme Unicode, l’UTF-8 et l’UTF-16. Leur maximum est de quatre octets chacun mais la taille minimum d’un signe est respectivement de un et deux octets.
UTF-8
C’est incontestablement l’encodage le plus utilisé aujourd’hui. Tant pour le stockage que le transfert d’informations. Sa taille minimale est de huit bits et il peut monter jusqu’à quatre octets pour certains signes.
L’UTF-8 a également la particularité d’être totalement rétro-compatible avec l’ASCII. Tout caractère ASCII valide est un caractère UTF-8 valide. Par ailleurs, comme il est composé de mots d’un seul octet, il n’est pas sensible au boutisme.
Comme il s’agit d’un encodage à taille variable, certains signes sont composés de plusieurs mots. Afin de pouvoir identifier le nombre de mots constitutifs d’un caractère, l’UTF-8 place cette information dans le premier octet.
- tout point de code ayant une valeur inférieure à 128 est codé sur un octet avec le bit de poids le plus fort à nul (comme en ASCII),
- les autres points de code sont codés sur plusieurs octets. Le premier octet a ses bits de poids les plus forts à
1avec autant de1que de mots. Nous avons donc un minimum de deux et jusqu’à quatre1, suivi d’un0, tandis que les bits restants permettent de coder l’information. Les mots suivants commencent forcément par10.
| Nombre de mots | Représentation binaire |
|---|---|
| 1 | 0xxxxxxx |
| 2 | 110xxxxx 10xxxxxx |
| 3 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Voyons cela avec quelques exemples concrets. La lettre “e” est codée comme en ASCII. Soit 65hex ou 101dec, cela donne 01100101bin. Jusque là, c’est très simple.
Prenons maintenant en exemple l’émoji 😎. Si on regarde l’Unicode table, on réalise que son code est U+1F60E, soit 128526dec. Cependant, si l’on regarde le détail de l’encoding, aussi bien la représentation en hexa qu’en décimale ne correspond pas.
# en hexa
F0 9F 98 8E
# en décimal
4036991118Pour retrouver notre valeur, il faut bien comprendre l’encodage expliqué ci-dessus. Voyons cela en détail.
# voici la valeur en binaire
11110000 10011111 10011000 10001110
# le premier octet indique que le caractère est codé sur 4 octets
# (quatre 1 suivi d'un 0)
11110000
# on enlève donc cette information du premier octet,
# comme il ne reste que des zéros, on peut ignorer ce premier octet
# les trois octets suivants doivent obligatoirement commencer par 10
# cela signifie qu'ils sont bien des octets de "continuation"
# on peut donc également enlever ces valeurs.
# Nous obtenons donc le nombre binaire suivant
011111011000001110
# vous pouvez le convertir et admirer le résultat !UTF-16
L’UTF-16 est de longueur variable avec des mots de 16 bits. Ainsi, en UTF-16, un signe fait soit deux soit quatre octets. Contrairement à l’UTF-8, l’UTF-16 n’est pas compatible avec l’ASCII – et bien entendu pas compatible non plus avec l’UTF-8.
Cependant, UTF-16 est totalement rétro-compatible avec l’UCS-2, le premier encodage Unicode qui était de taille fixe sur deux octets. Ainsi, tout signe valide en UCS-2 l’est aussi en UTF-16 et tout ce qui est encodable en UTF-16 sur un mot est donc un caractère UCS-2 valide.
Contrairement à l’UCS-2, qui est limité à la BMP, l’UTF-16 permet d’encoder l’ensemble des caractère de la table Unicode. Les 65536 premiers s’encodent comme en UCS-2, avec leur valeur sur deux octets, les 1 048 576 caractères restant nécessitent l’usage d’un second mot.
Dès qu’il faut encoder un caractère qui ne fait pas partie de la BMP, UTF-16 utilise ce que l’on appelle des surrogate pairs ou demi-zones d’indirection. Ces points de code font partie de la BMP mais sont des non-caractères, réservés à l’usage de l’UTF-16 pour le codage de caractères ne faisant pas partie de la BMP.
