Chapitre 8 sur 8
Complexité algorithmique
Nous utilisons les algorithmes informatique pour résoudre des problèmes. À chaque problème correspond en général plusieurs solutions. Toutes n’ont cependant pas forcément la même efficacité.
Cette efficacité, c’est le temps que mettra l’algorithme à résoudre le problème pour un input de taille n. Ce temps d’exécution se mesure mathématiquement, on parle de complexité dans le temps ou time complexity.
Évaluer le temps d’exécution
Peu importe le temps d’exécution réel, lequel dépend du langage, de la machine, de l’OS etc. L’objectif est d’évaluer l’efficacité d’un algorithme indépendamment du langage et du système sur lequel il est exécuté.
Pour cela, nous raisonnons de manière abstraite en ne considérant que l’algorithme et la valeur d’entrée n. Nous notons la complexité algorithmique T(n), soit une fonction exprimant le temps d’exécution T, pour l’input de taille n. Selon le contexte, la taille de n peut se référer au nombre d’éléments d’un tableau, à la longueur d’une chaine de caractères, à la taille d’un buffer etc.
Prenons un exemple : trouver si une valeur x est dans un tableau a. Pour résoudre ce problème, l’algorithme le plus simple est de faire une boucle et pour chacune des valeurs de l’array, vérifier s’il s’agit de x.
function findNeedle(needle, haystack) {
for (let i = 0; i < haystack.length; i++) {
if (needle === haystack[i]) return true;
}
return false;
}
findNeedle(5, [1, 2, 3, 4, 5, 6, 7, 8, 9]); // 4Ainsi, pour évaluer le temps d’exécution d’un algorithme, on compte le nombre d’opérations effectuées pour arriver au résultat. Comme nous n’avons pas connaissance de l’input, on évalue le pire scénario.
Dans l’exemple ci-dessus, à chaque tour de boucle, deux comparaisons sont effectuées (i < haystack.length et needle === haystack[i]), nous avons une assignation (i++) ainsi qu’un return en fin de fonction où dès que le match est trouvé.
Dans le meilleur des cas, needle est le premier élément de l’array et il n’y a qu’un seul tour de boucle, soit un temps d’exécution T(n) = comparaison + comparaison + assignation + return. Cependant, dans le pire des cas, la valeur n’est pas présente dans l’array et T(n) = comparaison x (n + 1) + assignation x n + comparaison x n + return.
Dans la mesure de complexité, nous retenons en général la valeur pour le cas d’exécution le plus long. Ainsi, la complexité en temps traduit le temps maximum que l’algorithme peut mettre à s’exécuter.
Compter le temps
Nous avons dit compter les différentes opérations réalisées par l’algorithme. Cependant, nous ne prenons jamais en compte le temps d’exécution réel des opérations, et partons du présupposé qu’elles ont toutes la même durée. Dès lors, on peut regrouper les variables en utilisant seulement l’input et une constante.
T(n) = comparaison x (n + 1) + assignation x n + comparaison x n + return
= c x (n + 1) + c x n + c x n + cAussi, comme la durée de c n’est pas vraiment définie et qu’elle influe peu sur l’augmentation du temps d’exécution relativement à l’augmentation en taille de l’input, on peut tout simplement ignorer les constantes. Dès lors, notre temps d’exécution T(n) est égal à 3n + 1.
Par ailleurs, pour simplifier les calculs, la boucle en elle-même est souvent comptée comme une seule opération, voir ignorée, auquel cas, notre complexité n’est plus que T(n) = n + 1. Nous verrons que dès lors qu’il s’agit de mesurer le comportement de T(n) pour des valeurs de n très grandes, ces simplifications n’ont que peu d’importance.
Prenons un autre exemple. Une fonction permettant de trier un tableau dans l’ordre croissant, communément appelé selection sort.
function selectionSort(list) {
// on loop sur chaque élément du tableau
for (let i = 0; i < list.length; i++) {
let minJ = i; // on note l'index courant
// pour tous les éléments restants du tableau, trouver le plus petit
for (let j = i + 1; j < list.length; j++) {
// si l'élément à l'index i + 1 est inférieur à l'élément à i, on le mémorise
if (list[j] < list[minJ]) {
minJ = j;
}
}
const oldVal = list[i];
const newVal = list[minJ];
// échange des valeurs si différentes
if (oldVal !== newVal) {
list[i] = newVal;
list[minJ] = oldVal;
}
}
return list;
}Si vous passez un array à cette fonction, l’array retourné contiendra les valeurs triées. Le premier for tourne n fois et exécute six opérations par boucle : cinq assignations et une comparaison, soit T(n) = 6n.