Ainsi, parmi les 65536 charactères de la BMP, 1024 sont réservés pour la demi-zone haute d’interdiction (high surrogates) et 1024 autres sont réservés pour la demi-zone basse d’interdiction (low surrogates). 1024 x 1024 = 1 048 576, le compte est bon !
En UTF-16, tout caractère composé de deux mots de seize bits est une association d’un high surrogate pour le premirer mot et d’un low surrogate pour le second. À partir de ces deux valeurs, on peut calculer le caractère représenté.
Par ailleurs, comme les caractères utilisés sont des non-caractère, ils ont l’assurance de ne jamais pouvoir être utilisé pour représenter autre chose. Aussi, cette particularité fait que l’UTF-16 est, comme l’UTF-8, auto-synchronisé car il suffit de trouver un surrogate afin de savoir qu’il s’agit d’un demi-mot et s’il s’agit du début ou de la fin.
L’encodage se fait comme ceci :
- on soustrait 10000hex au point de code, ce qui laisse un nombre de 20 bits dans l’étendue 00hex à FFFFFhex ;
- les 10 bits de poids fort (un nombre entre 00hex et 3FFhex) sont additionnés à D800hex, et donnent la première unité de code dans la demi-zone haute (D800hex à DBFFhex) ;
- les 10 bits de poids faible (un nombre entre 00hex et 3FFhex) sont additionnés à DC00hex, et donnent la seconde unité de code dans la demi-zone basse (DC00hex à DFFFhex) ;
Autrement dit, pour récupérer la valeur du point de code depuis l’encodage en UTF-16, on réalise l’opération suivante 10000hex + (H − D800hex) × 400hex + (L − DC00hex) ou H et L font référence à High and Low surrogate pairs.
# D8 3D DE 0E est la représentation en UTF-16BE de 😎
# faisons nos calculs
10000 + (D83D - D800) * 400 + (DE0E - DC00)
= 10000 + 3D * 400 + 20e
= 10000 + f400 + 20e
= 1f60e = U+1F60E = 😎Support des langages de programmation
De nombreux langages ont utilisé la version 1.0 d’Unicode et ont donc établit qu’un caractère faisait deux octets. Lorsqu’il est apparu qu’il y aurait finalement bien plus de 65k caractères, ils ont naturellement opté pour UTF-16 afin d’offrir une compatibilité ascendante. C’est notamment le cas de Java et JavaScript dont le type String est représenté en interne en UTF-16.
Cependant, en JavaScript, certaines méthodes, telle que length, travaillent avec le nombre de mots UTF-16.
# Fonctionne en CLI si Node.js est installé
# ê s'encode sur un mot UTF-16
node -e "console.log('ê'.length)"
1
# 🤔 requiert l'usage de surrogate pair sur deux mots
node -e "console.log('🤔'.length)"
2Il est question de savoir ce qui doit être compté : point de code ? octet ? graphème ? En JavaScript, de nombreuses méthodes travaillent directement avec le nombre de mots UTF-16. Dès lors, aussitôt sorti de la BMP, le résultat peut être surprenant.
Cependant, l’itérateur de String fonctionne directement avec les points de code UTF-16. C’est donc la méthode à utiliser si l’on veut travailler non pas sur les mots UTF-16 mais directement sur des caractères.
// Ce code n'est pas pour la CLI
// utilisez plutôt jsfiddle (ou la REPL) si vous voulez tester
const yo = '💋🤪🙈🙌';
console.log(yo.length); // 8 (deux mots UTF-16)
// Ici on a des surrogate pairs
// cette méthode va accéder à la low surrogate de 💋
// qui n'est pas un caractère valide
console.log(yo[1]); // �
// mais le String iterator prend en compte les points de code UTF-16
console.log(Array.from(yo).length); // 4
console.log(Array.from(yo)[1]); // 🤪D’autres langages ne supportent pas Unicode, mais cela ne les empêche pas d’être compatibles. Ils ne sont tout simplement pas Unicode aware. C’est par exemple le cas de PHP. Dans ce langage, le type String équivaut à un octet. Ainsi, tout caractère codé sur plus d’un octet n’est pas reconnu comme tel par PHP.
# Fonctionne en CLI si php-cli est installé
php -r "var_dump(strlen('ê'));"
2
php -r "var_dump(strlen('🤔'));"
int(4)PHP compte le nombre d’octets, un point c’est tout. Cependant, il sera en mesure de transmettre les octets correspondants et ils pourront être interprétés de manière adéquate par la suite (dans le navigateur par exemple). En PHP, l’encodage courant utilisé est l’encodage du code source, lequel doit être compatible ASCII. Il est néanmoins possible de modifier ceci avec le flag Zend multibyte.
Même les langages non Unicode aware proposent pour la plupart des outils pour travailler avec Unicode. En PHP, ce sont les fonctions mbstring, en JavaScript certaines méthodes telles que codePointAt, fromCodePoint ou encore le flag u des regexp permettent le support d’Unicode.
Il n’y a pas de secret, il faut connaître son langage et utiliser les fonctions appropriées afin de travailler avec Unicode. Comme dirait JCVD, soyez aware!
Par ailleurs, si vous souhaitez creuser les différences de gestions entre les langages et voir des exemples de cas un peu sournois, je vous conseille de lire ce très intéressant artile : It’s Not Wrong that “🤦🏼♂️”.length == 7.
Les encodages dépréciés
Sans entrer dans le détail, mentionnons rapidement les encodages qui sont aujourd’hui déprécié mais que vous pourrez tout de même encore croiser dans la nature.
- L’UTF-1 est un encodage recommandé dans la première norme ISO. Il est un encodage de taille variable de 1 à 5 octets. Il ne comporte pas de mécanisme de synchronisation ce qui rend complexe la correction des erreurs et est lent à cause de son usage de multiplications/divisions par des nombres non puissances de 2.
- UTF-7 est un encodage de taille variable avec des mots de 7 bits. Il propose de représenter les caractères Unicode avec un flux ASCII. Il a été conçu pour permettre la transmission d’Unicode avec les systèmes SMTP n’étant pas 8-bit clean, c’est à dire ne supportant pas le texte encodé sur plus de 7 bits. Cet encodage échappe les séquences Unicode et les représente par leur valeur binaire encodée en base64.
Différentes représentations d’un caractère
Nous savons qu’Unicode est une table de caractère géante et que la norme définit plusieurs encodages afin de représenter ces caractères en binaire. Pour diverses raisons, notamment de compatibilité avec les anciennes tables, un même caractère peut être codé de différentes manières.
Caractères combinés
Saviez-vous que de nombreux caractères peuvent être représenté sous différentes formes ? Il s’agit notamment de tous les caractères qui peuvent être composés d’accents. Ainsi, nos é, è, ê, ë, à, ç etc, ici représentés comme caractères pré-composés – un unique point de code pour chacun – peuvent aussi être composés, représentés par deux points de code successifs.
Sous la forme composée, on trouve d’abord le caractère sans son accent, puis un second caractère représente l’accent seul, le signe diacritique, qui ont des points de code à part entière. Le graphème est ensuite rendu dans sa forme “normale”.
Par exemple, voici un “e” suivit d’un accent circonflexe : ê. Il n’est ici pas possible de voir la différence, pourtant, ce “ê” est bien formé de deux caractères, e suivi de ^, soit en Unicode :
# ê
U+00EA
# ê
U+0065 U+0302Cette possibilité permet aussi de former des caractères de certaines langues, composés de plusieurs accents, alors que ces derniers n’existent pas sous leur forme pré-composée (par exemple, “diakrī́nō”, distinguer en grec ancien, étymologie du mot diacritique).
Si vous copiez ces caractères dans l’outil HTML entities, vous verrez immédiatement apparaître les codes des différents caractères.