Le second for exécute une comparaison et une assignation, soit deux opérations. À chaque tour de la première boucle, la seconde est exécutée, mais elle loop à chaque fois sur un élément de moins. On peut donc représenter le nombre total par la somme des éléments suivants :
- n - 1
- n - 2
- n - 3
- …
- n - (n - 1)
La formule permettant de représenter une somme de un à n est ((n - 1) x n) / 2 = (n² - n) / 2. Vous trouverez plus de détail concernant cette formule sur Wikipedia, le but n’est pas ici d’en apporter la preuve mathématique.
La seconde boucle a donc T(n) = ((n² - n) / 2) x 2 = n² - n. La complexité T(n) de notre fonction selectionSort est donc T(n) = n² - n + 6n - 6 = n² + 5n - 6.
Grâce à notre formule, nous pouvons déjà concrètement évaluer l’augmentation relative du temps d’exécution en fonction de notre input. Il s’agit d’une simple division.
Estimer l’augmentation du temps
Si nous donnons une valeur à n, la valeur absolue résultant du calcul de l’équation n’a pas vraiment de sens. Cependant, cela nous permet d’évaluer l’augmentation relative du temps de calcul nécessaire pour deux sets de données. Par exemple, pour T(10) = 10² + 5 * 10 - 6 = 144.
144 n’a pas vraiment de sens en soit, mais on peut le comparer à T(10000) = 10000² + 5 x 10000 - 6 = 100 050 006. T(10000) / T(10) = 100050006 / 144 = 694 791,70833 et on peut affirmer que le temps d’exécution de notre fonction augmente considérablement lorsque l’input augmente.
Ainsi, pour pour un input de taille 10000, la fonction mettra presque 700 000 fois plus de temps à s’exécuter que pour un input de taille 10.
Regardons les valeurs pour différentes tailles d’input :
8² + 5 x 8 - 6 = 98
16² + 5 x 16 - 6 = 330
–> T(16) / T(8) = 3,3673
32² + 5 x 32 - 6 = 1178
64² + 5 x 64 - 6 = 4410
–> T(64) / T(32) = 3,7436
Ici, nous doublons la valeur de n, plus les valeurs sont grandes, plus nous nous rapprochons de 4. Ainsi, nous pouvons estimer que la temps d’exécution est quatre fois plus important lorsque nous passons d’un input de cinquante mille à cent mille ou de un million à deux millions.
Nous réalisons que plus la valeur de l’input est grand, moins les constantes ont d’impact sur le résultat. Par ailleurs, pour simplifier encore l’équation, on peut approximer la résultat en ne conservant que son terme dominant, c’est à dire le terme qui a le facteur de croissance le plus important.
Dans notre exemple, l’équation simplifiée revient à dire T(n) ≈ n². Cette valeur est bien entendu une approximation, mais lorsque l’ordre de grandeur de n est important, approchant de l’asymptote, l’impact des autres termes de l’équation est négligeable.
Notation Big-O
La notation Big-O permet de représenter la complexité algorithmique en ne prenant en compte que le terme dominant. Techniquement, on étudie le comportement asymptotique de l’équation, dès lors, seul le terme dominant importe.
Cette notation permet de facilement ranger les algorithmes dans différentes classes de complexité et ainsi de facilement être en mesure de les comparer.
Un peu de maths
Avant d’expliquer dans le détail chacune des complexités couramment rencontrées, je pense qu’il peut être judicieux de rappeler quelques notions mathématiques.
En mathématiques, le logarithme de base b d’un nombre réel strictement positif est la puissance à laquelle il faut élever la base b pour obtenir ce nombre.
Le logarithme de base b s’écrit donc log.b(n). Voyons quelques exemples :
- log.10(10) = 1, car 10¹ = 10
- log.10(1000) = 3, car 10³ = 1000
- log.2(256) = 8, car 2⁸ = 256
Dans le calcul de complexité algorithmique, la plupart du temps la base n’est pas précisée mais il s’agit de base binaire, donc log.2(n).
Il y a une autre notation que vous ignorez peut-être : n! ; il s’agit de la factorielle.
En mathématiques, la factorielle d’un entier naturel n est le produit des nombres entiers strictement positifs inférieurs ou égaux à n.
Voici quelques exemples afin que vous puissiez bien vous représenter de quoi il s’agit.
- 1! = 1
- 2! = 1 × 2 = 2
- 3! = 1 × 2 × 3 = 6
- 4! = 1 × 2 × 3 × 4 = 24
- 10! = 1 × 2 × 3 × 4 × 5 × 6 × 7 × 8 × 9 × 10 = 3 628 800
Complexités usuelles
Voici un petit graphique des classes de complexité les plus courantes.