Caractères dupliqués, ligatures et glyphes composés
Certains caractères sont délibérément dupliqués pour des raisons de compatibilité. Ainsi, le caractère grec Mu “µ”, U+03BC, et le symbole micro “μ”, U+03B5 sont dupliqués pour des raisons historiques de compatibilité avec le Latin-1.
D’après Wikipedia :
Toutes les lettres grecques sont encodées dans la section grecque d’Unicode mais beaucoup sont encodées une seconde fois sous le nom du symbole technique qu’elles représentent.
Il faut aussi compter le fait qu’il y a des formes pré-composées de nombreuses ligatures communes et autres signes couramment utilisés :
- point de suspension “…”,
- les chiffres romains (Ⅶ…),
- et de nombreuses ligatures telles que “œ” évidemment ou encore “ff”.
Ces équivalences rendent difficile la comparaison et le tri des chaînes de caractères. C’est pourquoi le standard définit des règles d’équivalence et de tri.
Équivalence Unicode
Unicode fournit deux notions d’équivalence : canonique et de compatibilité, la première étant un sous-ensemble de la deuxième. Par exemple, le caractère n suivi du diacritique tilde ~ est canoniquement équivalent et donc compatible au simple caractère Unicode ñ, tandis que la ligature typographique ff est seulement compatible avec la séquence de deux caractères f.
Unicode définit deux critères d’équivalence – forme canonique (NF) et de compatibilité (NFK) – et leur associe les formes pré-composées et composées.
- NFC
- Normalization Form Canonical Composition normalise la chaîne selon sa forme canonique avec les signes pré-composés
- NFD
- Normalization Form Canonical Decomposition normalise la chaîne selon sa forme canonique avec les signes composés
- NFKC
- Normalization Form Compatibility Composition normalise la chaîne selon sa forme compatibilité avec les signes pré-composés
- NFKD
- Normalization Form Compatibility Decomposition normalise la chaîne selon sa forme compatibilité avec les signes composés
Petit exemple en JavaScript.
const a = 'ff';
const b = 'ff';
console.log(a.normalize('NFC') === b.normalize('NFC')); // false
console.log(a.normalize('NFKC') === b.normalize('NFKC')); // trueIci l’emploi de la forme pre-composée ou composée n’aura pas d’incidence. En revanche, dans le cas de normalisation avant stockage par exemple, il vaut mieux utiliser la forme non composée. En effet, tout caractère pré-composé peut être modifié en sa forme composée, la réciproque n’est pas vraie.
Par ailleurs, la forme de compatibilité est destructrice. Elle peut permettre d’améliorer la recherche – ‘f’ permettra en effet d’obtenir un match sur “ff” après normalisation NFK – mais le glyphe perd indéniablement de son sens, tout comme un nombre en indice ou en exposant.
Homoglyphes
Bien que visuellement identiques, “A”, “А” et “Α” sont trois caractères distincts. On dit qu’il s’agit d’homoglyphes. Nous avons dans cet exemple respectivement le “A” latin majuscule, le “A” cyrillique majuscule et le “Α” grec majuscule.
node -e "console.log('A' === 'А');"
falseOn voit immédiatement quels problèmes cela peut représenter… Inscription à un site web avec pseudo unique ? Si “Antoine” existe, alors je peux m’inscrire avec “Αntoine”.
Malheureusement, Unicode ne fait ici pas énormément pour nous venir en aide. Il existe une table des différents signes qui peuvent poser problème. Alternativement, un module existe pour Java et JavaScript, lequel permet de détecter la présence d’homoglyphes.
En résumé
Nous réalisons que dans près de 100% des cas, sauf si vous écrivez dans des langues utilisant des idéogrammes, l’encodage le plus adapté pour le stockage et l’échange d’information est l’UTF-8. Il permet d’encoder toutes la palettes des caractères Unicode en limitant l’espace utilisé.
Pour les applications, il est utile de normaliser le texte traité afin d’efficacement pouvoir trier et comparer des chaînes de caractères. En outre, on pourra également limiter l’usage des homoglyphes si les contraintes de sécurité l’exigent.
Commentaires
Rejoignez la discussion !