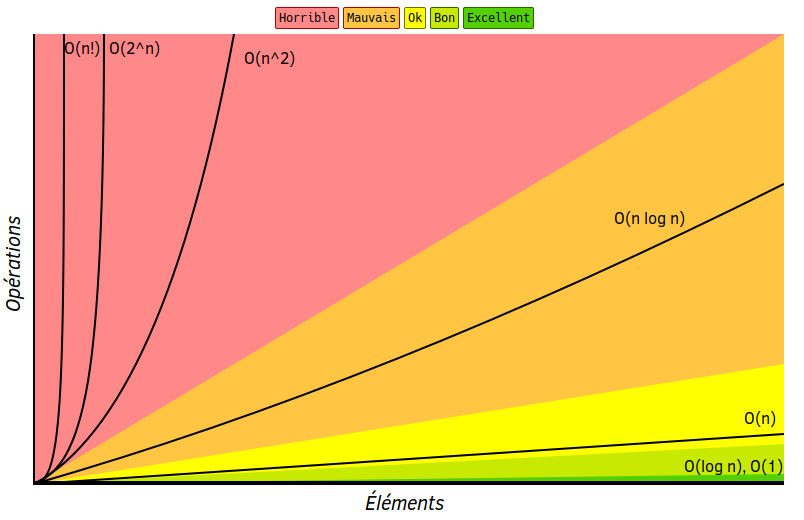
Maintenant que nous comprenons ces différentes formules, l’ordre du moins efficace au plus efficace est évident, nous avons ici :
- O(n!) il n’y a pas moins efficace. Imaginez faire plus de trois millions et demi de calculs pour un input de dix éléments ?
- O(2^n) il s’agit de la complexité exponentielle, ces algorithmes ne sont tout simplement pas réellement runnable tant leur efficacité est mauvaise dès lors que n dépasse quelques dizaines.
- O(n²) on parle de complexité quadratique, c’est une complexité acceptable pour de nombreux algorithmes (comme notre
selectionSort) et l’on reste dans des ordres de grandeurs raisonnables avec des inputs allants jusqu’à plusieurs dizaines de milliers. - O(n log n) on la décrit comme complexité pseudo linéaire. Un algorithme de tri-fusion (fusion de deux tableaux en un seul tableau ordonné) est de complexité pseudo-linéaire.
- O(n) la complexité linéaire est simplement proportionnelle à la grandeur de n, c’est la complexité de notre première fonction de recherche.
- O(log n) la complexité logarithmique (en base 2), c’est par exemple la complexité d’un algo de binary search.
- O(1) le temps constant, est difficilement battable puisque le temps d’exécution est toujours le même, indépendamment de la valeur d’entrée. Déterminer si un nombre est pair ou impair par exemple ou s’il est divisible par un autre.
Les complexités factorielle et exponentielle sont à éviter à tout prix ! Mis à part quelques algorithmes bien spécifiques pour lesquels il n’est pas possible de faire autrement, comme le problème du voyageur de commerce, ces complexités ne sont pas acceptables. Pour les problèmes dont la complexité est telle qu’ils ne sont résolubles que par un algorithme factoriel ou exponentiel, on parle de problème NP-complet.
Nous avons vu ici les complexités les plus communes, la Wikipedia anglaise en liste quelques autres. Vous pouvez aussi vous référer à cet article [EN], lequel référence les complexités d’algorithmes courants ainsi que des opérations sur diverses structures de données.
Complexité en espace
Nous avons jusqu’ici parlé de complexité dans le temps. C’est en effet l’indicateur de performance le plus couramment utilisé pour évaluer la performance d’un algorithme. Cependant, tout algorithme utilise deux ressources :
- de la puissance processeur, le temps ;
- de la mémoire, l’espace.
De ce fait, on peut également mesurer la complexité en espace d’un algorithme. On exprime cette complexité comme fonction de la taille d’entrée. On comptera ici les appels de fonctions, les déclarations de variables, etc. En résumé, tout ce qui équivaut à prendre de l’espace mémoire.
Ainsi, notre fonction selectionSort est O(1) car la taille de la mémoire utilisée est fixe et ne dépend pas de la taille d’entrée. En effet, let minJ = i est de taille constante, de même que oldVal et newval et leurs tailles ne dépendent pas de la taille de list.
La plupart du temps, on se focalise plus sur la complexité en temps que la complexité en espace. Cela est du au fait que la mémoire est assez abondante et peut être réutilisée, tandis que le temps n’est pas compressible.
Cependant, sur certains types de problèmes où le besoin en espace mémoire est important, il arrive de devoir faire des compromis. C’est à dire, opter pour un algorithme moins rapide mais ayant une complexité en espace plus faible.
En résumé
La notation Big-O permet de facilement évaluer la performance – dans le temps ou dans l’espace – d’un algorithme. Cela importe peu si vous savez que vous n’aurez pas à traiter d’importants volumes de données, mais dès que vous devez faire face à un volume un temps soit peu plus important, nous avons vu que des complexité de type factorielle ou exponentielle peuvent rapidement s’avérer inutilisable.
Vous êtes donc maintenant en mesure d’évaluer et de comparer différents algorithmes et de choisir le plus performante pour la résolution d’un problème donné.
Commentaires
Rejoignez la discussion !